 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Generation of Time-Frequency Features with application in audio synthesis
Paper and Code
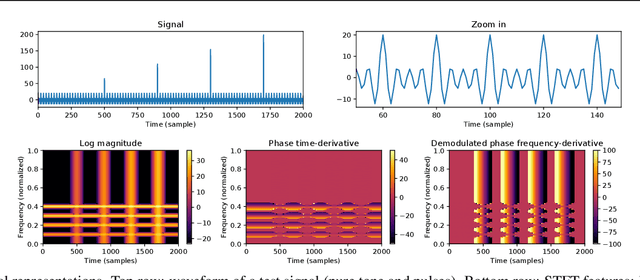

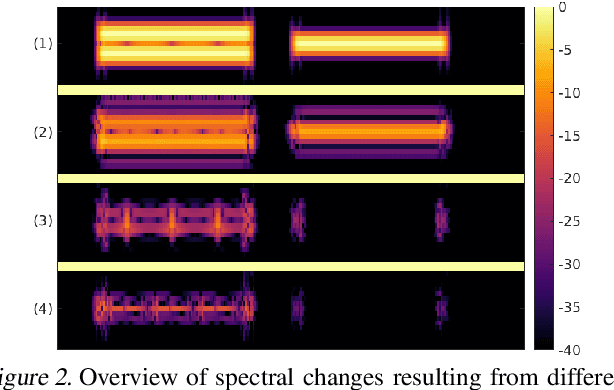
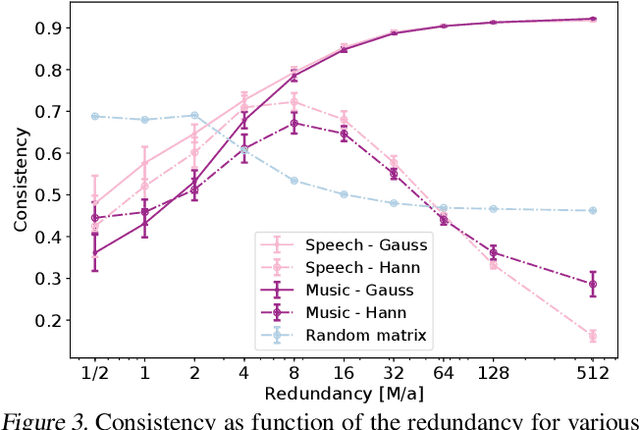
Time-frequency (TF) representations provide powerful and intuitive features for the analysis of time series such as audio. But still, generative modeling of audio in the TF domain is a subtle matter. Consequently, neural audio synthesis widely relies on directly modeling the waveform and previous attempts at unconditionally synthesizing audio from neurally generated TF features still struggle to produce audio at satisfying quality. In this contribution, focusing on the short-time Fourier transform, we discuss the challenges that arise in audio synthesis based on generated TF features and how to overcome them. We demonstrate the potential of deliberate generative TF modeling by training a generative adversarial network (GAN) on short-time Fourier features. We show that our TF-based network was able to outperform the state-of-the-art GAN generating waveform, despite the similar architecture in the two networks.