 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA context encoder for audio inpainting
Paper and Code

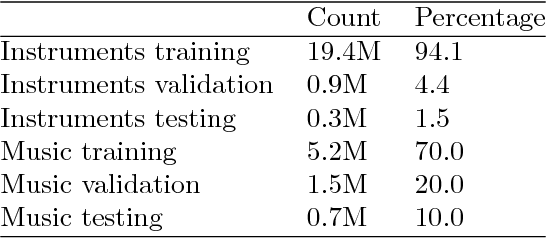
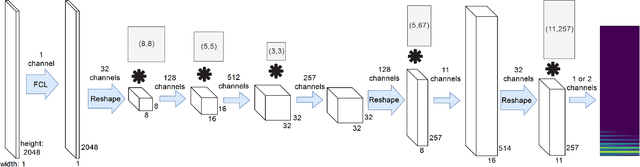
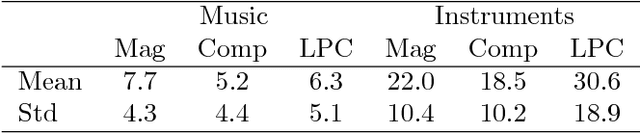
We studied the ability of deep neural networks (DNNs) to restore missing audio content based on its context, a process usually referred to as audio inpainting. We focused on gaps in the range of tens of milliseconds, a condition which has not received much attention yet. The proposed DNN structure was trained on audio signals containing music and musical instruments, separately, with 64-ms long gaps. The input to the DNN was the context, i.e., the signal surrounding the gap, transformed into time-frequency (TF) coefficients. Two networks were analyzed, a DNN with complex-valued TF coefficient output and another one producing magnitude TF coefficient output, both based on the same network architecture. We found significant differences in the inpainting results between the two DNNs. In particular, we discuss the observation that the complex-valued DNN fails to produce reliable results outside the low frequency range. Further, our results were compared to those obtained from a reference method based on linear predictive coding (LPC). For instruments, our DNNs were not able to match the performance of reference method, although the magnitude network provided good results as well. For music, however, our magnitude DNN significantly outperformed the reference method, demonstrating a generally good usability of the proposed DNN structure for inpainting complex audio signals like music. This paves the road towards future, more sophisticated audio inpainting approaches based on DNNs.