 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocling: An Efficient Open-Source Toolkit for AI-driven Document Conversion
Jan 27, 2025



We introduce Docling, an easy-to-use, self-contained, MIT-licensed, open-source toolkit for document conversion, that can parse several types of popular document formats into a unified, richly structured representation. It is powered by state-of-the-art specialized AI models for layout analysis (DocLayNet) and table structure recognition (TableFormer), and runs efficiently on commodity hardware in a small resource budget. Docling is released as a Python package and can be used as a Python API or as a CLI tool. Docling's modular architecture and efficient document representation make it easy to implement extensions, new features, models, and customizations. Docling has been already integrated in other popular open-source frameworks (e.g., LangChain, LlamaIndex, spaCy), making it a natural fit for the processing of documents and the development of high-end applications. The open-source community has fully engaged in using, promoting, and developing for Docling, which gathered 10k stars on GitHub in less than a month and was reported as the No. 1 trending repository in GitHub worldwide in November 2024.
Docling Technical Report
Aug 19, 2024



This technical report introduces Docling, an easy to use, self-contained, MIT-licensed open-source package for PDF document conversion. It is powered by state-of-the-art specialized AI models for layout analysis (DocLayNet) and table structure recognition (TableFormer), and runs efficiently on commodity hardware in a small resource budget. The code interface allows for easy extensibility and addition of new features and models.
Statements: Universal Information Extraction from Tables with Large Language Models for ESG KPIs
Jun 27, 2024Environment, Social, and Governance (ESG) KPIs assess an organization's performance on issues such as climate change, greenhouse gas emissions, water consumption, waste management, human rights, diversity, and policies. ESG reports convey this valuable quantitative information through tables. Unfortunately, extracting this information is difficult due to high variability in the table structure as well as content. We propose Statements, a novel domain agnostic data structure for extracting quantitative facts and related information. We propose translating tables to statements as a new supervised deep-learning universal information extraction task. We introduce SemTabNet - a dataset of over 100K annotated tables. Investigating a family of T5-based Statement Extraction Models, our best model generates statements which are 82% similar to the ground-truth (compared to baseline of 21%). We demonstrate the advantages of statements by applying our model to over 2700 tables from ESG reports. The homogeneous nature of statements permits exploratory data analysis on expansive information found in large collections of ESG reports.
INDUS: Effective and Efficient Language Models for Scientific Applications
May 17, 2024
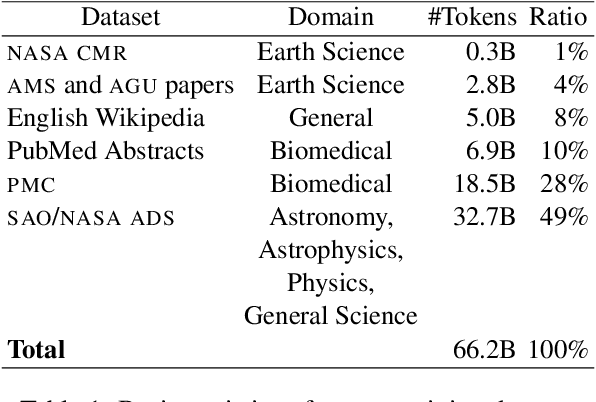
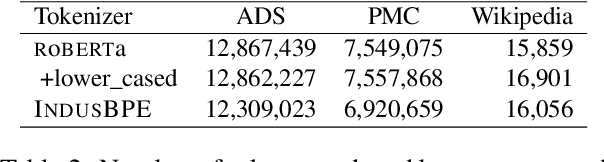

Large language models (LLMs) trained on general domain corpora showed remarkable results on natural language processing (NLP) tasks. However, previous research demonstrated LLMs trained using domain-focused corpora perform better on specialized tasks. Inspired by this pivotal insight, we developed INDUS, a comprehensive suite of LLMs tailored for the Earth science, biology, physics, heliophysics, planetary sciences and astrophysics domains and trained using curated scientific corpora drawn from diverse data sources. The suite of models include: (1) an encoder model trained using domain-specific vocabulary and corpora to address natural language understanding tasks, (2) a contrastive-learning-based general text embedding model trained using a diverse set of datasets drawn from multiple sources to address information retrieval tasks and (3) smaller versions of these models created using knowledge distillation techniques to address applications which have latency or resource constraints. We also created three new scientific benchmark datasets namely, CLIMATE-CHANGE-NER (entity-recognition), NASA-QA (extractive QA) and NASA-IR (IR) to accelerate research in these multi-disciplinary fields. Finally, we show that our models outperform both general-purpose encoders (RoBERTa) and existing domain-specific encoders (SciBERT) on these new tasks as well as existing benchmark tasks in the domains of interest.
Otter-Knowledge: benchmarks of multimodal knowledge graph representation learning from different sources for drug discovery
Jun 23, 2023Recent research in representation learning utilizes large databases of proteins or molecules to acquire knowledge of drug and protein structures through unsupervised learning techniques. These pre-trained representations have proven to significantly enhance the accuracy of subsequent tasks, such as predicting the affinity between drugs and target proteins. In this study, we demonstrate that by incorporating knowledge graphs from diverse sources and modalities into the sequences or SMILES representation, we can further enrich the representation and achieve state-of-the-art results on established benchmark datasets. We provide preprocessed and integrated data obtained from 7 public sources, which encompass over 30M triples. Additionally, we make available the pre-trained models based on this data, along with the reported outcomes of their performance on three widely-used benchmark datasets for drug-target binding affinity prediction found in the Therapeutic Data Commons (TDC) benchmarks. Additionally, we make the source code for training models on benchmark datasets publicly available. Our objective in releasing these pre-trained models, accompanied by clean data for model pretraining and benchmark results, is to encourage research in knowledge-enhanced representation learning.
Delivering Document Conversion as a Cloud Service with High Throughput and Responsiveness
Jun 01, 2022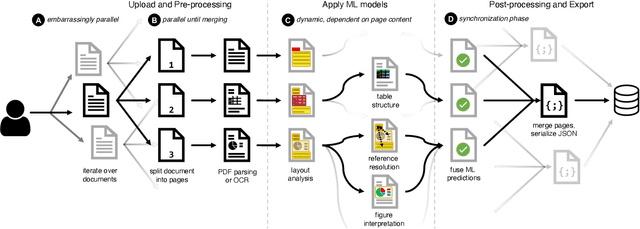
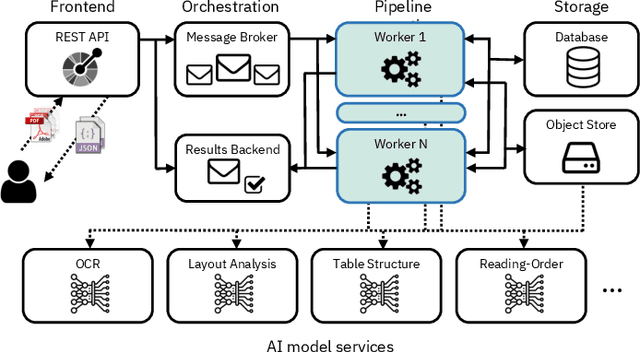
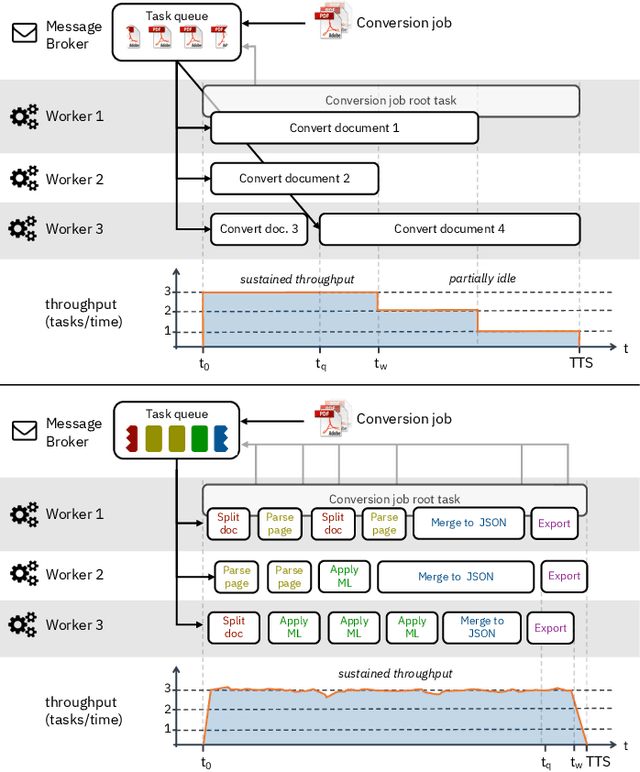
Document understanding is a key business process in the data-driven economy since documents are central to knowledge discovery and business insights. Converting documents into a machine-processable format is a particular challenge here due to their huge variability in formats and complex structure. Accordingly, many algorithms and machine-learning methods emerged to solve particular tasks such as Optical Character Recognition (OCR), layout analysis, table-structure recovery, figure understanding, etc. We observe the adoption of such methods in document understanding solutions offered by all major cloud providers. Yet, publications outlining how such services are designed and optimized to scale in the cloud are scarce. In this paper, we focus on the case of document conversion to illustrate the particular challenges of scaling a complex data processing pipeline with a strong reliance on machine-learning methods on cloud infrastructure. Our key objective is to achieve high scalability and responsiveness for different workload profiles in a well-defined resource budget. We outline the requirements, design, and implementation choices of our document conversion service and reflect on the challenges we faced. Evidence for the scaling behavior and resource efficiency is provided for two alternative workload distribution strategies and deployment configurations. Our best-performing method achieves sustained throughput of over one million PDF pages per hour on 3072 CPU cores across 192 nodes.