 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOtter-Knowledge: benchmarks of multimodal knowledge graph representation learning from different sources for drug discovery
Jun 23, 2023Recent research in representation learning utilizes large databases of proteins or molecules to acquire knowledge of drug and protein structures through unsupervised learning techniques. These pre-trained representations have proven to significantly enhance the accuracy of subsequent tasks, such as predicting the affinity between drugs and target proteins. In this study, we demonstrate that by incorporating knowledge graphs from diverse sources and modalities into the sequences or SMILES representation, we can further enrich the representation and achieve state-of-the-art results on established benchmark datasets. We provide preprocessed and integrated data obtained from 7 public sources, which encompass over 30M triples. Additionally, we make available the pre-trained models based on this data, along with the reported outcomes of their performance on three widely-used benchmark datasets for drug-target binding affinity prediction found in the Therapeutic Data Commons (TDC) benchmarks. Additionally, we make the source code for training models on benchmark datasets publicly available. Our objective in releasing these pre-trained models, accompanied by clean data for model pretraining and benchmark results, is to encourage research in knowledge-enhanced representation learning.
Neural Unification for Logic Reasoning over Natural Language
Sep 17, 2021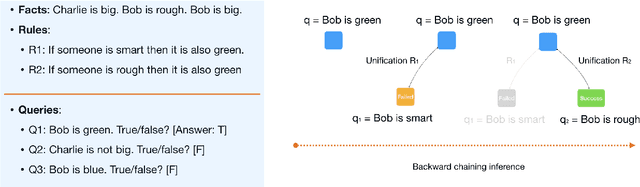
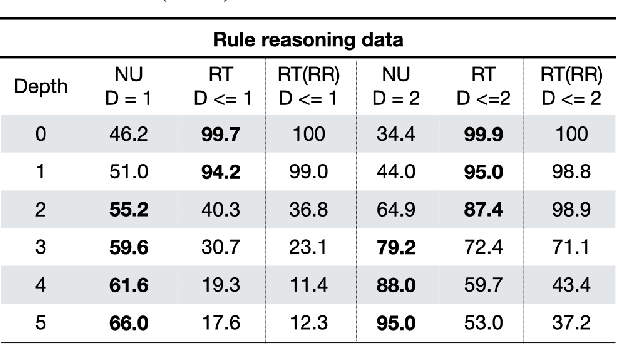
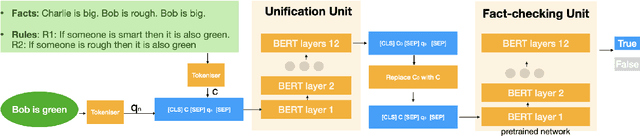

Automated Theorem Proving (ATP) deals with the development of computer programs being able to show that some conjectures (queries) are a logical consequence of a set of axioms (facts and rules). There exists several successful ATPs where conjectures and axioms are formally provided (e.g. formalised as First Order Logic formulas). Recent approaches, such as (Clark et al., 2020), have proposed transformer-based architectures for deriving conjectures given axioms expressed in natural language (English). The conjecture is verified through a binary text classifier, where the transformers model is trained to predict the truth value of a conjecture given the axioms. The RuleTaker approach of (Clark et al., 2020) achieves appealing results both in terms of accuracy and in the ability to generalize, showing that when the model is trained with deep enough queries (at least 3 inference steps), the transformers are able to correctly answer the majority of queries (97.6%) that require up to 5 inference steps. In this work we propose a new architecture, namely the Neural Unifier, and a relative training procedure, which achieves state-of-the-art results in term of generalisation, showing that mimicking a well-known inference procedure, the backward chaining, it is possible to answer deep queries even when the model is trained only on shallow ones. The approach is demonstrated in experiments using a diverse set of benchmark data.