 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges in Guardrailing Large Language Models for Science
Nov 12, 2024The rapid development in large language models (LLMs) has transformed the landscape of natural language processing and understanding (NLP/NLU), offering significant benefits across various domains. However, when applied to scientific research, these powerful models exhibit critical failure modes related to scientific integrity and trustworthiness. Existing general-purpose LLM guardrails are insufficient to address these unique challenges in the scientific domain. We provide comprehensive guidelines for deploying LLM guardrails in the scientific domain. We identify specific challenges -- including time sensitivity, knowledge contextualization, conflict resolution, and intellectual property concerns -- and propose a guideline framework for the guardrails that can align with scientific needs. These guardrail dimensions include trustworthiness, ethics & bias, safety, and legal aspects. We also outline in detail the implementation strategies that employ white-box, black-box, and gray-box methodologies that can be enforced within scientific contexts.
INDUS: Effective and Efficient Language Models for Scientific Applications
May 17, 2024
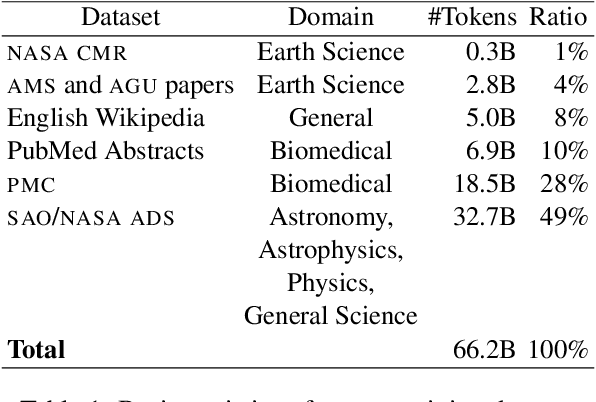
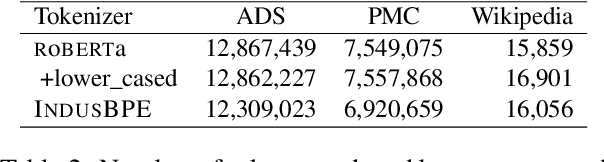

Large language models (LLMs) trained on general domain corpora showed remarkable results on natural language processing (NLP) tasks. However, previous research demonstrated LLMs trained using domain-focused corpora perform better on specialized tasks. Inspired by this pivotal insight, we developed INDUS, a comprehensive suite of LLMs tailored for the Earth science, biology, physics, heliophysics, planetary sciences and astrophysics domains and trained using curated scientific corpora drawn from diverse data sources. The suite of models include: (1) an encoder model trained using domain-specific vocabulary and corpora to address natural language understanding tasks, (2) a contrastive-learning-based general text embedding model trained using a diverse set of datasets drawn from multiple sources to address information retrieval tasks and (3) smaller versions of these models created using knowledge distillation techniques to address applications which have latency or resource constraints. We also created three new scientific benchmark datasets namely, CLIMATE-CHANGE-NER (entity-recognition), NASA-QA (extractive QA) and NASA-IR (IR) to accelerate research in these multi-disciplinary fields. Finally, we show that our models outperform both general-purpose encoders (RoBERTa) and existing domain-specific encoders (SciBERT) on these new tasks as well as existing benchmark tasks in the domains of interest.
Leveraging Citizen Science for Flood Extent Detection using Machine Learning Benchmark Dataset
Nov 15, 2023

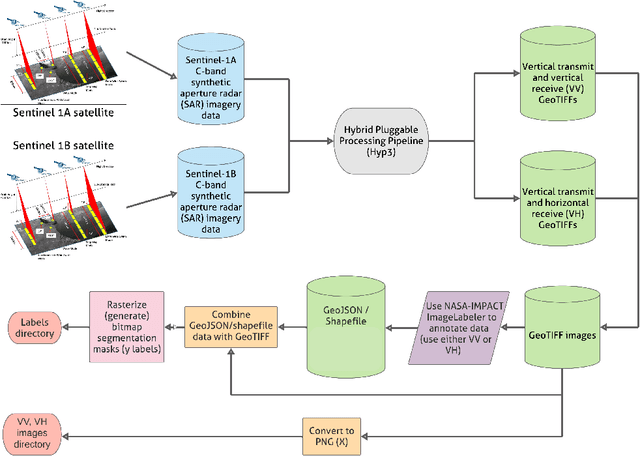

Accurate detection of inundated water extents during flooding events is crucial in emergency response decisions and aids in recovery efforts. Satellite Remote Sensing data provides a global framework for detecting flooding extents. Specifically, Sentinel-1 C-Band Synthetic Aperture Radar (SAR) imagery has proven to be useful in detecting water bodies due to low backscatter of water features in both co-polarized and cross-polarized SAR imagery. However, increased backscatter can be observed in certain flooded regions such as presence of infrastructure and trees - rendering simple methods such as pixel intensity thresholding and time-series differencing inadequate. Machine Learning techniques has been leveraged to precisely capture flood extents in flooded areas with bumps in backscatter but needs high amounts of labelled data to work desirably. Hence, we created a labeled known water body extent and flooded area extents during known flooding events covering about 36,000 sq. kilometers of regions within mainland U.S and Bangladesh. Further, We also leveraged citizen science by open-sourcing the dataset and hosting an open competition based on the dataset to rapidly prototype flood extent detection using community generated models. In this paper we present the information about the dataset, the data processing pipeline, a baseline model and the details about the competition, along with discussion on winning approaches. We believe the dataset adds to already existing datasets based on Sentinel-1C SAR data and leads to more robust modeling of flood extents. We also hope the results from the competition pushes the research in flood extent detection further.
Foundation Models for Generalist Geospatial Artificial Intelligence
Nov 08, 2023Significant progress in the development of highly adaptable and reusable Artificial Intelligence (AI) models is expected to have a significant impact on Earth science and remote sensing. Foundation models are pre-trained on large unlabeled datasets through self-supervision, and then fine-tuned for various downstream tasks with small labeled datasets. This paper introduces a first-of-a-kind framework for the efficient pre-training and fine-tuning of foundational models on extensive geospatial data. We have utilized this framework to create Prithvi, a transformer-based geospatial foundational model pre-trained on more than 1TB of multispectral satellite imagery from the Harmonized Landsat-Sentinel 2 (HLS) dataset. Our study demonstrates the efficacy of our framework in successfully fine-tuning Prithvi to a range of Earth observation tasks that have not been tackled by previous work on foundation models involving multi-temporal cloud gap imputation, flood mapping, wildfire scar segmentation, and multi-temporal crop segmentation. Our experiments show that the pre-trained model accelerates the fine-tuning process compared to leveraging randomly initialized weights. In addition, pre-trained Prithvi compares well against the state-of-the-art, e.g., outperforming a conditional GAN model in multi-temporal cloud imputation by up to 5pp (or 5.7%) in the structural similarity index. Finally, due to the limited availability of labeled data in the field of Earth observation, we gradually reduce the quantity of available labeled data for refining the model to evaluate data efficiency and demonstrate that data can be decreased significantly without affecting the model's accuracy. The pre-trained 100 million parameter model and corresponding fine-tuning workflows have been released publicly as open source contributions to the global Earth sciences community through Hugging Face.