 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Citizen Science for Flood Extent Detection using Machine Learning Benchmark Dataset
Nov 15, 2023

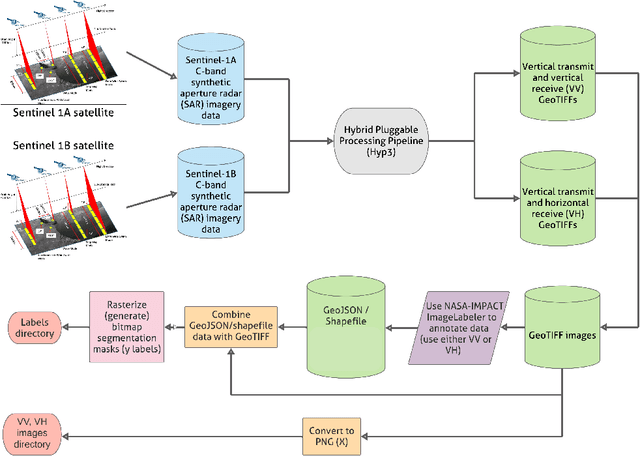

Accurate detection of inundated water extents during flooding events is crucial in emergency response decisions and aids in recovery efforts. Satellite Remote Sensing data provides a global framework for detecting flooding extents. Specifically, Sentinel-1 C-Band Synthetic Aperture Radar (SAR) imagery has proven to be useful in detecting water bodies due to low backscatter of water features in both co-polarized and cross-polarized SAR imagery. However, increased backscatter can be observed in certain flooded regions such as presence of infrastructure and trees - rendering simple methods such as pixel intensity thresholding and time-series differencing inadequate. Machine Learning techniques has been leveraged to precisely capture flood extents in flooded areas with bumps in backscatter but needs high amounts of labelled data to work desirably. Hence, we created a labeled known water body extent and flooded area extents during known flooding events covering about 36,000 sq. kilometers of regions within mainland U.S and Bangladesh. Further, We also leveraged citizen science by open-sourcing the dataset and hosting an open competition based on the dataset to rapidly prototype flood extent detection using community generated models. In this paper we present the information about the dataset, the data processing pipeline, a baseline model and the details about the competition, along with discussion on winning approaches. We believe the dataset adds to already existing datasets based on Sentinel-1C SAR data and leads to more robust modeling of flood extents. We also hope the results from the competition pushes the research in flood extent detection further.
Data optimization for large batch distributed training of deep neural networks
Dec 18, 2020

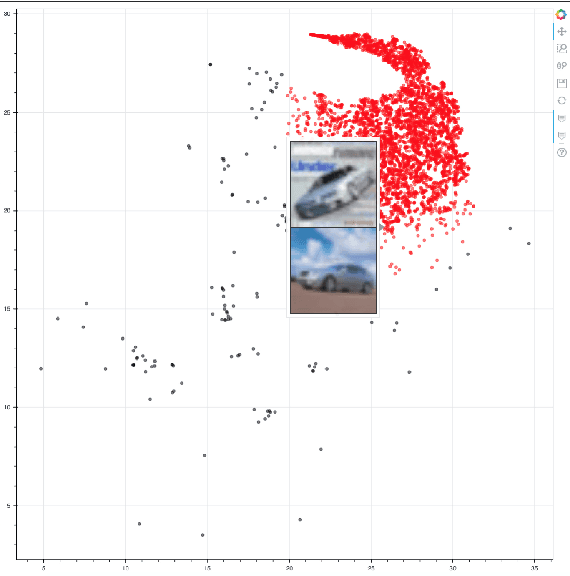
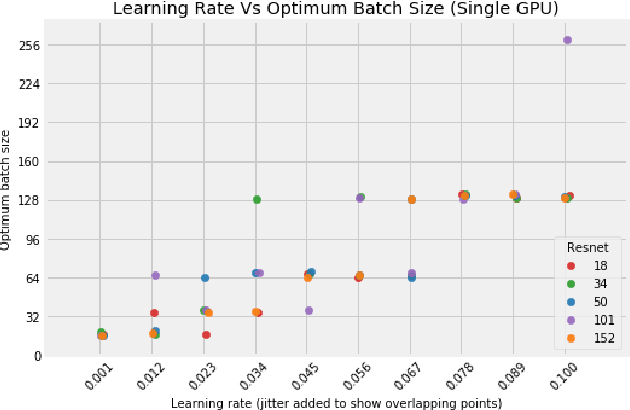
Distributed training in deep learning (DL) is common practice as data and models grow. The current practice for distributed training of deep neural networks faces the challenges of communication bottlenecks when operating at scale, and model accuracy deterioration with an increase in global batch size. Present solutions focus on improving message exchange efficiency as well as implementing techniques to tweak batch sizes and models in the training process. The loss of training accuracy typically happens because the loss function gets trapped in a local minima. We observe that the loss landscape minimization is shaped by both the model and training data and propose a data optimization approach that utilizes machine learning to implicitly smooth out the loss landscape resulting in fewer local minima. Our approach filters out data points which are less important to feature learning, enabling us to speed up the training of models on larger batch sizes to improved accuracy.