 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData optimization for large batch distributed training of deep neural networks
Paper and Code
Dec 18, 2020

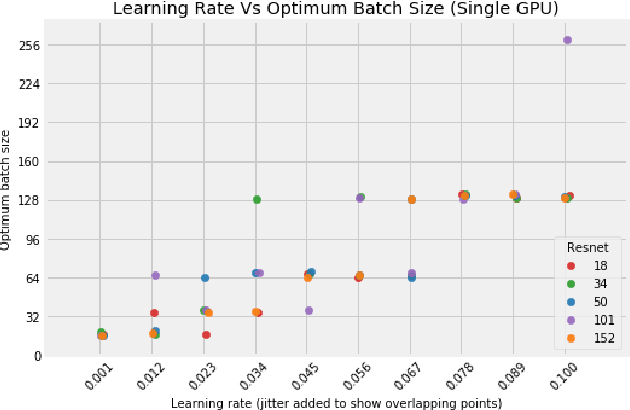
Distributed training in deep learning (DL) is common practice as data and models grow. The current practice for distributed training of deep neural networks faces the challenges of communication bottlenecks when operating at scale, and model accuracy deterioration with an increase in global batch size. Present solutions focus on improving message exchange efficiency as well as implementing techniques to tweak batch sizes and models in the training process. The loss of training accuracy typically happens because the loss function gets trapped in a local minima. We observe that the loss landscape minimization is shaped by both the model and training data and propose a data optimization approach that utilizes machine learning to implicitly smooth out the loss landscape resulting in fewer local minima. Our approach filters out data points which are less important to feature learning, enabling us to speed up the training of models on larger batch sizes to improved accuracy.