 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Synthetic Environments and Reward Networks for Reinforcement Learning
Feb 06, 2022


We introduce Synthetic Environments (SEs) and Reward Networks (RNs), represented by neural networks, as proxy environment models for training Reinforcement Learning (RL) agents. We show that an agent, after being trained exclusively on the SE, is able to solve the corresponding real environment. While an SE acts as a full proxy to a real environment by learning about its state dynamics and rewards, an RN is a partial proxy that learns to augment or replace rewards. We use bi-level optimization to evolve SEs and RNs: the inner loop trains the RL agent, and the outer loop trains the parameters of the SE / RN via an evolution strategy. We evaluate our proposed new concept on a broad range of RL algorithms and classic control environments. In a one-to-one comparison, learning an SE proxy requires more interactions with the real environment than training agents only on the real environment. However, once such an SE has been learned, we do not need any interactions with the real environment to train new agents. Moreover, the learned SE proxies allow us to train agents with fewer interactions while maintaining the original task performance. Our empirical results suggest that SEs achieve this result by learning informed representations that bias the agents towards relevant states. Moreover, we find that these proxies are robust against hyperparameter variation and can also transfer to unseen agents.
Winning solutions and post-challenge analyses of the ChaLearn AutoDL challenge 2019
Jan 11, 2022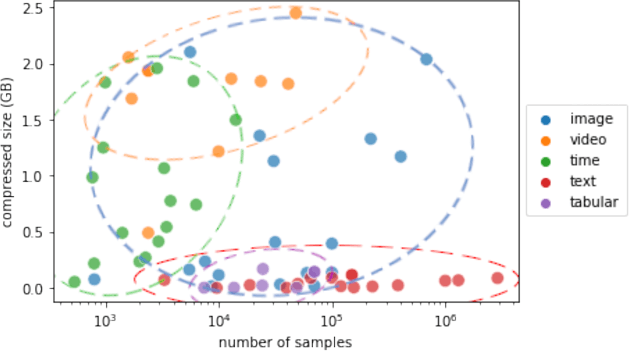
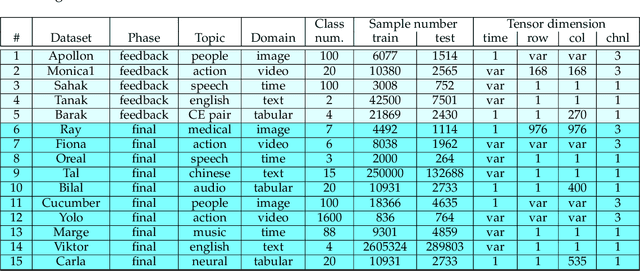
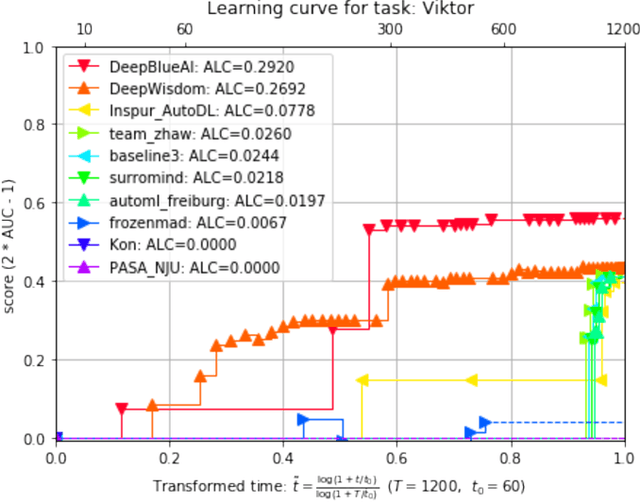
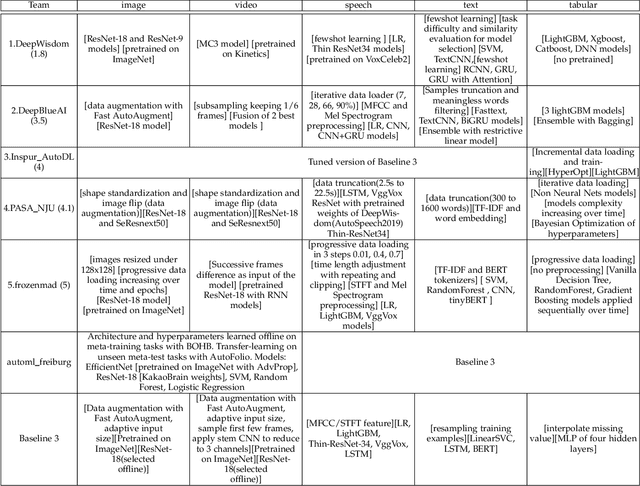
This paper reports the results and post-challenge analyses of ChaLearn's AutoDL challenge series, which helped sorting out a profusion of AutoML solutions for Deep Learning (DL) that had been introduced in a variety of settings, but lacked fair comparisons. All input data modalities (time series, images, videos, text, tabular) were formatted as tensors and all tasks were multi-label classification problems. Code submissions were executed on hidden tasks, with limited time and computational resources, pushing solutions that get results quickly. In this setting, DL methods dominated, though popular Neural Architecture Search (NAS) was impractical. Solutions relied on fine-tuned pre-trained networks, with architectures matching data modality. Post-challenge tests did not reveal improvements beyond the imposed time limit. While no component is particularly original or novel, a high level modular organization emerged featuring a "meta-learner", "data ingestor", "model selector", "model/learner", and "evaluator". This modularity enabled ablation studies, which revealed the importance of (off-platform) meta-learning, ensembling, and efficient data management. Experiments on heterogeneous module combinations further confirm the (local) optimality of the winning solutions. Our challenge legacy includes an ever-lasting benchmark (http://autodl.chalearn.org), the open-sourced code of the winners, and a free "AutoDL self-service".
* The first three authors contributed equally; This is only a draft version
Learning Synthetic Environments for Reinforcement Learning with Evolution Strategies
Feb 08, 2021
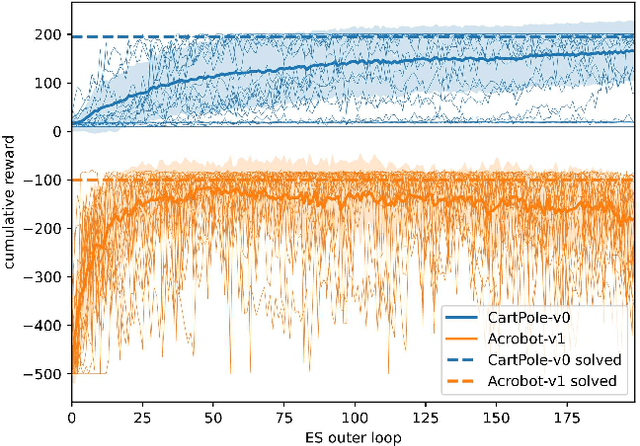
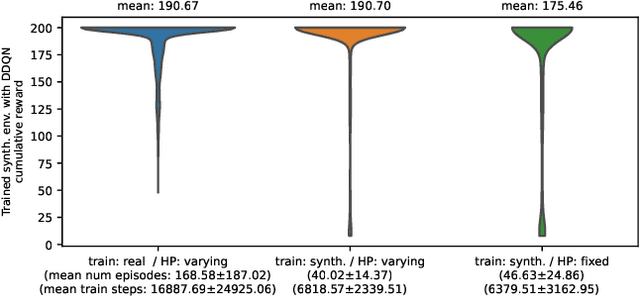
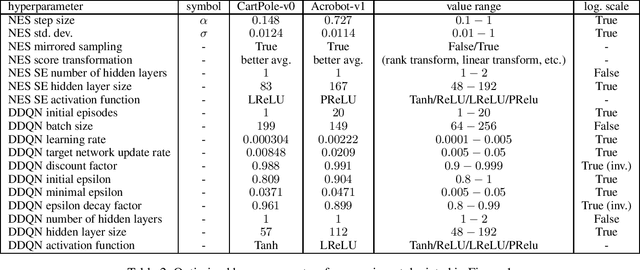
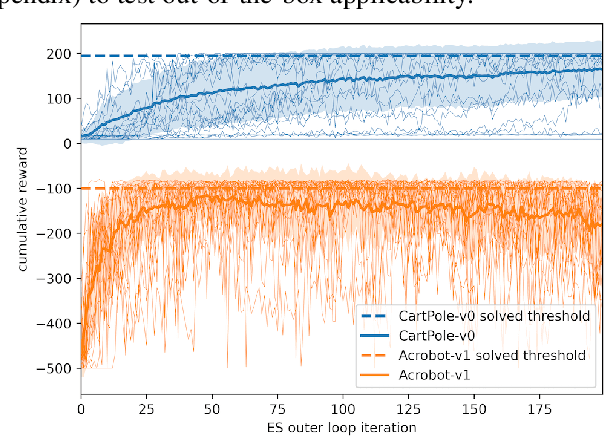
This work explores learning agent-agnostic synthetic environments (SEs) for Reinforcement Learning. SEs act as a proxy for target environments and allow agents to be trained more efficiently than when directly trained on the target environment. We formulate this as a bi-level optimization problem and represent an SE as a neural network. By using Natural Evolution Strategies and a population of SE parameter vectors, we train agents in the inner loop on evolving SEs while in the outer loop we use the performance on the target task as a score for meta-updating the SE population. We show empirically that our method is capable of learning SEs for two discrete-action-space tasks (CartPole-v0 and Acrobot-v1) that allow us to train agents more robustly and with up to 60% fewer steps. Not only do we show in experiments with 4000 evaluations that the SEs are robust against hyperparameter changes such as the learning rate, batch sizes and network sizes, we also show that SEs trained with DDQN agents transfer in limited ways to a discrete-action-space version of TD3 and very well to Dueling DDQN.