 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Synthetic Environments for Reinforcement Learning with Evolution Strategies
Paper and Code

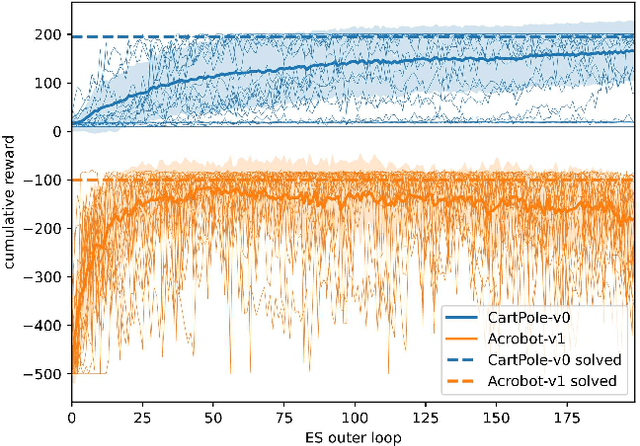
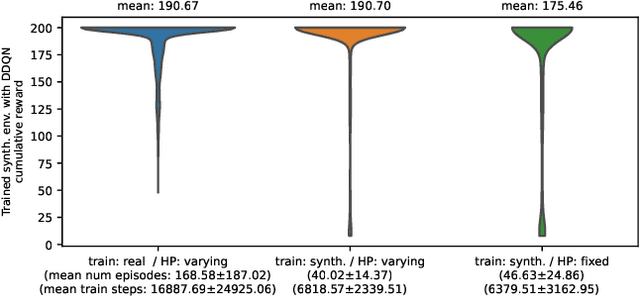
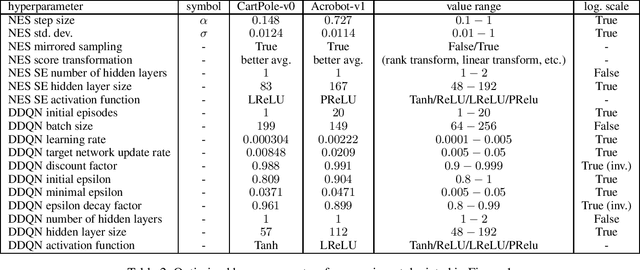
This work explores learning agent-agnostic synthetic environments (SEs) for Reinforcement Learning. SEs act as a proxy for target environments and allow agents to be trained more efficiently than when directly trained on the target environment. We formulate this as a bi-level optimization problem and represent an SE as a neural network. By using Natural Evolution Strategies and a population of SE parameter vectors, we train agents in the inner loop on evolving SEs while in the outer loop we use the performance on the target task as a score for meta-updating the SE population. We show empirically that our method is capable of learning SEs for two discrete-action-space tasks (CartPole-v0 and Acrobot-v1) that allow us to train agents more robustly and with up to 60% fewer steps. Not only do we show in experiments with 4000 evaluations that the SEs are robust against hyperparameter changes such as the learning rate, batch sizes and network sizes, we also show that SEs trained with DDQN agents transfer in limited ways to a discrete-action-space version of TD3 and very well to Dueling DDQN.