 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Importance of Hyperparameters and Data Augmentation for Self-Supervised Learning
Jul 16, 2022
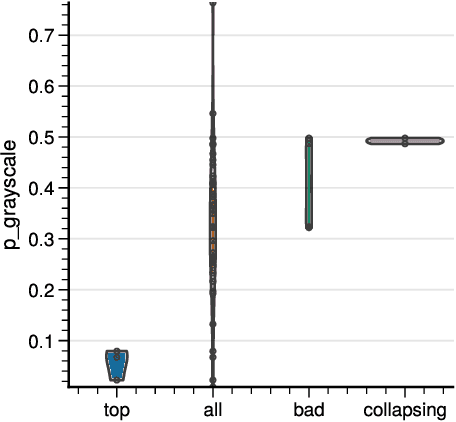
Self-Supervised Learning (SSL) has become a very active area of Deep Learning research where it is heavily used as a pre-training method for classification and other tasks. However, the rapid pace of advancements in this area comes at a price: training pipelines vary significantly across papers, which presents a potentially crucial confounding factor. Here, we show that, indeed, the choice of hyperparameters and data augmentation strategies can have a dramatic impact on performance. To shed light on these neglected factors and help maximize the power of SSL, we hyperparameterize these components and optimize them with Bayesian optimization, showing improvements across multiple datasets for the SimSiam SSL approach. Realizing the importance of data augmentations for SSL, we also introduce a new automated data augmentation algorithm, GroupAugment, which considers groups of augmentations and optimizes the sampling across groups. In contrast to algorithms designed for supervised learning, GroupAugment achieved consistently high linear evaluation accuracy across all datasets we considered. Overall, our results indicate the importance and likely underestimated role of data augmentation for SSL.
Smart(Sampling)Augment: Optimal and Efficient Data Augmentation for Semantic Segmentation
Oct 31, 2021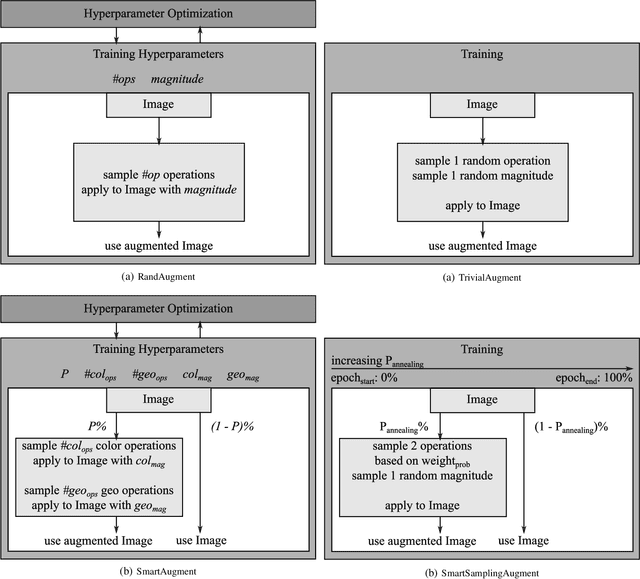

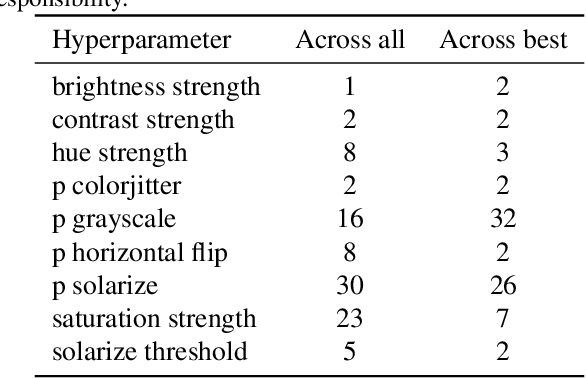
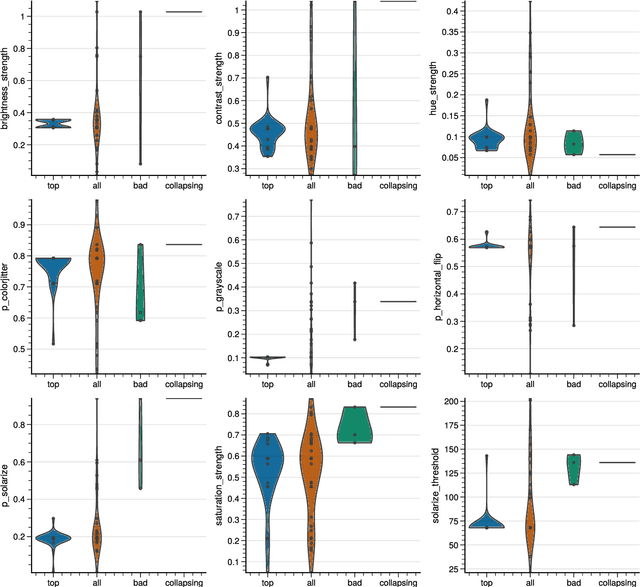
Data augmentation methods enrich datasets with augmented data to improve the performance of neural networks. Recently, automated data augmentation methods have emerged, which automatically design augmentation strategies. Existing work focuses on image classification and object detection, whereas we provide the first study on semantic image segmentation and introduce two new approaches: \textit{SmartAugment} and \textit{SmartSamplingAugment}. SmartAugment uses Bayesian Optimization to search over a rich space of augmentation strategies and achieves a new state-of-the-art performance in all semantic segmentation tasks we consider. SmartSamplingAugment, a simple parameter-free approach with a fixed augmentation strategy competes in performance with the existing resource-intensive approaches and outperforms cheap state-of-the-art data augmentation methods. Further, we analyze the impact, interaction, and importance of data augmentation hyperparameters and perform ablation studies, which confirm our design choices behind SmartAugment and SmartSamplingAugment. Lastly, we will provide our source code for reproducibility and to facilitate further research.
Hyperparameter Transfer Across Developer Adjustments
Oct 25, 2020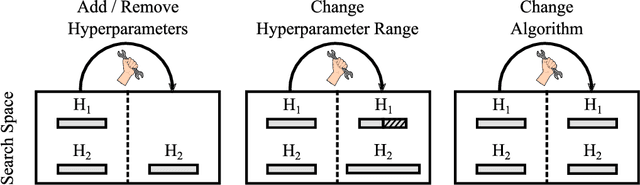

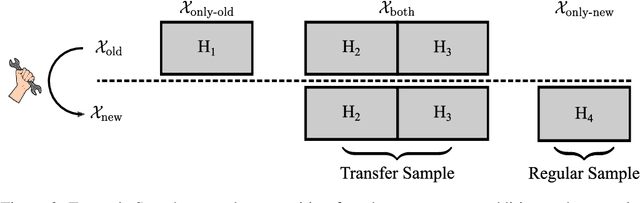
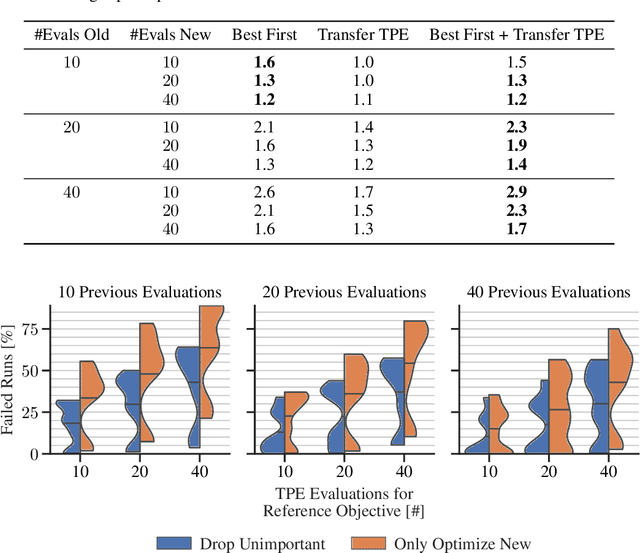
After developer adjustments to a machine learning (ML) algorithm, how can the results of an old hyperparameter optimization (HPO) automatically be used to speedup a new HPO? This question poses a challenging problem, as developer adjustments can change which hyperparameter settings perform well, or even the hyperparameter search space itself. While many approaches exist that leverage knowledge obtained on previous tasks, so far, knowledge from previous development steps remains entirely untapped. In this work, we remedy this situation and propose a new research framework: hyperparameter transfer across adjustments (HT-AA). To lay a solid foundation for this research framework, we provide four simple HT-AA baseline algorithms and eight benchmarks changing various aspects of ML algorithms, their hyperparameter search spaces, and the neural architectures used. The best baseline, on average and depending on the budgets for the old and new HPO, reaches a given performance 1.2--2.6x faster than a prominent HPO algorithm without transfer. As HPO is a crucial step in ML development but requires extensive computational resources, this speedup would lead to faster development cycles, lower costs, and reduced environmental impacts. To make these benefits available to ML developers off-the-shelf and to facilitate future research on HT-AA, we provide python packages for our baselines and benchmarks.