 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Order: Task Sequencing as In-Context Optimization
Mar 15, 2026Task sequencing (TS) is one of the core open problems in Deep Learning, arising in a plethora of real-world domains, from robotic assembly lines to autonomous driving. Unfortunately, prior work has not convincingly demonstrated the generalization ability of meta-learned TS methods to solve new TS problems, given few initial demonstrations. In this paper, we demonstrate that deep neural networks can meta-learn over an infinite prior of synthetically generated TS problems and achieve a few-shot generalization. We meta-learn a transformer-based architecture over datasets of sequencing trajectories generated from a prior distribution that samples sequencing problems as paths in directed graphs. In a large-scale experiment, we provide ample empirical evidence that our meta-learned models discover optimal task sequences significantly quicker than non-meta-learned baselines.
POP: Prior-fitted Optimizer Policies
Feb 17, 2026Optimization refers to the task of finding extrema of an objective function. Classical gradient-based optimizers are highly sensitive to hyperparameter choices. In highly non-convex settings their performance relies on carefully tuned learning rates, momentum, and gradient accumulation. To address these limitations, we introduce POP (Prior-fitted Optimizer Policies), a meta-learned optimizer that predicts coordinate-wise step sizes conditioned on the contextual information provided in the optimization trajectory. Our model is learned on millions of synthetic optimization problems sampled from a novel prior spanning both convex and non-convex objectives. We evaluate POP on an established benchmark including 47 optimization functions of various complexity, where it consistently outperforms first-order gradient-based methods, non-convex optimization approaches (e.g., evolutionary strategies), Bayesian optimization, and a recent meta-learned competitor under matched budget constraints. Our evaluation demonstrates strong generalization capabilities without task-specific tuning.
End-to-End Compression for Tabular Foundation Models
Feb 05, 2026The long-standing dominance of gradient-boosted decision trees for tabular data has recently been challenged by in-context learning tabular foundation models. In-context learning methods fit and predict in one forward pass without parameter updates by leveraging the training data as context for predicting on query test points. While recent tabular foundation models achieve state-of-the-art performance, their transformer architecture based on the attention mechanism has quadratic complexity regarding dataset size, which in turn increases the overhead on training and inference time, and limits the capacity of the models to handle large-scale datasets. In this work, we propose TACO, an end-to-end tabular compression model that compresses the training dataset in a latent space. We test our method on the TabArena benchmark, where our proposed method is up to 94x faster in inference time, while consuming up to 97\% less memory compared to the state-of-the-art tabular transformer architecture, all while retaining performance without significant degradation. Lastly, our method not only scales better with increased dataset sizes, but it also achieves better performance compared to other baselines.
Tabular Data: Is Attention All You Need?
Feb 06, 2024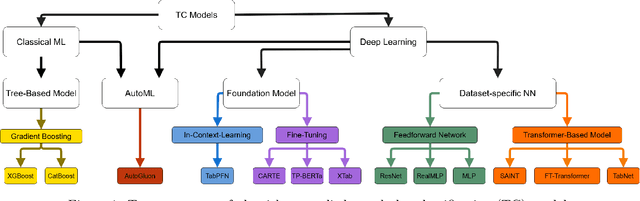
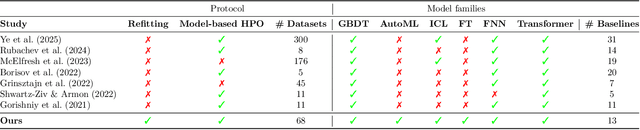
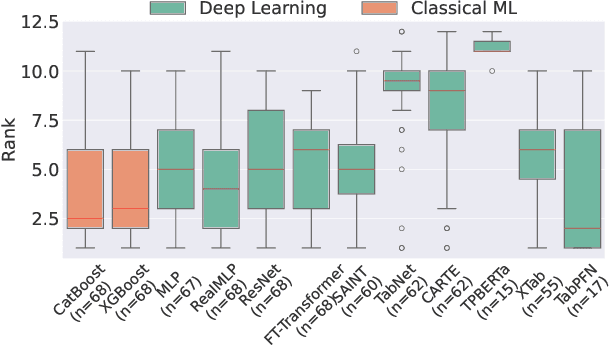
Deep Learning has revolutionized the field of AI and led to remarkable achievements in applications involving image and text data. Unfortunately, there is inconclusive evidence on the merits of neural networks for structured tabular data. In this paper, we introduce a large-scale empirical study comparing neural networks against gradient-boosted decision trees on tabular data, but also transformer-based architectures against traditional multi-layer perceptrons (MLP) with residual connections. In contrast to prior work, our empirical findings indicate that neural networks are competitive against decision trees. Furthermore, we assess that transformer-based architectures do not outperform simpler variants of traditional MLP architectures on tabular datasets. As a result, this paper helps the research and practitioner communities make informed choices on deploying neural networks on future tabular data applications.
Quick-Tune: Quickly Learning Which Pretrained Model to Finetune and How
Jun 11, 2023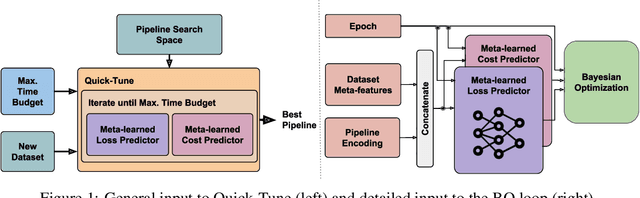
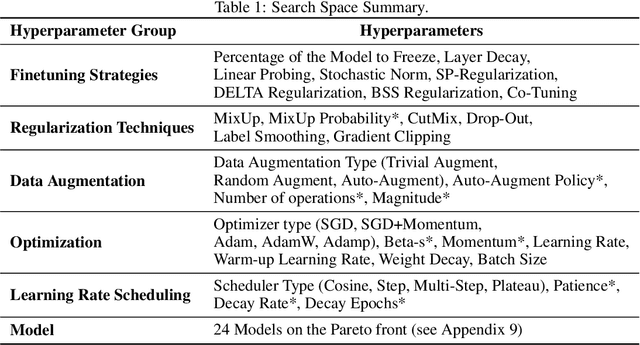
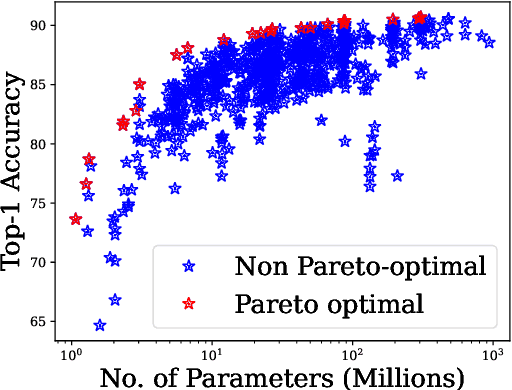

With the ever-increasing number of pretrained models, machine learning practitioners are continuously faced with which pretrained model to use, and how to finetune it for a new dataset. In this paper, we propose a methodology that jointly searches for the optimal pretrained model and the hyperparameters for finetuning it. Our method transfers knowledge about the performance of many pretrained models with multiple hyperparameter configurations on a series of datasets. To this aim, we evaluated over 20k hyperparameter configurations for finetuning 24 pretrained image classification models on 87 datasets to generate a large-scale meta-dataset. We meta-learn a multi-fidelity performance predictor on the learning curves of this meta-dataset and use it for fast hyperparameter optimization on new datasets. We empirically demonstrate that our resulting approach can quickly select an accurate pretrained model for a new dataset together with its optimal hyperparameters.
Breaking the Paradox of Explainable Deep Learning
May 22, 2023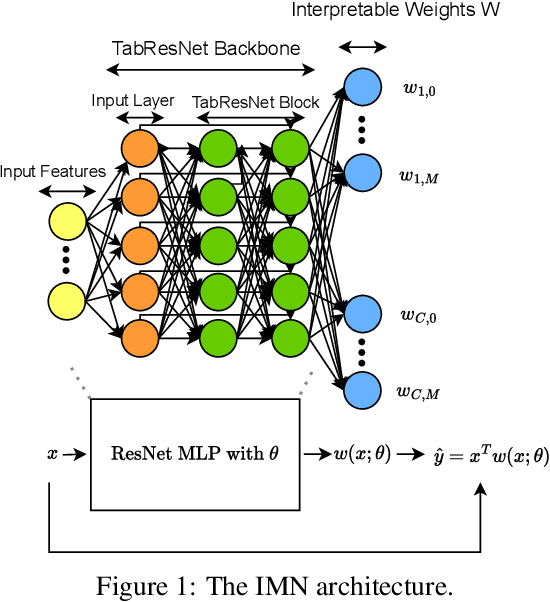

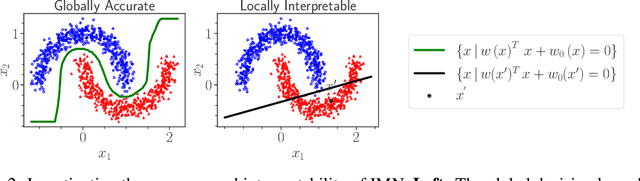
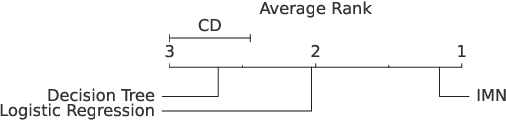
Deep Learning has achieved tremendous results by pushing the frontier of automation in diverse domains. Unfortunately, current neural network architectures are not explainable by design. In this paper, we propose a novel method that trains deep hypernetworks to generate explainable linear models. Our models retain the accuracy of black-box deep networks while offering free lunch explainability by design. Specifically, our explainable approach requires the same runtime and memory resources as black-box deep models, ensuring practical feasibility. Through extensive experiments, we demonstrate that our explainable deep networks are as accurate as state-of-the-art classifiers on tabular data. On the other hand, we showcase the interpretability of our method on a recent benchmark by empirically comparing prediction explainers. The experimental results reveal that our models are not only as accurate as their black-box deep-learning counterparts but also as interpretable as state-of-the-art explanation techniques.
Deep Power Laws for Hyperparameter Optimization
Feb 01, 2023



Hyperparameter optimization is an important subfield of machine learning that focuses on tuning the hyperparameters of a chosen algorithm to achieve peak performance. Recently, there has been a stream of methods that tackle the issue of hyperparameter optimization, however, most of the methods do not exploit the scaling law property of learning curves. In this work, we propose Deep Power Laws (DPL), an ensemble of neural network models conditioned to yield predictions that follow a power-law scaling pattern. Our method dynamically decides which configurations to pause and train incrementally by making use of gray-box evaluations. We compare our method against 7 state-of-the-art competitors on 3 benchmarks related to tabular, image, and NLP datasets covering 57 diverse tasks. Our method achieves the best results across all benchmarks by obtaining the best any-time results compared to all competitors.
Dynamic and Efficient Gray-Box Hyperparameter Optimization for Deep Learning
Feb 20, 2022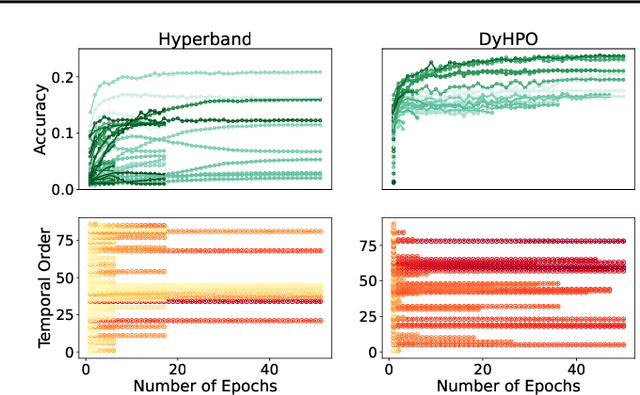
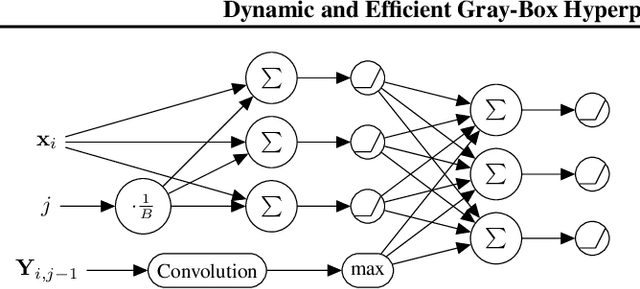
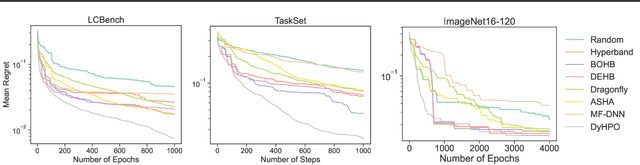
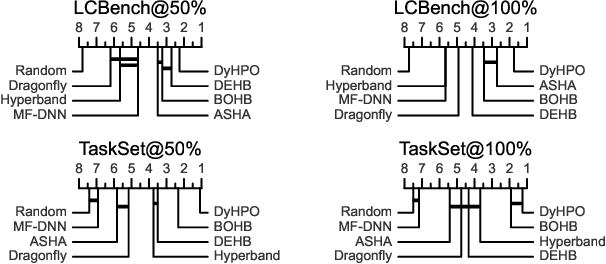
Gray-box hyperparameter optimization techniques have recently emerged as a promising direction for tuning Deep Learning methods. In this work, we introduce DyHPO, a method that learns to dynamically decide which configuration to try next, and for what budget. Our technique is a modification to the classical Bayesian optimization for a gray-box setup. Concretely, we propose a new surrogate for Gaussian Processes that embeds the learning curve dynamics and a new acquisition function that incorporates multi-budget information. We demonstrate the significant superiority of DyHPO against state-of-the-art hyperparameter optimization baselines through large-scale experiments comprising 50 datasets (Tabular, Image, NLP) and diverse neural networks (MLP, CNN/NAS, RNN).
Regularization is all you Need: Simple Neural Nets can Excel on Tabular Data
Jun 21, 2021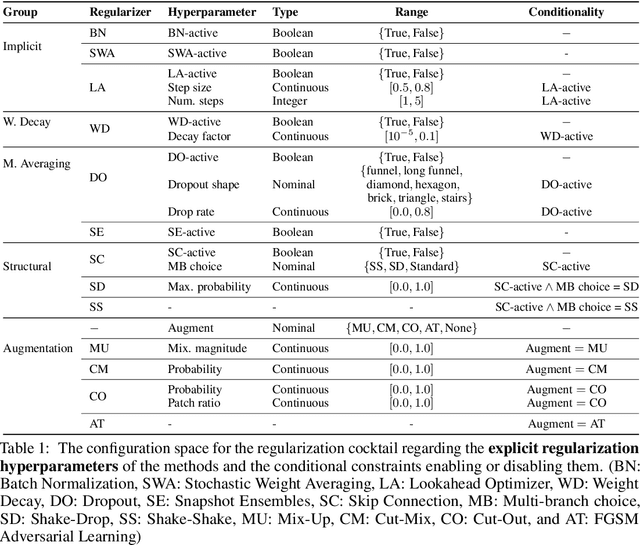
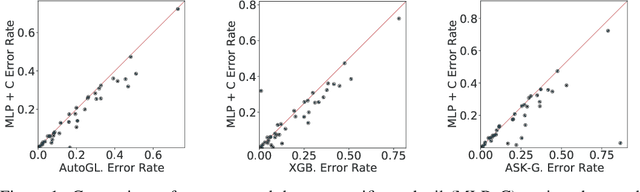

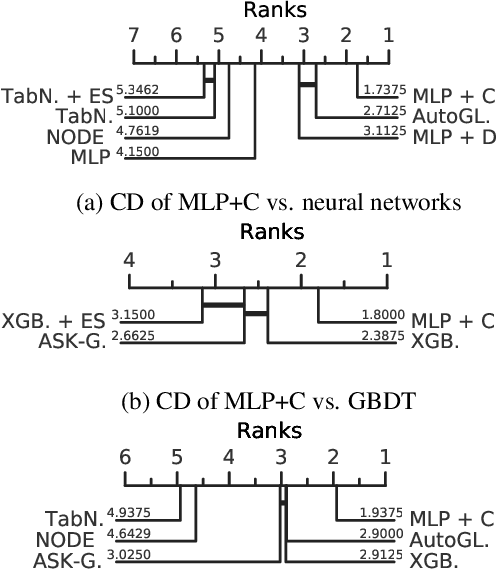
Tabular datasets are the last "unconquered castle" for deep learning, with traditional ML methods like Gradient-Boosted Decision Trees still performing strongly even against recent specialized neural architectures. In this paper, we hypothesize that the key to boosting the performance of neural networks lies in rethinking the joint and simultaneous application of a large set of modern regularization techniques. As a result, we propose regularizing plain Multilayer Perceptron (MLP) networks by searching for the optimal combination/cocktail of 13 regularization techniques for each dataset using a joint optimization over the decision on which regularizers to apply and their subsidiary hyperparameters. We empirically assess the impact of these regularization cocktails for MLPs on a large-scale empirical study comprising 40 tabular datasets and demonstrate that (i) well-regularized plain MLPs significantly outperform recent state-of-the-art specialized neural network architectures, and (ii) they even outperform strong traditional ML methods, such as XGBoost.
OpenML-Python: an extensible Python API for OpenML
Nov 06, 2019
OpenML is an online platform for open science collaboration in machine learning, used to share datasets and results of machine learning experiments. In this paper we introduce \emph{OpenML-Python}, a client API for Python, opening up the OpenML platform for a wide range of Python-based tools. It provides easy access to all datasets, tasks and experiments on OpenML from within Python. It also provides functionality to conduct machine learning experiments, upload the results to OpenML, and reproduce results which are stored on OpenML. Furthermore, it comes with a scikit-learn plugin and a plugin mechanism to easily integrate other machine learning libraries written in Python into the OpenML ecosystem. Source code and documentation is available at https://github.com/openml/openml-python/.