 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Dynamics in Memristor-Based Equilibrium Propagation
Dec 13, 2025Memristor-based in-memory computing has emerged as a promising paradigm to overcome the constraints of the von Neumann bottleneck and the memory wall by enabling fully parallelisable and energy-efficient vector-matrix multiplications. We investigate the effect of nonlinear, memristor-driven weight updates on the convergence behaviour of neural networks trained with equilibrium propagation (EqProp). Six memristor models were characterised by their voltage-current hysteresis and integrated into the EBANA framework for evaluation on two benchmark classification tasks. EqProp can achieve robust convergence under nonlinear weight updates, provided that memristors exhibit a sufficiently wide resistance range of at least an order of magnitude.
Towards A Correct Usage of Cryptography in Semantic Watermarks for Diffusion Models
Mar 14, 2025Semantic watermarking methods enable the direct integration of watermarks into the generation process of latent diffusion models by only modifying the initial latent noise. One line of approaches building on Gaussian Shading relies on cryptographic primitives to steer the sampling process of the latent noise. However, we identify several issues in the usage of cryptographic techniques in Gaussian Shading, particularly in its proof of lossless performance and key management, causing ambiguity in follow-up works, too. In this work, we therefore revisit the cryptographic primitives for semantic watermarking. We introduce a novel, general proof of lossless performance based on IND\$-CPA security for semantic watermarks. We then discuss the configuration of the cryptographic primitives in semantic watermarks with respect to security, efficiency, and generation quality.
Black-Box Forgery Attacks on Semantic Watermarks for Diffusion Models
Dec 04, 2024



Integrating watermarking into the generation process of latent diffusion models (LDMs) simplifies detection and attribution of generated content. Semantic watermarks, such as Tree-Rings and Gaussian Shading, represent a novel class of watermarking techniques that are easy to implement and highly robust against various perturbations. However, our work demonstrates a fundamental security vulnerability of semantic watermarks. We show that attackers can leverage unrelated models, even with different latent spaces and architectures (UNet vs DiT), to perform powerful and realistic forgery attacks. Specifically, we design two watermark forgery attacks. The first imprints a targeted watermark into real images by manipulating the latent representation of an arbitrary image in an unrelated LDM to get closer to the latent representation of a watermarked image. We also show that this technique can be used for watermark removal. The second attack generates new images with the target watermark by inverting a watermarked image and re-generating it with an arbitrary prompt. Both attacks just need a single reference image with the target watermark. Overall, our findings question the applicability of semantic watermarks by revealing that attackers can easily forge or remove these watermarks under realistic conditions.
The Impact of Uniform Inputs on Activation Sparsity and Energy-Latency Attacks in Computer Vision
Mar 27, 2024
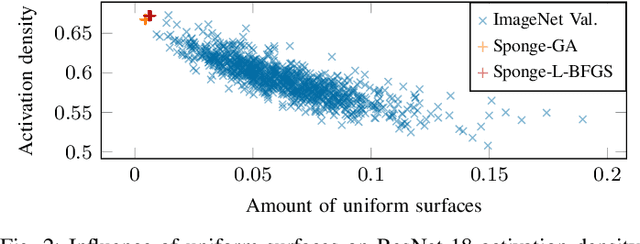


Resource efficiency plays an important role for machine learning nowadays. The energy and decision latency are two critical aspects to ensure a sustainable and practical application. Unfortunately, the energy consumption and decision latency are not robust against adversaries. Researchers have recently demonstrated that attackers can compute and submit so-called sponge examples at inference time to increase the energy consumption and decision latency of neural networks. In computer vision, the proposed strategy crafts inputs with less activation sparsity which could otherwise be used to accelerate the computation. In this paper, we analyze the mechanism how these energy-latency attacks reduce activation sparsity. In particular, we find that input uniformity is a key enabler. A uniform image, that is, an image with mostly flat, uniformly colored surfaces, triggers more activations due to a specific interplay of convolution, batch normalization, and ReLU activation. Based on these insights, we propose two new simple, yet effective strategies for crafting sponge examples: sampling images from a probability distribution and identifying dense, yet inconspicuous inputs in natural datasets. We empirically examine our findings in a comprehensive evaluation with multiple image classification models and show that our attack achieves the same sparsity effect as prior sponge-example methods, but at a fraction of computation effort. We also show that our sponge examples transfer between different neural networks. Finally, we discuss applications of our findings for the good by improving efficiency by increasing sparsity.
MotherNet: A Foundational Hypernetwork for Tabular Classification
Dec 14, 2023The advent of Foundation Models is transforming machine learning across many modalities (e.g., language, images, videos) with prompt engineering replacing training in many settings. Recent work on tabular data (e.g., TabPFN) hints at a similar opportunity to build Foundation Models for classification for numerical data. In this paper, we go one step further and propose a hypernetwork architecture that we call MotherNet, trained on millions of classification tasks, that, once prompted with a never-seen-before training set generates the weights of a trained ``child'' neural-network. Like other Foundation Models, MotherNet replaces training on specific datasets with in-context learning through a single forward pass. In contrast to existing hypernetworks that were either task-specific or trained for relatively constraint multi-task settings, MotherNet is trained to generate networks to perform multiclass classification on arbitrary tabular datasets without any dataset specific gradient descent. The child network generated by MotherNet using in-context learning outperforms neural networks trained using gradient descent on small datasets, and is competitive with predictions by TabPFN and standard ML methods like Gradient Boosting. Unlike a direct application of transformer models like TabPFN, MotherNet generated networks are highly efficient at inference time. This methodology opens up a new approach to building predictive models on tabular data that is both efficient and robust, without any dataset-specific training.
On the Detection of Image-Scaling Attacks in Machine Learning
Oct 23, 2023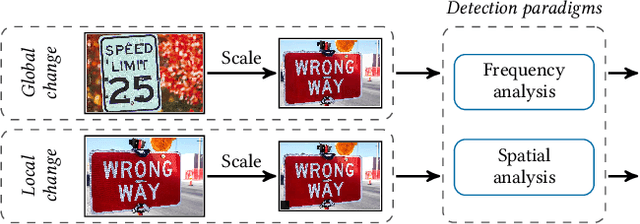



Image scaling is an integral part of machine learning and computer vision systems. Unfortunately, this preprocessing step is vulnerable to so-called image-scaling attacks where an attacker makes unnoticeable changes to an image so that it becomes a new image after scaling. This opens up new ways for attackers to control the prediction or to improve poisoning and backdoor attacks. While effective techniques exist to prevent scaling attacks, their detection has not been rigorously studied yet. Consequently, it is currently not possible to reliably spot these attacks in practice. This paper presents the first in-depth systematization and analysis of detection methods for image-scaling attacks. We identify two general detection paradigms and derive novel methods from them that are simple in design yet significantly outperform previous work. We demonstrate the efficacy of these methods in a comprehensive evaluation with all major learning platforms and scaling algorithms. First, we show that image-scaling attacks modifying the entire scaled image can be reliably detected even under an adaptive adversary. Second, we find that our methods provide strong detection performance even if only minor parts of the image are manipulated. As a result, we can introduce a novel protection layer against image-scaling attacks.
Detecting Spells in Fantasy Literature with a Transformer Based Artificial Intelligence
Aug 07, 2023



Transformer architectures and models have made significant progress in language-based tasks. In this area, is BERT one of the most widely used and freely available transformer architecture. In our work, we use BERT for context-based phrase recognition of magic spells in the Harry Potter novel series. Spells are a common part of active magic in fantasy novels. Typically, spells are used in a specific context to achieve a supernatural effect. A series of investigations were conducted to see if a Transformer architecture could recognize such phrases based on their context in the Harry Potter saga. For our studies a pre-trained BERT model was used and fine-tuned utilising different datasets and training methods to identify the searched context. By considering different approaches for sequence classification as well as token classification, it is shown that the context of spells can be recognised. According to our investigations, the examined sequence length for fine-tuning and validation of the model plays a significant role in context recognition. Based on this, we have investigated whether spells have overarching properties that allow a transfer of the neural network models to other fantasy universes as well. The application of our model showed promising results and is worth to be deepened in subsequent studies.
Organelle-specific segmentation, spatial analysis, and visualization of volume electron microscopy datasets
Mar 07, 2023Volume electron microscopy is the method of choice for the in-situ interrogation of cellular ultrastructure at the nanometer scale. Recent technical advances have led to a rapid increase in large raw image datasets that require computational strategies for segmentation and spatial analysis. In this protocol, we describe a practical and annotation-efficient pipeline for organelle-specific segmentation, spatial analysis, and visualization of large volume electron microscopy datasets using freely available, user-friendly software tools that can be run on a single standard workstation. We specifically target researchers in the life sciences with limited computational expertise, who face the following tasks within their volume electron microscopy projects: i) How to generate 3D segmentation labels for different types of cell organelles while minimizing manual annotation efforts, ii) how to analyze the spatial interactions between organelle instances, and iii) how to best visualize the 3D segmentation results. To meet these demands we give detailed guidelines for choosing the most efficient segmentation tools for the specific cell organelle. We furthermore provide easily executable components for spatial analysis and 3D rendering and bridge compatibility issues between freely available open-source tools, such that others can replicate our full pipeline starting from a raw dataset up to the final plots and rendered images. We believe that our detailed description can serve as a valuable reference for similar projects requiring special strategies for single- or multiple organelle analysis which can be achieved with computational resources commonly available to single-user setups.
A comparative study on 2-DOF variable stiffness mechanisms
Mar 19, 2020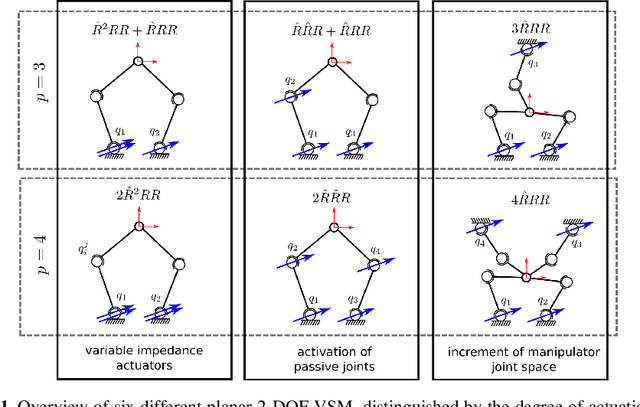
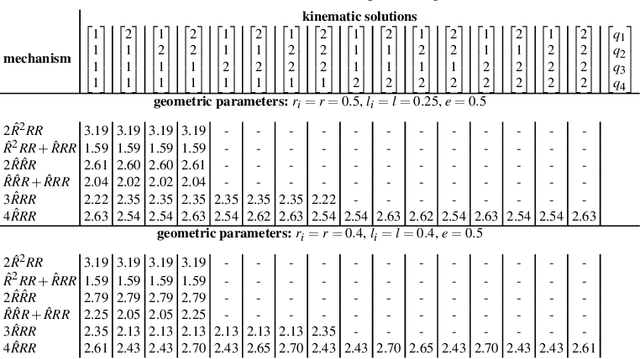
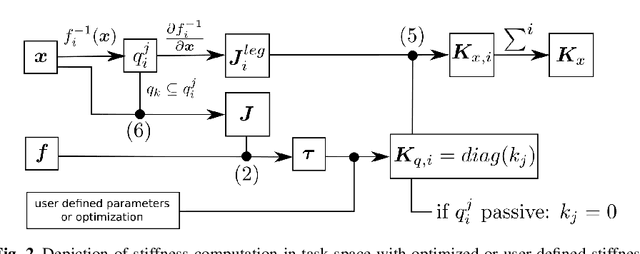
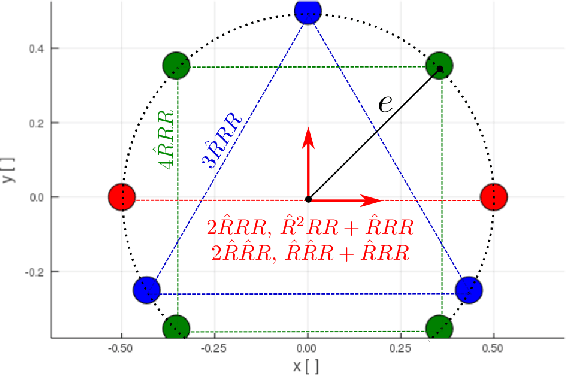
Based on the idea of variable stiffness mechanisms, a variety of such mechanisms is shown in this work. Specifically, 2-DOF parallel kinematic machines equipped with redundant actuators and non-linear springs in the actuated joints are presented and a comparative overview is drawn. Accordingly, a general stiffness formulation in task space of all mechanisms is given. Under fixed geometric parameters, optimization of task space stiffness is carried out on the designs comprising all kinematic solutions. Finally, a stiffness metric is introduced that allows a quantitative comparison of the given mechanism designs. This gives rise to design guidelines for engineers but also shows an interesting outline for future applications of variable stiffness mechanisms.
OpenML-Python: an extensible Python API for OpenML
Nov 06, 2019
OpenML is an online platform for open science collaboration in machine learning, used to share datasets and results of machine learning experiments. In this paper we introduce \emph{OpenML-Python}, a client API for Python, opening up the OpenML platform for a wide range of Python-based tools. It provides easy access to all datasets, tasks and experiments on OpenML from within Python. It also provides functionality to conduct machine learning experiments, upload the results to OpenML, and reproduce results which are stored on OpenML. Furthermore, it comes with a scikit-learn plugin and a plugin mechanism to easily integrate other machine learning libraries written in Python into the OpenML ecosystem. Source code and documentation is available at https://github.com/openml/openml-python/.