 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinding Patterns in Ambiguity: Interpretable Stress Testing in the Decision~Boundary
Aug 12, 2024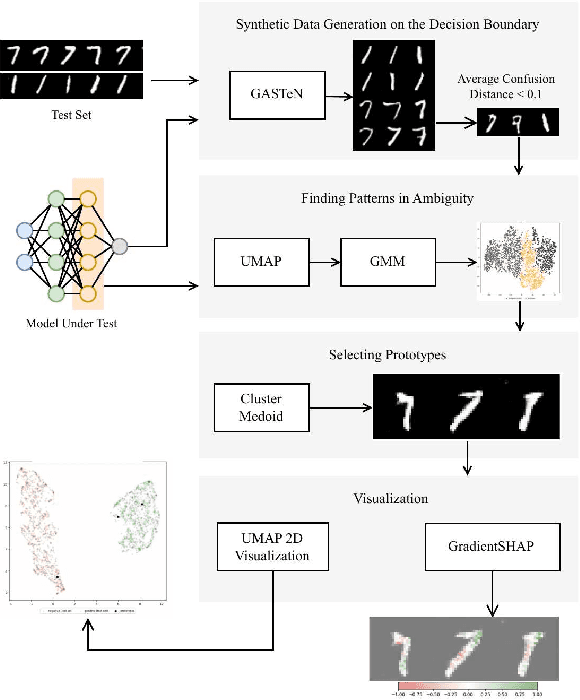
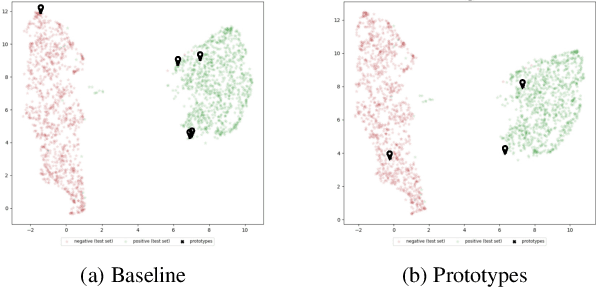
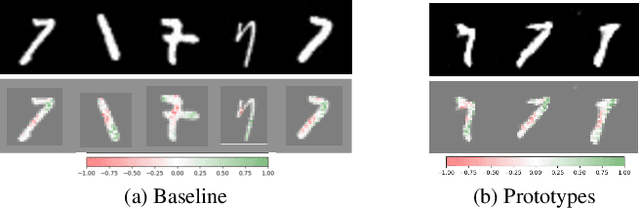
The increasing use of deep learning across various domains highlights the importance of understanding the decision-making processes of these black-box models. Recent research focusing on the decision boundaries of deep classifiers, relies on generated synthetic instances in areas of low confidence, uncovering samples that challenge both models and humans. We propose a novel approach to enhance the interpretability of deep binary classifiers by selecting representative samples from the decision boundary - prototypes - and applying post-model explanation algorithms. We evaluate the effectiveness of our approach through 2D visualizations and GradientSHAP analysis. Our experiments demonstrate the potential of the proposed method, revealing distinct and compact clusters and diverse prototypes that capture essential features that lead to low-confidence decisions. By offering a more aggregated view of deep classifiers' decision boundaries, our work contributes to the responsible development and deployment of reliable machine learning systems.
Automated Design of Linear Bounding Functions for Sigmoidal Nonlinearities in Neural Networks
Jun 14, 2024The ubiquity of deep learning algorithms in various applications has amplified the need for assuring their robustness against small input perturbations such as those occurring in adversarial attacks. Existing complete verification techniques offer provable guarantees for all robustness queries but struggle to scale beyond small neural networks. To overcome this computational intractability, incomplete verification methods often rely on convex relaxation to over-approximate the nonlinearities in neural networks. Progress in tighter approximations has been achieved for piecewise linear functions. However, robustness verification of neural networks for general activation functions (e.g., Sigmoid, Tanh) remains under-explored and poses new challenges. Typically, these networks are verified using convex relaxation techniques, which involve computing linear upper and lower bounds of the nonlinear activation functions. In this work, we propose a novel parameter search method to improve the quality of these linear approximations. Specifically, we show that using a simple search method, carefully adapted to the given verification problem through state-of-the-art algorithm configuration techniques, improves the average global lower bound by 25% on average over the current state of the art on several commonly used local robustness verification benchmarks.
AI Competitions and Benchmarks: Dataset Development
Apr 15, 2024



Machine learning is now used in many applications thanks to its ability to predict, generate, or discover patterns from large quantities of data. However, the process of collecting and transforming data for practical use is intricate. Even in today's digital era, where substantial data is generated daily, it is uncommon for it to be readily usable; most often, it necessitates meticulous manual data preparation. The haste in developing new models can frequently result in various shortcomings, potentially posing risks when deployed in real-world scenarios (eg social discrimination, critical failures), leading to the failure or substantial escalation of costs in AI-based projects. This chapter provides a comprehensive overview of established methodological tools, enriched by our practical experience, in the development of datasets for machine learning. Initially, we develop the tasks involved in dataset development and offer insights into their effective management (including requirements, design, implementation, evaluation, distribution, and maintenance). Then, we provide more details about the implementation process which includes data collection, transformation, and quality evaluation. Finally, we address practical considerations regarding dataset distribution and maintenance.
Are LSTMs Good Few-Shot Learners?
Oct 22, 2023Deep learning requires large amounts of data to learn new tasks well, limiting its applicability to domains where such data is available. Meta-learning overcomes this limitation by learning how to learn. In 2001, Hochreiter et al. showed that an LSTM trained with backpropagation across different tasks is capable of meta-learning. Despite promising results of this approach on small problems, and more recently, also on reinforcement learning problems, the approach has received little attention in the supervised few-shot learning setting. We revisit this approach and test it on modern few-shot learning benchmarks. We find that LSTM, surprisingly, outperform the popular meta-learning technique MAML on a simple few-shot sine wave regression benchmark, but that LSTM, expectedly, fall short on more complex few-shot image classification benchmarks. We identify two potential causes and propose a new method called Outer Product LSTM (OP-LSTM) that resolves these issues and displays substantial performance gains over the plain LSTM. Compared to popular meta-learning baselines, OP-LSTM yields competitive performance on within-domain few-shot image classification, and performs better in cross-domain settings by 0.5% to 1.9% in accuracy score. While these results alone do not set a new state-of-the-art, the advances of OP-LSTM are orthogonal to other advances in the field of meta-learning, yield new insights in how LSTM work in image classification, allowing for a whole range of new research directions. For reproducibility purposes, we publish all our research code publicly.
Subspace Adaptation Prior for Few-Shot Learning
Oct 13, 2023Gradient-based meta-learning techniques aim to distill useful prior knowledge from a set of training tasks such that new tasks can be learned more efficiently with gradient descent. While these methods have achieved successes in various scenarios, they commonly adapt all parameters of trainable layers when learning new tasks. This neglects potentially more efficient learning strategies for a given task distribution and may be susceptible to overfitting, especially in few-shot learning where tasks must be learned from a limited number of examples. To address these issues, we propose Subspace Adaptation Prior (SAP), a novel gradient-based meta-learning algorithm that jointly learns good initialization parameters (prior knowledge) and layer-wise parameter subspaces in the form of operation subsets that should be adaptable. In this way, SAP can learn which operation subsets to adjust with gradient descent based on the underlying task distribution, simultaneously decreasing the risk of overfitting when learning new tasks. We demonstrate that this ability is helpful as SAP yields superior or competitive performance in few-shot image classification settings (gains between 0.1% and 3.9% in accuracy). Analysis of the learned subspaces demonstrates that low-dimensional operations often yield high activation strengths, indicating that they may be important for achieving good few-shot learning performance. For reproducibility purposes, we publish all our research code publicly.
Understanding Transfer Learning and Gradient-Based Meta-Learning Techniques
Oct 09, 2023

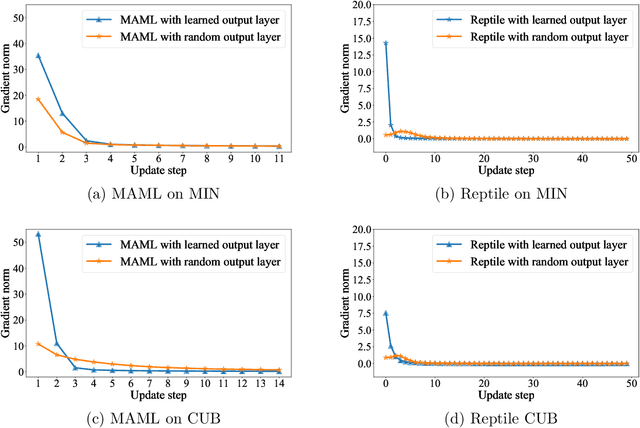

Deep neural networks can yield good performance on various tasks but often require large amounts of data to train them. Meta-learning received considerable attention as one approach to improve the generalization of these networks from a limited amount of data. Whilst meta-learning techniques have been observed to be successful at this in various scenarios, recent results suggest that when evaluated on tasks from a different data distribution than the one used for training, a baseline that simply finetunes a pre-trained network may be more effective than more complicated meta-learning techniques such as MAML, which is one of the most popular meta-learning techniques. This is surprising as the learning behaviour of MAML mimics that of finetuning: both rely on re-using learned features. We investigate the observed performance differences between finetuning, MAML, and another meta-learning technique called Reptile, and show that MAML and Reptile specialize for fast adaptation in low-data regimes of similar data distribution as the one used for training. Our findings show that both the output layer and the noisy training conditions induced by data scarcity play important roles in facilitating this specialization for MAML. Lastly, we show that the pre-trained features as obtained by the finetuning baseline are more diverse and discriminative than those learned by MAML and Reptile. Due to this lack of diversity and distribution specialization, MAML and Reptile may fail to generalize to out-of-distribution tasks whereas finetuning can fall back on the diversity of the learned features.
Artificial intelligence to advance Earth observation: a perspective
May 15, 2023Earth observation (EO) is a prime instrument for monitoring land and ocean processes, studying the dynamics at work, and taking the pulse of our planet. This article gives a bird's eye view of the essential scientific tools and approaches informing and supporting the transition from raw EO data to usable EO-based information. The promises, as well as the current challenges of these developments, are highlighted under dedicated sections. Specifically, we cover the impact of (i) Computer vision; (ii) Machine learning; (iii) Advanced processing and computing; (iv) Knowledge-based AI; (v) Explainable AI and causal inference; (vi) Physics-aware models; (vii) User-centric approaches; and (viii) the much-needed discussion of ethical and societal issues related to the massive use of ML technologies in EO.
Hyperparameter Importance of Quantum Neural Networks Across Small Datasets
Jun 20, 2022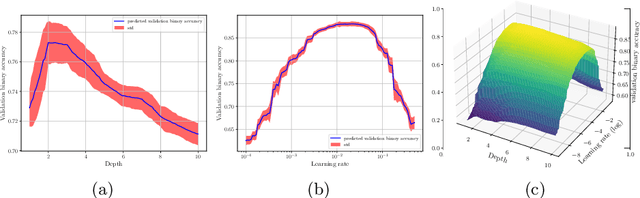

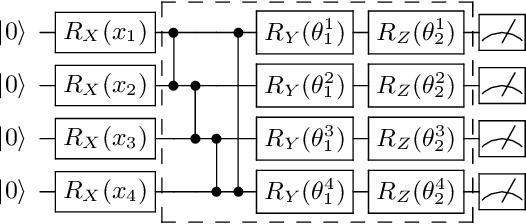
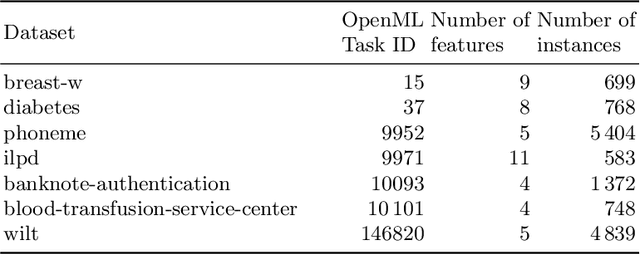
As restricted quantum computers are slowly becoming a reality, the search for meaningful first applications intensifies. In this domain, one of the more investigated approaches is the use of a special type of quantum circuit - a so-called quantum neural network -- to serve as a basis for a machine learning model. Roughly speaking, as the name suggests, a quantum neural network can play a similar role to a neural network. However, specifically for applications in machine learning contexts, very little is known about suitable circuit architectures, or model hyperparameters one should use to achieve good learning performance. In this work, we apply the functional ANOVA framework to quantum neural networks to analyze which of the hyperparameters were most influential for their predictive performance. We analyze one of the most typically used quantum neural network architectures. We then apply this to $7$ open-source datasets from the OpenML-CC18 classification benchmark whose number of features is small enough to fit on quantum hardware with less than $20$ qubits. Three main levels of importance were detected from the ranking of hyperparameters obtained with functional ANOVA. Our experiment both confirmed expected patterns and revealed new insights. For instance, setting well the learning rate is deemed the most critical hyperparameter in terms of marginal contribution on all datasets, whereas the particular choice of entangling gates used is considered the least important except on one dataset. This work introduces new methodologies to study quantum machine learning models and provides new insights toward quantum model selection.
Learning Curves for Decision Making in Supervised Machine Learning -- A Survey
Jan 28, 2022


Learning curves are a concept from social sciences that has been adopted in the context of machine learning to assess the performance of a learning algorithm with respect to a certain resource, e.g. the number of training examples or the number of training iterations. Learning curves have important applications in several contexts of machine learning, most importantly for the context of data acquisition, early stopping of model training and model selection. For example, by modelling the learning curves, one can assess at an early stage whether the algorithm and hyperparameter configuration have the potential to be a suitable choice, often speeding up the algorithm selection process. A variety of approaches has been proposed to use learning curves for decision making. Some models answer the binary decision question of whether a certain algorithm at a certain budget will outperform a certain reference performance, whereas more complex models predict the entire learning curve of an algorithm. We contribute a framework that categorizes learning curve approaches using three criteria: the decision situation that they address, the intrinsic learning curve question that they answer and the type of resources that they use. We survey papers from literature and classify them into this framework.
Fast and Informative Model Selection using Learning Curve Cross-Validation
Nov 27, 2021

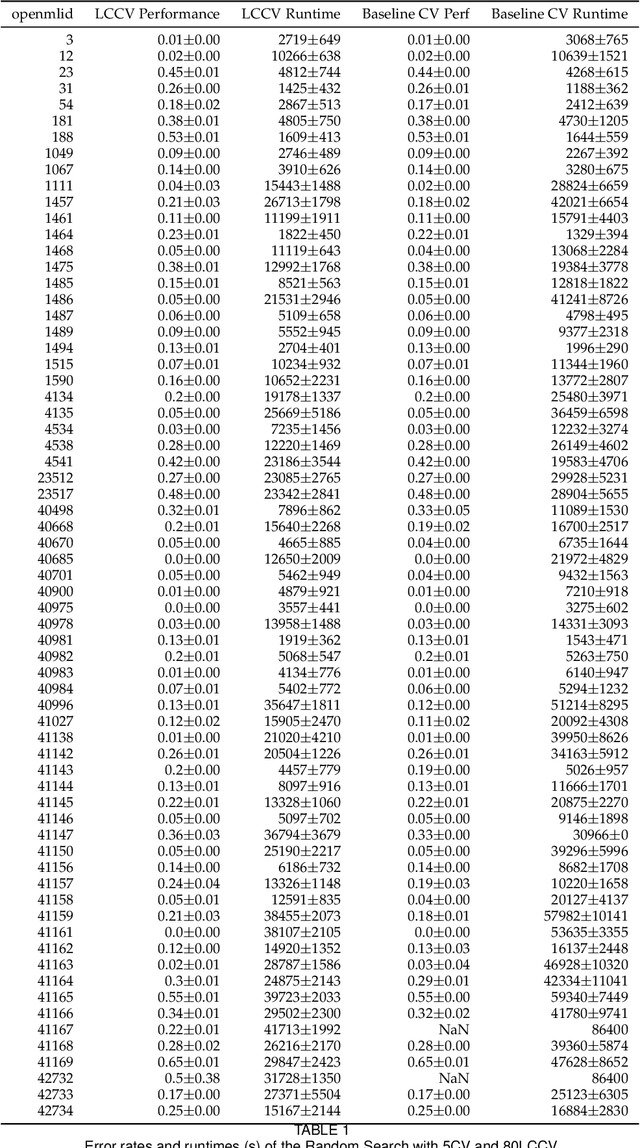
Common cross-validation (CV) methods like k-fold cross-validation or Monte-Carlo cross-validation estimate the predictive performance of a learner by repeatedly training it on a large portion of the given data and testing on the remaining data. These techniques have two major drawbacks. First, they can be unnecessarily slow on large datasets. Second, beyond an estimation of the final performance, they give almost no insights into the learning process of the validated algorithm. In this paper, we present a new approach for validation based on learning curves (LCCV). Instead of creating train-test splits with a large portion of training data, LCCV iteratively increases the number of instances used for training. In the context of model selection, it discards models that are very unlikely to become competitive. We run a large scale experiment on the 67 datasets from the AutoML benchmark and empirically show that in over 90% of the cases using LCCV leads to similar performance (at most 1.5% difference) as using 5/10-fold CV. However, it yields substantial runtime reductions of over 20% on average. Additionally, it provides important insights, which for example allow assessing the benefits of acquiring more data. These results are orthogonal to other advances in the field of AutoML.