 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrated Adversarial Sampling: Multi-Armed Bandit-Guided Generalization Against Unforeseen Attacks
Nov 15, 2025Deep Neural Networks (DNNs) are known to be vulnerable to various adversarial perturbations. To address the safety concerns arising from these vulnerabilities, adversarial training (AT) has emerged as one of the most effective paradigms for enhancing the robustness of DNNs. However, existing AT frameworks primarily focus on a single or a limited set of attack types, leaving DNNs still exposed to attack types that may be encountered in practice but not addressed during training. In this paper, we propose an efficient fine-tuning method called Calibrated Adversarial Sampling (CAS) to address these issues. From the optimization perspective within the multi-armed bandit framework, it dynamically designs rewards and balances exploration and exploitation by considering the dynamic and interdependent characteristics of multiple robustness dimensions. Experiments on benchmark datasets show that CAS achieves superior overall robustness while maintaining high clean accuracy, providing a new paradigm for robust generalization of DNNs.
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.
Risk-Averse Certification of Bayesian Neural Networks
Nov 29, 2024



In light of the inherently complex and dynamic nature of real-world environments, incorporating risk measures is crucial for the robustness evaluation of deep learning models. In this work, we propose a Risk-Averse Certification framework for Bayesian neural networks called RAC-BNN. Our method leverages sampling and optimisation to compute a sound approximation of the output set of a BNN, represented using a set of template polytopes. To enhance robustness evaluation, we integrate a coherent distortion risk measure--Conditional Value at Risk (CVaR)--into the certification framework, providing probabilistic guarantees based on empirical distributions obtained through sampling. We validate RAC-BNN on a range of regression and classification benchmarks and compare its performance with a state-of-the-art method. The results show that RAC-BNN effectively quantifies robustness under worst-performing risky scenarios, and achieves tighter certified bounds and higher efficiency in complex tasks.
FAST: Boosting Uncertainty-based Test Prioritization Methods for Neural Networks via Feature Selection
Sep 13, 2024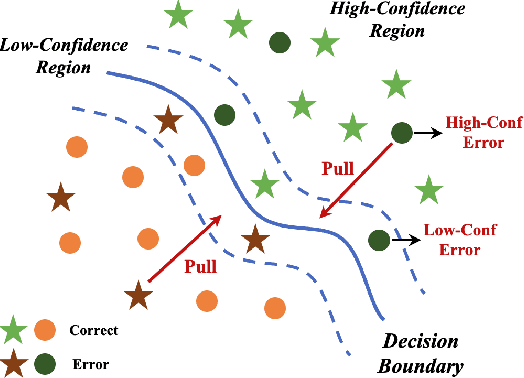
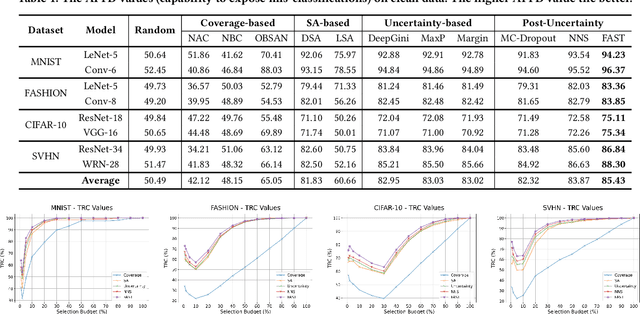
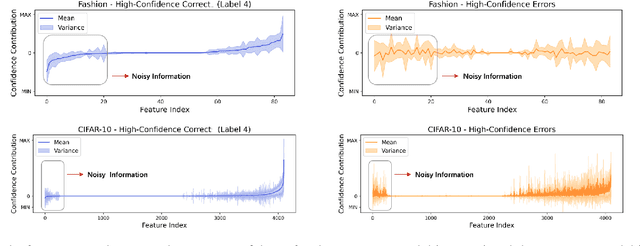
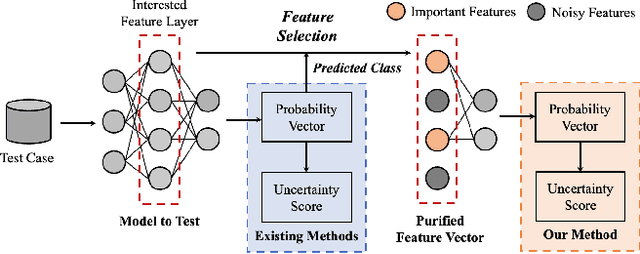
Due to the vast testing space, the increasing demand for effective and efficient testing of deep neural networks (DNNs) has led to the development of various DNN test case prioritization techniques. However, the fact that DNNs can deliver high-confidence predictions for incorrectly predicted examples, known as the over-confidence problem, causes these methods to fail to reveal high-confidence errors. To address this limitation, in this work, we propose FAST, a method that boosts existing prioritization methods through guided FeAture SelecTion. FAST is based on the insight that certain features may introduce noise that affects the model's output confidence, thereby contributing to high-confidence errors. It quantifies the importance of each feature for the model's correct predictions, and then dynamically prunes the information from the noisy features during inference to derive a new probability vector for the uncertainty estimation. With the help of FAST, the high-confidence errors and correctly classified examples become more distinguishable, resulting in higher APFD (Average Percentage of Fault Detection) values for test prioritization, and higher generalization ability for model enhancement. We conduct extensive experiments to evaluate FAST across a diverse set of model structures on multiple benchmark datasets to validate the effectiveness, efficiency, and scalability of FAST compared to the state-of-the-art prioritization techniques.
PREMAP: A Unifying PREiMage APproximation Framework for Neural Networks
Aug 17, 2024Most methods for neural network verification focus on bounding the image, i.e., set of outputs for a given input set. This can be used to, for example, check the robustness of neural network predictions to bounded perturbations of an input. However, verifying properties concerning the preimage, i.e., the set of inputs satisfying an output property, requires abstractions in the input space. We present a general framework for preimage abstraction that produces under- and over-approximations of any polyhedral output set. Our framework employs cheap parameterised linear relaxations of the neural network, together with an anytime refinement procedure that iteratively partitions the input region by splitting on input features and neurons. The effectiveness of our approach relies on carefully designed heuristics and optimization objectives to achieve rapid improvements in the approximation volume. We evaluate our method on a range of tasks, demonstrating significant improvement in efficiency and scalability to high-input-dimensional image classification tasks compared to state-of-the-art techniques. Further, we showcase the application to quantitative verification and robustness analysis, presenting a sound and complete algorithm for the former and providing sound quantitative results for the latter.
Protecting Deep Learning Model Copyrights with Adversarial Example-Free Reuse Detection
Jul 04, 2024
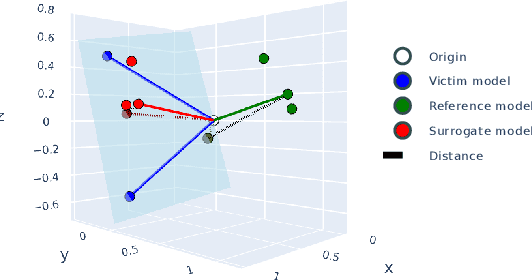

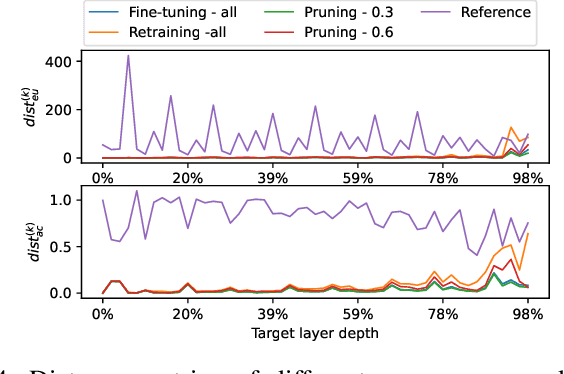
Model reuse techniques can reduce the resource requirements for training high-performance deep neural networks (DNNs) by leveraging existing models. However, unauthorized reuse and replication of DNNs can lead to copyright infringement and economic loss to the model owner. This underscores the need to analyze the reuse relation between DNNs and develop copyright protection techniques to safeguard intellectual property rights. Existing white-box testing-based approaches cannot address the common heterogeneous reuse case where the model architecture is changed, and DNN fingerprinting approaches heavily rely on generating adversarial examples with good transferability, which is known to be challenging in the black-box setting. To bridge the gap, we propose NFARD, a Neuron Functionality Analysis-based Reuse Detector, which only requires normal test samples to detect reuse relations by measuring the models' differences on a newly proposed model characterization, i.e., neuron functionality (NF). A set of NF-based distance metrics is designed to make NFARD applicable to both white-box and black-box settings. Moreover, we devise a linear transformation method to handle heterogeneous reuse cases by constructing the optimal projection matrix for dimension consistency, significantly extending the application scope of NFARD. To the best of our knowledge, this is the first adversarial example-free method that exploits neuron functionality for DNN copyright protection. As a side contribution, we constructed a reuse detection benchmark named Reuse Zoo that covers various practical reuse techniques and popular datasets. Extensive evaluations on this comprehensive benchmark show that NFARD achieves F1 scores of 0.984 and 1.0 for detecting reuse relationships in black-box and white-box settings, respectively, while generating test suites 2 ~ 99 times faster than previous methods.
Automated Design of Linear Bounding Functions for Sigmoidal Nonlinearities in Neural Networks
Jun 14, 2024The ubiquity of deep learning algorithms in various applications has amplified the need for assuring their robustness against small input perturbations such as those occurring in adversarial attacks. Existing complete verification techniques offer provable guarantees for all robustness queries but struggle to scale beyond small neural networks. To overcome this computational intractability, incomplete verification methods often rely on convex relaxation to over-approximate the nonlinearities in neural networks. Progress in tighter approximations has been achieved for piecewise linear functions. However, robustness verification of neural networks for general activation functions (e.g., Sigmoid, Tanh) remains under-explored and poses new challenges. Typically, these networks are verified using convex relaxation techniques, which involve computing linear upper and lower bounds of the nonlinear activation functions. In this work, we propose a novel parameter search method to improve the quality of these linear approximations. Specifically, we show that using a simple search method, carefully adapted to the given verification problem through state-of-the-art algorithm configuration techniques, improves the average global lower bound by 25% on average over the current state of the art on several commonly used local robustness verification benchmarks.
When to Trust AI: Advances and Challenges for Certification of Neural Networks
Sep 20, 2023Artificial intelligence (AI) has been advancing at a fast pace and it is now poised for deployment in a wide range of applications, such as autonomous systems, medical diagnosis and natural language processing. Early adoption of AI technology for real-world applications has not been without problems, particularly for neural networks, which may be unstable and susceptible to adversarial examples. In the longer term, appropriate safety assurance techniques need to be developed to reduce potential harm due to avoidable system failures and ensure trustworthiness. Focusing on certification and explainability, this paper provides an overview of techniques that have been developed to ensure safety of AI decisions and discusses future challenges.
Weighted Automata Extraction and Explanation of Recurrent Neural Networks for Natural Language Tasks
Jun 24, 2023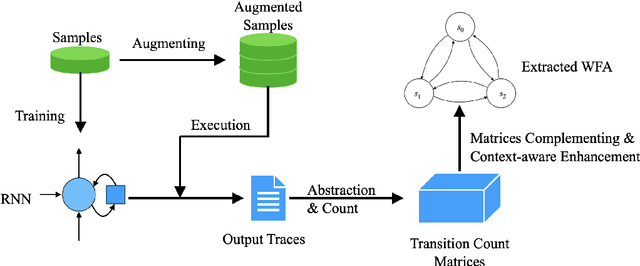
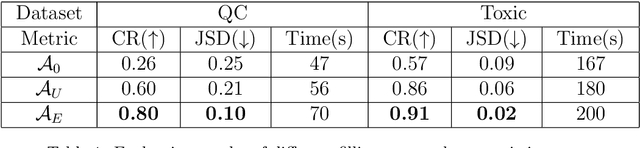
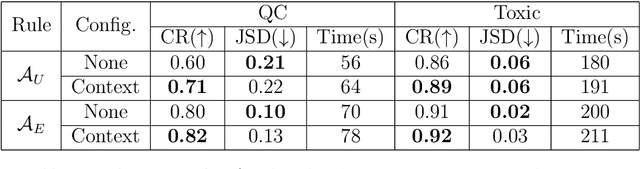
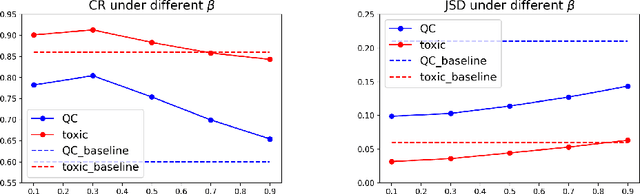
Recurrent Neural Networks (RNNs) have achieved tremendous success in processing sequential data, yet understanding and analyzing their behaviours remains a significant challenge. To this end, many efforts have been made to extract finite automata from RNNs, which are more amenable for analysis and explanation. However, existing approaches like exact learning and compositional approaches for model extraction have limitations in either scalability or precision. In this paper, we propose a novel framework of Weighted Finite Automata (WFA) extraction and explanation to tackle the limitations for natural language tasks. First, to address the transition sparsity and context loss problems we identified in WFA extraction for natural language tasks, we propose an empirical method to complement missing rules in the transition diagram, and adjust transition matrices to enhance the context-awareness of the WFA. We also propose two data augmentation tactics to track more dynamic behaviours of RNN, which further allows us to improve the extraction precision. Based on the extracted model, we propose an explanation method for RNNs including a word embedding method -- Transition Matrix Embeddings (TME) and TME-based task oriented explanation for the target RNN. Our evaluation demonstrates the advantage of our method in extraction precision than existing approaches, and the effectiveness of TME-based explanation method in applications to pretraining and adversarial example generation.
On Preimage Approximation for Neural Networks
May 08, 2023Neural network verification mainly focuses on local robustness properties. However, often it is important to know whether a given property holds globally for the whole input domain, and if not then for what proportion of the input the property is true. While exact preimage generation can construct an equivalent representation of neural networks that can aid such (quantitative) global robustness verification, it is intractable at scale. In this work, we propose an efficient and practical anytime algorithm for generating symbolic under-approximations of the preimage of neural networks based on linear relaxation. Our algorithm iteratively minimizes the volume approximation error by partitioning the input region into subregions, where the neural network relaxation bounds become tighter. We further employ sampling and differentiable approximations to the volume in order to prioritize regions to split and optimize the parameters of the relaxation, leading to faster improvement and more compact under-approximations. Evaluation results demonstrate that our approach is able to generate preimage approximations significantly faster than exact methods and scales to neural network controllers for which exact preimage generation is intractable. We also demonstrate an application of our approach to quantitative global verification.