 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainFuzz: Explainable and Constraint-Conditioned Test Generation with Probabilistic Circuits
Apr 08, 2026Understanding and explaining the structure of generated test inputs is essential for effective software testing and debugging. Existing approaches--including grammar-based fuzzers, probabilistic Context-Free Grammars (pCFGs), and Large Language Models (LLMs)--suffer from critical limitations. They frequently produce ill-formed inputs that fail to reflect realistic data distributions, struggle to capture context-sensitive probabilistic dependencies, and lack explainability. We introduce ExplainFuzz, a test generation framework that leverages Probabilistic Circuits (PCs) to learn and query structured distributions over grammar-based test inputs interpretably and controllably. Starting from a Context-Free Grammar (CFG), ExplainFuzz compiles a grammar-aware PC and trains it on existing inputs. New inputs are then generated via sampling. ExplainFuzz utilizes the conditioning capability of PCs to incorporate test-specific constraints (e.g., a query must have GROUP BY), enabling constrained probabilistic sampling to generate inputs satisfying grammar and user-provided constraints. Our results show that ExplainFuzz improves the coherence and realism of generated inputs, achieving significant perplexity reduction compared to pCFGs, grammar-unaware PCs, and LLMs. By leveraging its native conditioning capability, ExplainFuzz significantly enhances the diversity of inputs that satisfy a user-provided constraint. Compared to grammar-aware mutational fuzzing, ExplainFuzz increases bug-triggering rates from 35% to 63% in SQL and from 10% to 100% in XML. These results demonstrate the power of a learned input distribution over mutational fuzzing, which is often limited to exploring the local neighborhood of seed inputs. These capabilities highlight the potential of PCs to serve as a foundation for grammar-aware, controllable test generation that captures context-sensitive, probabilistic dependencies.
How to Marginalize in Causal Structure Learning?
Nov 18, 2025Bayesian networks (BNs) are a widely used class of probabilistic graphical models employed in numerous application domains. However, inferring the network's graphical structure from data remains challenging. Bayesian structure learners approach this problem by inferring a posterior distribution over the possible directed acyclic graphs underlying the BN. The inference process often requires marginalizing over probability distributions, which is typically done using dynamic programming methods that restrict the set of possible parents for each node. Instead, we present a novel method that utilizes tractable probabilistic circuits to circumvent this restriction. This method utilizes a new learning routine that trains these circuits on both the original distribution and marginal queries. The architecture of probabilistic circuits then inherently allows for fast and exact marginalization on the learned distribution. We then show empirically that utilizing our method to answer marginals allows Bayesian structure learners to improve their performance compared to current methods.
Scaling Probabilistic Circuits via Monarch Matrices
Jun 14, 2025Probabilistic Circuits (PCs) are tractable representations of probability distributions allowing for exact and efficient computation of likelihoods and marginals. Recent advancements have improved the scalability of PCs either by leveraging their sparse properties or through the use of tensorized operations for better hardware utilization. However, no existing method fully exploits both aspects simultaneously. In this paper, we propose a novel sparse and structured parameterization for the sum blocks in PCs. By replacing dense matrices with sparse Monarch matrices, we significantly reduce the memory and computation costs, enabling unprecedented scaling of PCs. From a theory perspective, our construction arises naturally from circuit multiplication; from a practical perspective, compared to previous efforts on scaling up tractable probabilistic models, our approach not only achieves state-of-the-art generative modeling performance on challenging benchmarks like Text8, LM1B and ImageNet, but also demonstrates superior scaling behavior, achieving the same performance with substantially less compute as measured by the number of floating-point operations (FLOPs) during training.
TRACE Back from the Future: A Probabilistic Reasoning Approach to Controllable Language Generation
Apr 25, 2025As large language models (LMs) advance, there is an increasing need to control their outputs to align with human values (e.g., detoxification) or desired attributes (e.g., personalization, topic). However, autoregressive models focus on next-token predictions and struggle with global properties that require looking ahead. Existing solutions either tune or post-train LMs for each new attribute - expensive and inflexible - or approximate the Expected Attribute Probability (EAP) of future sequences by sampling or training, which is slow and unreliable for rare attributes. We introduce TRACE (Tractable Probabilistic Reasoning for Adaptable Controllable gEneration), a novel framework that efficiently computes EAP and adapts to new attributes through tractable probabilistic reasoning and lightweight control. TRACE distills a Hidden Markov Model (HMM) from an LM and pairs it with a small classifier to estimate attribute probabilities, enabling exact EAP computation over the HMM's predicted futures. This EAP is then used to reweigh the LM's next-token probabilities for globally compliant continuations. Empirically, TRACE achieves state-of-the-art results in detoxification with only 10% decoding overhead, adapts to 76 low-resource personalized LLMs within seconds, and seamlessly extends to composite attributes.
A Compositional Atlas for Algebraic Circuits
Dec 07, 2024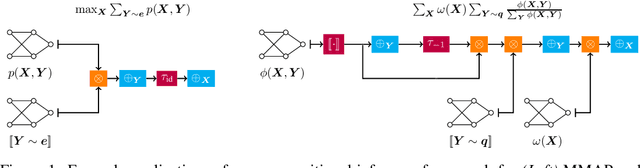
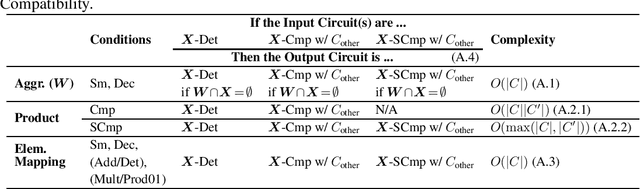
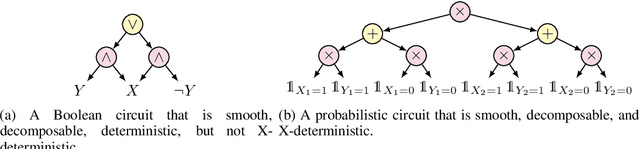

Circuits based on sum-product structure have become a ubiquitous representation to compactly encode knowledge, from Boolean functions to probability distributions. By imposing constraints on the structure of such circuits, certain inference queries become tractable, such as model counting and most probable configuration. Recent works have explored analyzing probabilistic and causal inference queries as compositions of basic operators to derive tractability conditions. In this paper, we take an algebraic perspective for compositional inference, and show that a large class of queries - including marginal MAP, probabilistic answer set programming inference, and causal backdoor adjustment - correspond to a combination of basic operators over semirings: aggregation, product, and elementwise mapping. Using this framework, we uncover simple and general sufficient conditions for tractable composition of these operators, in terms of circuit properties (e.g., marginal determinism, compatibility) and conditions on the elementwise mappings. Applying our analysis, we derive novel tractability conditions for many such compositional queries. Our results unify tractability conditions for existing problems on circuits, while providing a blueprint for analysing novel compositional inference queries.
Restructuring Tractable Probabilistic Circuits
Nov 19, 2024Probabilistic circuits (PCs) is a unifying representation for probabilistic models that support tractable inference. Numerous applications of PCs like controllable text generation depend on the ability to efficiently multiply two circuits. Existing multiplication algorithms require that the circuits respect the same structure, i.e. variable scopes decomposes according to the same vtree. In this work, we propose and study the task of restructuring structured(-decomposable) PCs, that is, transforming a structured PC such that it conforms to a target vtree. We propose a generic approach for this problem and show that it leads to novel polynomial-time algorithms for multiplying circuits respecting different vtrees, as well as a practical depth-reduction algorithm that preserves structured decomposibility. Our work opens up new avenues for tractable PC inference, suggesting the possibility of training with less restrictive PC structures while enabling efficient inference by changing their structures at inference time.
PREMAP: A Unifying PREiMage APproximation Framework for Neural Networks
Aug 17, 2024Most methods for neural network verification focus on bounding the image, i.e., set of outputs for a given input set. This can be used to, for example, check the robustness of neural network predictions to bounded perturbations of an input. However, verifying properties concerning the preimage, i.e., the set of inputs satisfying an output property, requires abstractions in the input space. We present a general framework for preimage abstraction that produces under- and over-approximations of any polyhedral output set. Our framework employs cheap parameterised linear relaxations of the neural network, together with an anytime refinement procedure that iteratively partitions the input region by splitting on input features and neurons. The effectiveness of our approach relies on carefully designed heuristics and optimization objectives to achieve rapid improvements in the approximation volume. We evaluate our method on a range of tasks, demonstrating significant improvement in efficiency and scalability to high-input-dimensional image classification tasks compared to state-of-the-art techniques. Further, we showcase the application to quantitative verification and robustness analysis, presenting a sound and complete algorithm for the former and providing sound quantitative results for the latter.
Where is the signal in tokenization space?
Aug 16, 2024



Large Language Models (LLMs) are typically shipped with tokenizers that deterministically encode text into so-called canonical token sequences, to which the LLMs assign probability values. One common assumption is that the probability of a piece of text is the probability of its canonical token sequence. However, the tokenization of a string is not unique: e.g., the Llama2 tokenizer encodes Tokens as [Tok,ens], but [Tok,en,s] also represents the same text. In this paper, we study non-canonical tokenizations. We prove that, given a string, it is computationally hard to find the most likely tokenization for an autoregressive LLM, as well as to compute the marginal probability over all possible tokenizations. We then show how the marginal is, in most cases, indistinguishable from the canonical probability. Surprisingly, we then empirically demonstrate the existence of a significant amount of signal hidden within tokenization space. Notably, by simply aggregating the probabilities of non-canonical tokenizations, we achieve improvements across a range of LLM evaluation benchmarks for a variety of architectures, including transformers and state space models.
Probabilistic Circuits for Cumulative Distribution Functions
Aug 08, 2024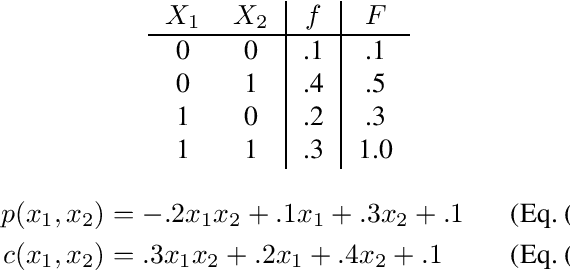
A probabilistic circuit (PC) succinctly expresses a function that represents a multivariate probability distribution and, given sufficient structural properties of the circuit, supports efficient probabilistic inference. Typically a PC computes the probability mass (or density) function (PMF or PDF) of the distribution. We consider PCs instead computing the cumulative distribution function (CDF). We show that for distributions over binary random variables these representations (PMF and CDF) are essentially equivalent, in the sense that one can be transformed to the other in polynomial time. We then show how a similar equivalence holds for distributions over finite discrete variables using a modification of the standard encoding with binary variables that aligns with the CDF semantics. Finally we show that for continuous variables, smooth, decomposable PCs computing PDFs and CDFs can be efficiently transformed to each other by modifying only the leaves of the circuit.
On the Relationship Between Monotone and Squared Probabilistic Circuits
Aug 01, 2024Probabilistic circuits are a unifying representation of functions as computation graphs of weighted sums and products. Their primary application is in probabilistic modeling, where circuits with non-negative weights (monotone circuits) can be used to represent and learn density/mass functions, with tractable marginal inference. Recently, it was proposed to instead represent densities as the square of the circuit function (squared circuits); this allows the use of negative weights while retaining tractability, and can be exponentially more compact than monotone circuits. Unfortunately, we show the reverse also holds, meaning that monotone circuits and squared circuits are incomparable in general. This raises the question of whether we can reconcile, and indeed improve upon the two modeling approaches. We answer in the positive by proposing InceptionPCs, a novel type of circuit that naturally encompasses both monotone circuits and squared circuits as special cases, and employs complex parameters. Empirically, we validate that InceptionPCs can outperform both monotone and squared circuits on image datasets.