 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Bias in Locally Constrained Decoding via Tractable Proposals
Jun 01, 2026Generations from large language models often fail to conform to desired constraints such as JSON schema. Existing locally constrained decoding (LCD) approaches enforce constraints by myopically masking out next tokens, resulting in biased sampling and degradation in performance. Recent work uses sequential Monte Carlo (SMC) methods to mitigate such biases, but designing effective proposal distributions or potential functions remains a key challenge. In this work, we propose a generic approach to construct proposals and potentials for SMC sampling from $p_{\mathrm{lm}}( \cdot \mid \mathrm{constraint})$. First, we show that constraints specified as finite automata can be tensorized for efficient execution on GPUs, which we use to construct globally constrained decoding (GCD) proposals. In addition, leveraging the fact that tensorized finite automata share the same circuit structure as hidden Markov models, we circuit-multiply them to obtain the probabilistic GCD (P-GCD) proposals encoding both logical and probabilistic information about the target distributions. We evaluate (P-)GCD on the tasks of function calling, keyword-based generation, and SQL generation. Experiments show that under the same SMC sampling setup, compared to LCD proposals, (P-)GCD converges faster to the target distribution with significantly fewer particles.
Scaling Probabilistic Circuits via Monarch Matrices
Jun 14, 2025Probabilistic Circuits (PCs) are tractable representations of probability distributions allowing for exact and efficient computation of likelihoods and marginals. Recent advancements have improved the scalability of PCs either by leveraging their sparse properties or through the use of tensorized operations for better hardware utilization. However, no existing method fully exploits both aspects simultaneously. In this paper, we propose a novel sparse and structured parameterization for the sum blocks in PCs. By replacing dense matrices with sparse Monarch matrices, we significantly reduce the memory and computation costs, enabling unprecedented scaling of PCs. From a theory perspective, our construction arises naturally from circuit multiplication; from a practical perspective, compared to previous efforts on scaling up tractable probabilistic models, our approach not only achieves state-of-the-art generative modeling performance on challenging benchmarks like Text8, LM1B and ImageNet, but also demonstrates superior scaling behavior, achieving the same performance with substantially less compute as measured by the number of floating-point operations (FLOPs) during training.
Restructuring Tractable Probabilistic Circuits
Nov 19, 2024Probabilistic circuits (PCs) is a unifying representation for probabilistic models that support tractable inference. Numerous applications of PCs like controllable text generation depend on the ability to efficiently multiply two circuits. Existing multiplication algorithms require that the circuits respect the same structure, i.e. variable scopes decomposes according to the same vtree. In this work, we propose and study the task of restructuring structured(-decomposable) PCs, that is, transforming a structured PC such that it conforms to a target vtree. We propose a generic approach for this problem and show that it leads to novel polynomial-time algorithms for multiplying circuits respecting different vtrees, as well as a practical depth-reduction algorithm that preserves structured decomposibility. Our work opens up new avenues for tractable PC inference, suggesting the possibility of training with less restrictive PC structures while enabling efficient inference by changing their structures at inference time.
Where is the signal in tokenization space?
Aug 16, 2024



Large Language Models (LLMs) are typically shipped with tokenizers that deterministically encode text into so-called canonical token sequences, to which the LLMs assign probability values. One common assumption is that the probability of a piece of text is the probability of its canonical token sequence. However, the tokenization of a string is not unique: e.g., the Llama2 tokenizer encodes Tokens as [Tok,ens], but [Tok,en,s] also represents the same text. In this paper, we study non-canonical tokenizations. We prove that, given a string, it is computationally hard to find the most likely tokenization for an autoregressive LLM, as well as to compute the marginal probability over all possible tokenizations. We then show how the marginal is, in most cases, indistinguishable from the canonical probability. Surprisingly, we then empirically demonstrate the existence of a significant amount of signal hidden within tokenization space. Notably, by simply aggregating the probabilities of non-canonical tokenizations, we achieve improvements across a range of LLM evaluation benchmarks for a variety of architectures, including transformers and state space models.
Adaptable Logical Control for Large Language Models
Jun 19, 2024



Despite the success of Large Language Models (LLMs) on various tasks following human instructions, controlling model generation at inference time poses a persistent challenge. In this paper, we introduce Ctrl-G, an adaptable framework that facilitates tractable and flexible control of LLM generation to reliably follow logical constraints. Ctrl-G combines any production-ready LLM with a Hidden Markov Model, enabling LLM outputs to adhere to logical constraints represented as deterministic finite automata. We show that Ctrl-G, when applied to a TULU2-7B model, outperforms GPT3.5 and GPT4 on the task of interactive text editing: specifically, for the task of generating text insertions/continuations following logical constraints, Ctrl-G achieves over 30% higher satisfaction rate in human evaluation compared to GPT4. When applied to medium-size language models (e.g., GPT2-large), Ctrl-G also beats its counterparts for constrained generation by large margins on standard benchmarks. Additionally, as a proof-of-concept study, we experiment Ctrl-G on the Grade School Math benchmark to assist LLM reasoning, foreshadowing the application of Ctrl-G, as well as other constrained generation approaches, beyond traditional language generation tasks.
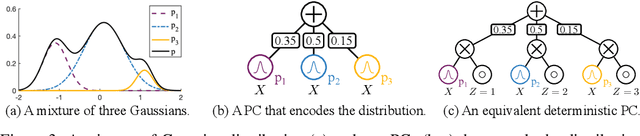
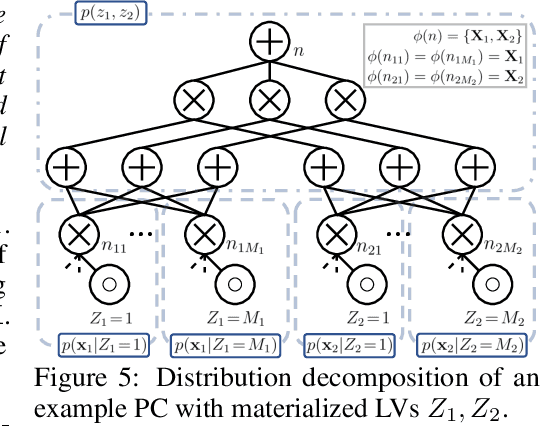
Polynomial Semantics of Tractable Probabilistic Circuits
Feb 14, 2024Probabilistic circuits compute multilinear polynomials that represent probability distributions. They are tractable models that support efficient marginal inference. However, various polynomial semantics have been considered in the literature (e.g., network polynomials, likelihood polynomials, generating functions, Fourier transforms, and characteristic polynomials). The relationships between these polynomial encodings of distributions is largely unknown. In this paper, we prove that for binary distributions, each of these probabilistic circuit models is equivalent in the sense that any circuit for one of them can be transformed into a circuit for any of the others with only a polynomial increase in size. They are therefore all tractable for marginal inference on the same class of distributions. Finally, we explore the natural extension of one such polynomial semantics, called probabilistic generating circuits, to categorical random variables, and establish that marginal inference becomes #P-hard.
Tractable Control for Autoregressive Language Generation
Apr 18, 2023



Despite the success of autoregressive large language models in text generation, it remains a major challenge to generate text that satisfies complex constraints: sampling from the conditional distribution $\Pr(\text{text} | \alpha)$ is intractable for even the simplest lexical constraints $\alpha$. To overcome this challenge, we propose to use tractable probabilistic models to impose lexical constraints in autoregressive text generation, which we refer to as GeLaTo. To demonstrate the effectiveness of this framework, we use distilled hidden Markov models to control autoregressive generation from GPT2. GeLaTo achieves state-of-the-art performance on CommonGen, a challenging benchmark for constrained text generation, beating a wide range of strong baselines by a large margin. Our work not only opens up new avenues for controlling large language models but also motivates the development of more expressive tractable probabilistic models.
Mixtures of All Trees
Feb 27, 2023



Tree-shaped graphical models are widely used for their tractability. However, they unfortunately lack expressive power as they require committing to a particular sparse dependency structure. We propose a novel class of generative models called mixtures of all trees: that is, a mixture over all possible ($n^{n-2}$) tree-shaped graphical models over $n$ variables. We show that it is possible to parameterize this Mixture of All Trees (MoAT) model compactly (using a polynomial-size representation) in a way that allows for tractable likelihood computation and optimization via stochastic gradient descent. Furthermore, by leveraging the tractability of tree-shaped models, we devise fast-converging conditional sampling algorithms for approximate inference, even though our theoretical analysis suggests that exact computation of marginals in the MoAT model is NP-hard. Empirically, MoAT achieves state-of-the-art performance on density estimation benchmarks when compared against powerful probabilistic models including hidden Chow-Liu Trees.
Scaling Up Probabilistic Circuits by Latent Variable Distillation
Oct 10, 2022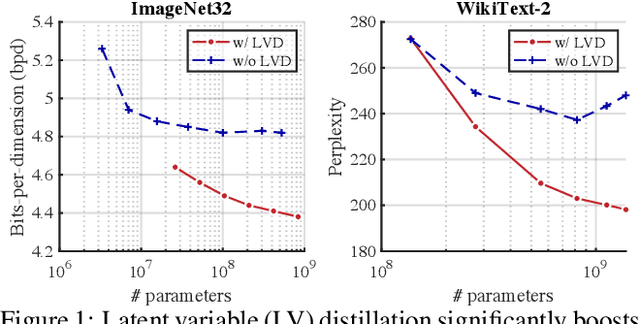
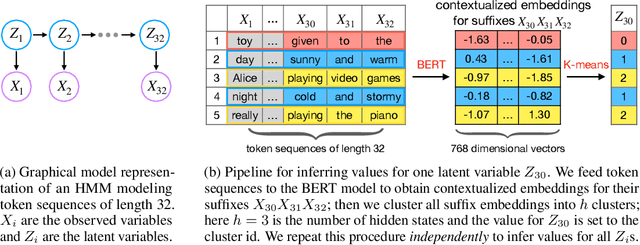
Probabilistic Circuits (PCs) are a unified framework for tractable probabilistic models that support efficient computation of various probabilistic queries (e.g., marginal probabilities). One key challenge is to scale PCs to model large and high-dimensional real-world datasets: we observe that as the number of parameters in PCs increases, their performance immediately plateaus. This phenomenon suggests that the existing optimizers fail to exploit the full expressive power of large PCs. We propose to overcome such bottleneck by latent variable distillation: we leverage the less tractable but more expressive deep generative models to provide extra supervision over the latent variables of PCs. Specifically, we extract information from Transformer-based generative models to assign values to latent variables of PCs, providing guidance to PC optimizers. Experiments on both image and language modeling benchmarks (e.g., ImageNet and WikiText-2) show that latent variable distillation substantially boosts the performance of large PCs compared to their counterparts without latent variable distillation. In particular, on the image modeling benchmarks, PCs achieve competitive performance against some of the widely-used deep generative models, including variational autoencoders and flow-based models, opening up new avenues for tractable generative modeling.
On the Paradox of Learning to Reason from Data
May 24, 2022
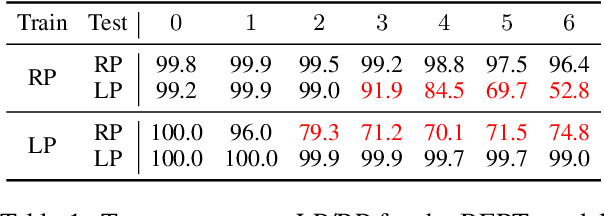
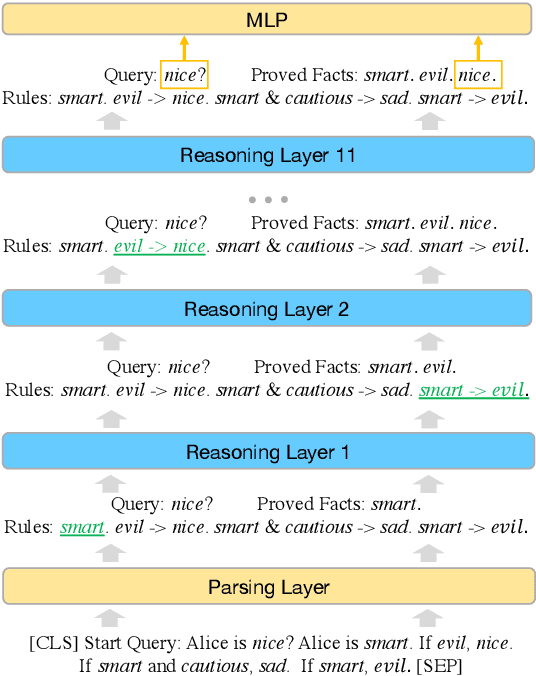

Logical reasoning is needed in a wide range of NLP tasks. Can a BERT model be trained end-to-end to solve logical reasoning problems presented in natural language? We attempt to answer this question in a confined problem space where there exists a set of parameters that perfectly simulates logical reasoning. We make observations that seem to contradict each other: BERT attains near-perfect accuracy on in-distribution test examples while failing to generalize to other data distributions over the exact same problem space. Our study provides an explanation for this paradox: instead of learning to emulate the correct reasoning function, BERT has in fact learned statistical features that inherently exist in logical reasoning problems. We also show that it is infeasible to jointly remove statistical features from data, illustrating the difficulty of learning to reason in general. Our result naturally extends to other neural models and unveils the fundamental difference between learning to reason and learning to achieve high performance on NLP benchmarks using statistical features.