 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Reproducibility Has a Problem Statement Problem
Dec 30, 2025Background. Reproducibility is essential to the scientific method, but reproduction is often a laborious task. Recent works have attempted to automate this process and relieve researchers of this workload. However, due to varying definitions of reproducibility, a clear problem statement is missing. Objectives. Create a generalisable problem statement, applicable to any empirical study. We hypothesise that we can represent any empirical study using a structure based on the scientific method and that this representation can be automatically extracted from any publication, and captures the essence of the study. Methods. We apply our definition of reproducibility as a problem statement for the automatisation of reproducibility by automatically extracting the hypotheses, experiments and interpretations of 20 studies and assess the quality based on assessments by the original authors of each study. Results. We create a dataset representing the reproducibility problem, consisting of the representation of 20 studies. The majority of author feedback is positive, for all parts of the representation. In a few cases, our method failed to capture all elements of the study. We also find room for improvement at capturing specific details, such as results of experiments. Conclusions. We conclude that our formulation of the problem is able to capture the concept of reproducibility in empirical AI studies across a wide range of subfields. Authors of original publications generally agree that the produced structure is representative of their work; we believe improvements can be achieved by applying our findings to create a more structured and fine-grained output in future work.
Combining Automated Optimisation of Hyperparameters and Reward Shape
Jun 26, 2024



There has been significant progress in deep reinforcement learning (RL) in recent years. Nevertheless, finding suitable hyperparameter configurations and reward functions remains challenging even for experts, and performance heavily relies on these design choices. Also, most RL research is conducted on known benchmarks where knowledge about these choices already exists. However, novel practical applications often pose complex tasks for which no prior knowledge about good hyperparameters and reward functions is available, thus necessitating their derivation from scratch. Prior work has examined automatically tuning either hyperparameters or reward functions individually. We demonstrate empirically that an RL algorithm's hyperparameter configurations and reward function are often mutually dependent, meaning neither can be fully optimised without appropriate values for the other. We then propose a methodology for the combined optimisation of hyperparameters and the reward function. Furthermore, we include a variance penalty as an optimisation objective to improve the stability of learned policies. We conducted extensive experiments using Proximal Policy Optimisation and Soft Actor-Critic on four environments. Our results show that combined optimisation significantly improves over baseline performance in half of the environments and achieves competitive performance in the others, with only a minor increase in computational costs. This suggests that combined optimisation should be best practice.
Towards General Negotiation Strategies with End-to-End Reinforcement Learning
Jun 21, 2024The research field of automated negotiation has a long history of designing agents that can negotiate with other agents. Such negotiation strategies are traditionally based on manual design and heuristics. More recently, reinforcement learning approaches have also been used to train agents to negotiate. However, negotiation problems are diverse, causing observation and action dimensions to change, which cannot be handled by default linear policy networks. Previous work on this topic has circumvented this issue either by fixing the negotiation problem, causing policies to be non-transferable between negotiation problems or by abstracting the observations and actions into fixed-size representations, causing loss of information and expressiveness due to feature design. We developed an end-to-end reinforcement learning method for diverse negotiation problems by representing observations and actions as a graph and applying graph neural networks in the policy. With empirical evaluations, we show that our method is effective and that we can learn to negotiate with other agents on never-before-seen negotiation problems. Our result opens up new opportunities for reinforcement learning in negotiation agents.
Automated Design of Linear Bounding Functions for Sigmoidal Nonlinearities in Neural Networks
Jun 14, 2024The ubiquity of deep learning algorithms in various applications has amplified the need for assuring their robustness against small input perturbations such as those occurring in adversarial attacks. Existing complete verification techniques offer provable guarantees for all robustness queries but struggle to scale beyond small neural networks. To overcome this computational intractability, incomplete verification methods often rely on convex relaxation to over-approximate the nonlinearities in neural networks. Progress in tighter approximations has been achieved for piecewise linear functions. However, robustness verification of neural networks for general activation functions (e.g., Sigmoid, Tanh) remains under-explored and poses new challenges. Typically, these networks are verified using convex relaxation techniques, which involve computing linear upper and lower bounds of the nonlinear activation functions. In this work, we propose a novel parameter search method to improve the quality of these linear approximations. Specifically, we show that using a simple search method, carefully adapted to the given verification problem through state-of-the-art algorithm configuration techniques, improves the average global lower bound by 25% on average over the current state of the art on several commonly used local robustness verification benchmarks.
Competitions in AI -- Robustly Ranking Solvers Using Statistical Resampling
Aug 09, 2023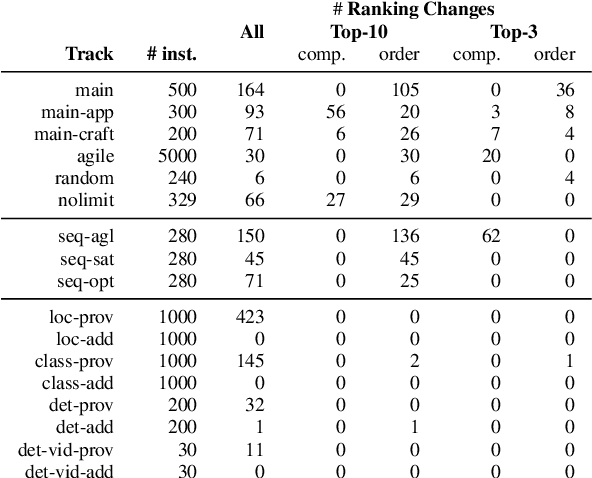
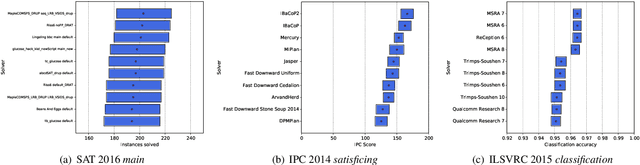
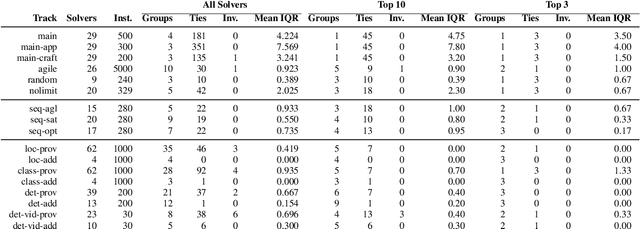

Solver competitions play a prominent role in assessing and advancing the state of the art for solving many problems in AI and beyond. Notably, in many areas of AI, competitions have had substantial impact in guiding research and applications for many years, and for a solver to be ranked highly in a competition carries considerable weight. But to which extent can we expect competition results to generalise to sets of problem instances different from those used in a particular competition? This is the question we investigate here, using statistical resampling techniques. We show that the rankings resulting from the standard interpretation of competition results can be very sensitive to even minor changes in the benchmark instance set used as the basis for assessment and can therefore not be expected to carry over to other samples from the same underlying instance distribution. To address this problem, we introduce a novel approach to statistically meaningful analysis of competition results based on resampling performance data. Our approach produces confidence intervals of competition scores as well as statistically robust solver rankings with bounded error. Applied to recent SAT, AI planning and computer vision competitions, our analysis reveals frequent statistical ties in solver performance as well as some inversions of ranks compared to the official results based on simple scoring.
Artificial intelligence to advance Earth observation: a perspective
May 15, 2023Earth observation (EO) is a prime instrument for monitoring land and ocean processes, studying the dynamics at work, and taking the pulse of our planet. This article gives a bird's eye view of the essential scientific tools and approaches informing and supporting the transition from raw EO data to usable EO-based information. The promises, as well as the current challenges of these developments, are highlighted under dedicated sections. Specifically, we cover the impact of (i) Computer vision; (ii) Machine learning; (iii) Advanced processing and computing; (iv) Knowledge-based AI; (v) Explainable AI and causal inference; (vi) Physics-aware models; (vii) User-centric approaches; and (viii) the much-needed discussion of ethical and societal issues related to the massive use of ML technologies in EO.
Frugal Machine Learning
Nov 05, 2021
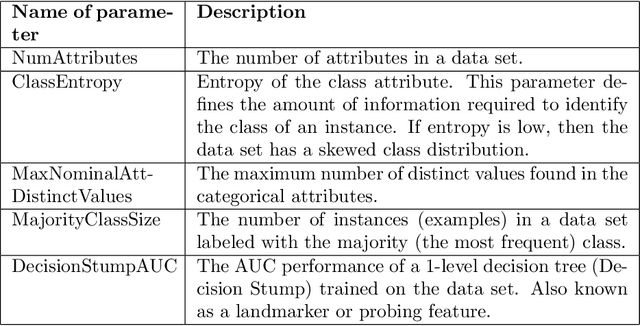
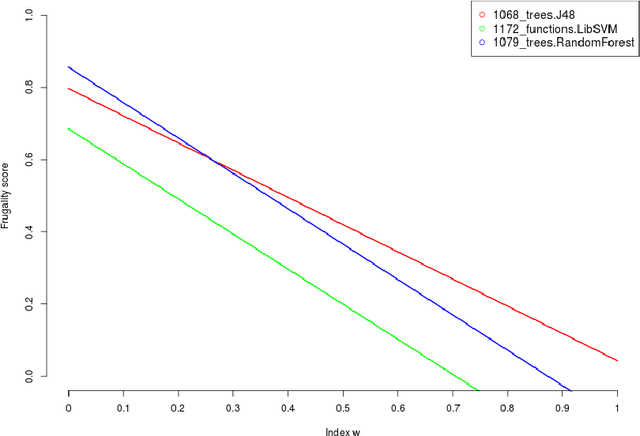
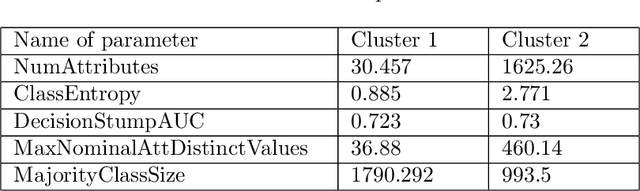
Machine learning, already at the core of increasingly many systems and applications, is set to become even more ubiquitous with the rapid rise of wearable devices and the Internet of Things. In most machine learning applications, the main focus is on the quality of the results achieved (e.g., prediction accuracy), and hence vast amounts of data are being collected, requiring significant computational resources to build models. In many scenarios, however, it is infeasible or impractical to set up large centralized data repositories. In personal health, for instance, privacy issues may inhibit the sharing of detailed personal data. In such cases, machine learning should ideally be performed on wearable devices themselves, which raises major computational limitations such as the battery capacity of smartwatches. This paper thus investigates frugal learning, aimed to build the most accurate possible models using the least amount of resources. A wide range of learning algorithms is examined through a frugal lens, analyzing their accuracy/runtime performance on a wide range of data sets. The most promising algorithms are thereafter assessed in a real-world scenario by implementing them in a smartwatch and letting them learn activity recognition models on the watch itself.
Automating Data Science: Prospects and Challenges
May 12, 2021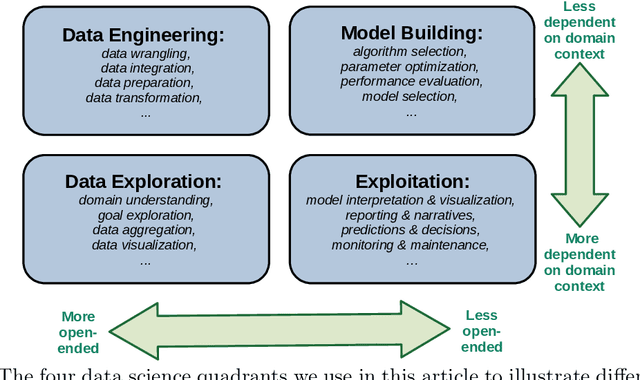

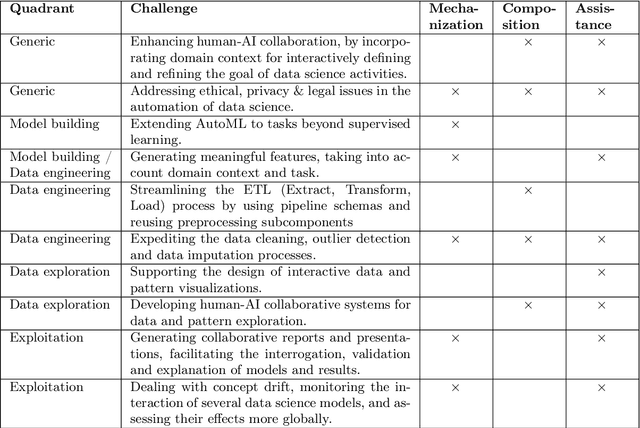
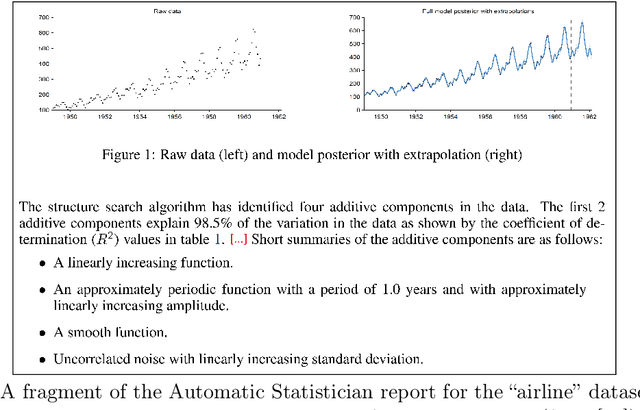
Given the complexity of typical data science projects and the associated demand for human expertise, automation has the potential to transform the data science process. Key insights: * Automation in data science aims to facilitate and transform the work of data scientists, not to replace them. * Important parts of data science are already being automated, especially in the modeling stages, where techniques such as automated machine learning (AutoML) are gaining traction. * Other aspects are harder to automate, not only because of technological challenges, but because open-ended and context-dependent tasks require human interaction.
Automated Configuration of Negotiation Strategies
Mar 31, 2020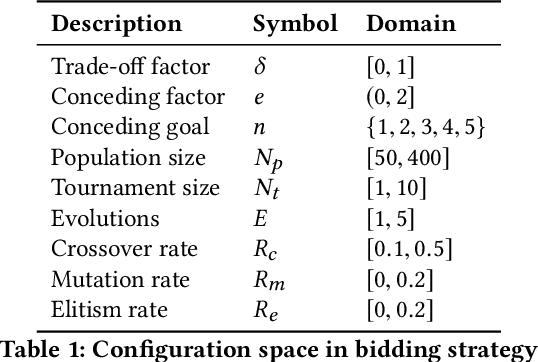
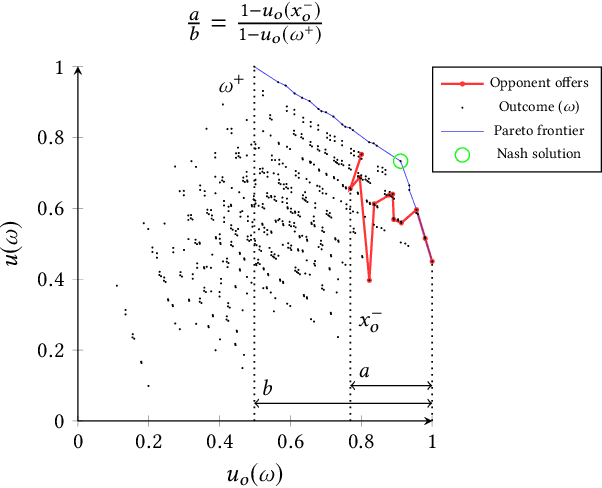
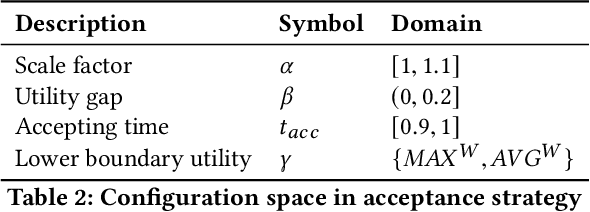
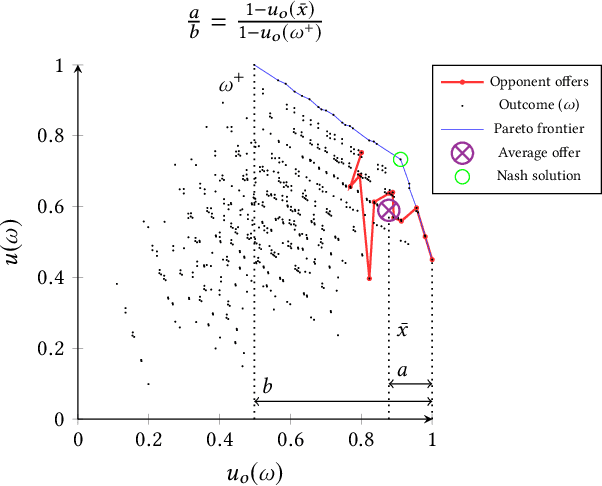
Bidding and acceptance strategies have a substantial impact on the outcome of negotiations in scenarios with linear additive and nonlinear utility functions. Over the years, it has become clear that there is no single best strategy for all negotiation settings, yet many fixed strategies are still being developed. We envision a shift in the strategy design question from: What is a good strategy?, towards: What could be a good strategy? For this purpose, we developed a method leveraging automated algorithm configuration to find the best strategies for a specific set of negotiation settings. By empowering automated negotiating agents using automated algorithm configuration, we obtain a flexible negotiation agent that can be configured automatically for a rich space of opponents and negotiation scenarios. To critically assess our approach, the agent was tested in an ANAC-like bilateral automated negotiation tournament setting against past competitors. We show that our automatically configured agent outperforms all other agents, with a 5.1% increase in negotiation payoff compared to the next-best agent. We note that without our agent in the tournament, the top-ranked agent wins by a margin of only 0.01%.
Improving the Performance of Stochastic Local Search for Maximum Vertex Weight Clique Problem Using Programming by Optimization
Feb 27, 2020
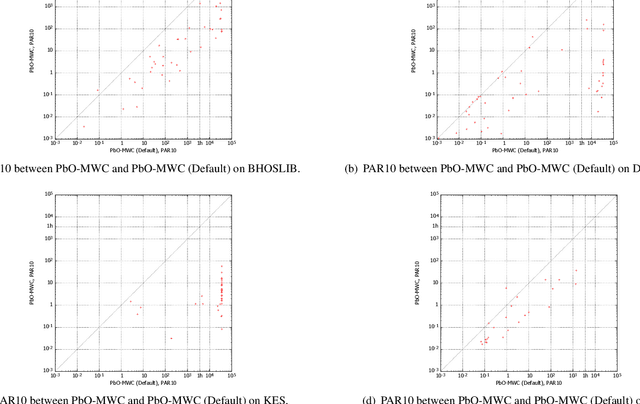


The maximum vertex weight clique problem (MVWCP) is an important generalization of the maximum clique problem (MCP) that has a wide range of real-world applications. In situations where rigorous guarantees regarding the optimality of solutions are not required, MVWCP is usually solved using stochastic local search (SLS) algorithms, which also define the state of the art for solving this problem. However, there is no single SLS algorithm which gives the best performance across all classes of MVWCP instances, and it is challenging to effectively identify the most suitable algorithm for each class of MVWCP instances. In this work, we follow the paradigm of Programming by Optimization (PbO) to develop a new, flexible and highly parametric SLS framework for solving MVWCP, combining, for the first time, a broad range of effective heuristic mechanisms. By automatically configuring this PbO-MWC framework, we achieve substantial advances in the state-of-the-art in solving MVWCP over a broad range of prominent benchmarks, including two derived from real-world applications in transplantation medicine (kidney exchange) and assessment of research excellence.