 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards General Negotiation Strategies with End-to-End Reinforcement Learning
Jun 21, 2024The research field of automated negotiation has a long history of designing agents that can negotiate with other agents. Such negotiation strategies are traditionally based on manual design and heuristics. More recently, reinforcement learning approaches have also been used to train agents to negotiate. However, negotiation problems are diverse, causing observation and action dimensions to change, which cannot be handled by default linear policy networks. Previous work on this topic has circumvented this issue either by fixing the negotiation problem, causing policies to be non-transferable between negotiation problems or by abstracting the observations and actions into fixed-size representations, causing loss of information and expressiveness due to feature design. We developed an end-to-end reinforcement learning method for diverse negotiation problems by representing observations and actions as a graph and applying graph neural networks in the policy. With empirical evaluations, we show that our method is effective and that we can learn to negotiate with other agents on never-before-seen negotiation problems. Our result opens up new opportunities for reinforcement learning in negotiation agents.
Automated Configuration of Negotiation Strategies
Mar 31, 2020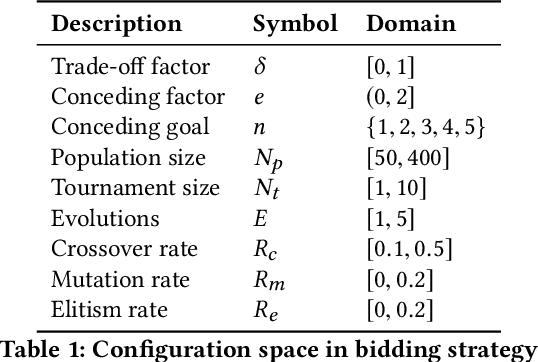
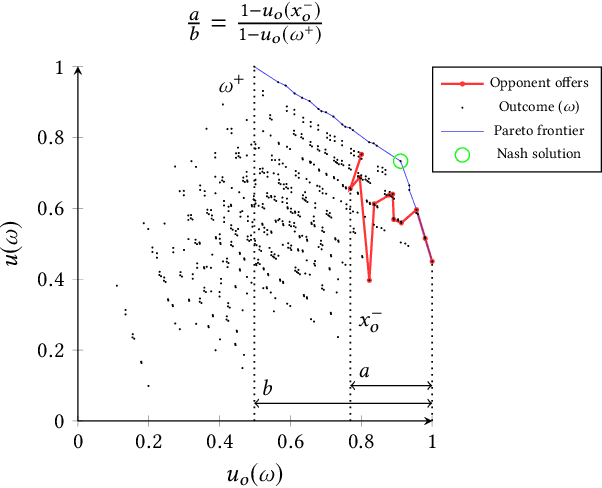
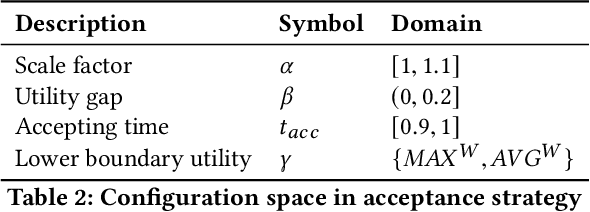
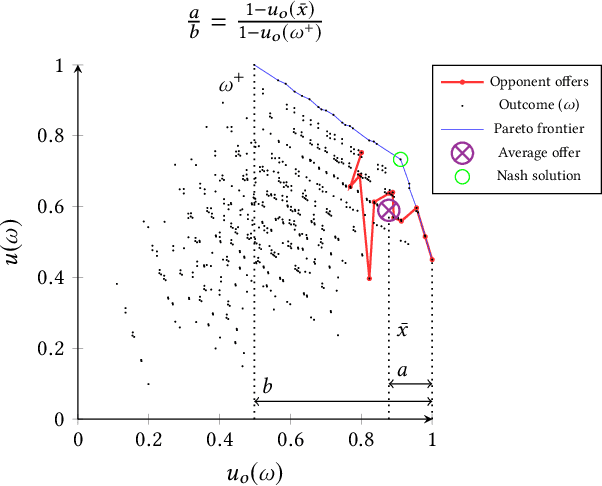
Bidding and acceptance strategies have a substantial impact on the outcome of negotiations in scenarios with linear additive and nonlinear utility functions. Over the years, it has become clear that there is no single best strategy for all negotiation settings, yet many fixed strategies are still being developed. We envision a shift in the strategy design question from: What is a good strategy?, towards: What could be a good strategy? For this purpose, we developed a method leveraging automated algorithm configuration to find the best strategies for a specific set of negotiation settings. By empowering automated negotiating agents using automated algorithm configuration, we obtain a flexible negotiation agent that can be configured automatically for a rich space of opponents and negotiation scenarios. To critically assess our approach, the agent was tested in an ANAC-like bilateral automated negotiation tournament setting against past competitors. We show that our automatically configured agent outperforms all other agents, with a 5.1% increase in negotiation payoff compared to the next-best agent. We note that without our agent in the tournament, the top-ranked agent wins by a margin of only 0.01%.