 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepProofLog: Efficient Proving in Deep Stochastic Logic Programs
Nov 11, 2025Neurosymbolic (NeSy) AI aims to combine the strengths of neural architectures and symbolic reasoning to improve the accuracy, interpretability, and generalization capability of AI models. While logic inference on top of subsymbolic modules has been shown to effectively guarantee these properties, this often comes at the cost of reduced scalability, which can severely limit the usability of NeSy models. This paper introduces DeepProofLog (DPrL), a novel NeSy system based on stochastic logic programs, which addresses the scalability limitations of previous methods. DPrL parameterizes all derivation steps with neural networks, allowing efficient neural guidance over the proving system. Additionally, we establish a formal mapping between the resolution process of our deep stochastic logic programs and Markov Decision Processes, enabling the application of dynamic programming and reinforcement learning techniques for efficient inference and learning. This theoretical connection improves scalability for complex proof spaces and large knowledge bases. Our experiments on standard NeSy benchmarks and knowledge graph reasoning tasks demonstrate that DPrL outperforms existing state-of-the-art NeSy systems, advancing scalability to larger and more complex settings than previously possible.
DeepGraphLog for Layered Neurosymbolic AI
Sep 09, 2025Neurosymbolic AI (NeSy) aims to integrate the statistical strengths of neural networks with the interpretability and structure of symbolic reasoning. However, current NeSy frameworks like DeepProbLog enforce a fixed flow where symbolic reasoning always follows neural processing. This restricts their ability to model complex dependencies, especially in irregular data structures such as graphs. In this work, we introduce DeepGraphLog, a novel NeSy framework that extends ProbLog with Graph Neural Predicates. DeepGraphLog enables multi-layer neural-symbolic reasoning, allowing neural and symbolic components to be layered in arbitrary order. In contrast to DeepProbLog, which cannot handle symbolic reasoning via neural methods, DeepGraphLog treats symbolic representations as graphs, enabling them to be processed by Graph Neural Networks (GNNs). We showcase the capabilities of DeepGraphLog on tasks in planning, knowledge graph completion with distant supervision, and GNN expressivity. Our results demonstrate that DeepGraphLog effectively captures complex relational dependencies, overcoming key limitations of existing NeSy systems. By broadening the applicability of neurosymbolic AI to graph-structured domains, DeepGraphLog offers a more expressive and flexible framework for neural-symbolic integration.
Have Large Language Models Learned to Reason? A Characterization via 3-SAT Phase Transition
Apr 04, 2025Large Language Models (LLMs) have been touted as AI models possessing advanced reasoning abilities. In theory, autoregressive LLMs with Chain-of-Thought (CoT) can perform more serial computations to solve complex reasoning tasks. However, recent studies suggest that, despite this capacity, LLMs do not truly learn to reason but instead fit on statistical features. To study the reasoning capabilities in a principled fashion, we adopt a computational theory perspective and propose an experimental protocol centered on 3-SAT -- the prototypical NP-complete problem lying at the core of logical reasoning and constraint satisfaction tasks. Specifically, we examine the phase transitions in random 3-SAT and characterize the reasoning abilities of state-of-the-art LLMs by varying the inherent hardness of the problem instances. By comparing DeepSeek R1 with other LLMs, our findings reveal two key insights (1) LLM accuracy drops significantly on harder instances, suggesting all current models struggle when statistical shortcuts are unavailable (2) Unlike other LLMs, R1 shows signs of having learned the underlying reasoning. Following a principled experimental protocol, our study moves beyond the benchmark-driven evidence often found in LLM reasoning research. Our findings highlight important gaps and suggest clear directions for future research.
Valid Text-to-SQL Generation with Unification-based DeepStochLog
Mar 17, 2025Large language models have been used to translate natural language questions to SQL queries. Without hard constraints on syntax and database schema, they occasionally produce invalid queries that are not executable. These failures limit the usage of these systems in real-life scenarios. We propose a neurosymbolic framework that imposes SQL syntax and schema constraints with unification-based definite clause grammars and thus guarantees the generation of valid queries. Our framework also builds a bi-directional interface to language models to leverage their natural language understanding abilities. The evaluation results on a subset of SQL grammars show that all our output queries are valid. This work is the first step towards extending language models with unification-based grammars. We demonstrate this extension enhances the validity, execution accuracy, and ground truth alignment of the underlying language model by a large margin. Our code is available at https://github.com/ML-KULeuven/deepstochlog-lm.
Neurosymbolic Decision Trees
Mar 11, 2025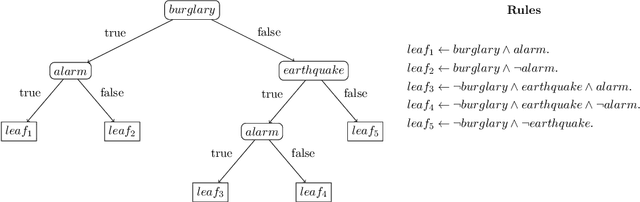
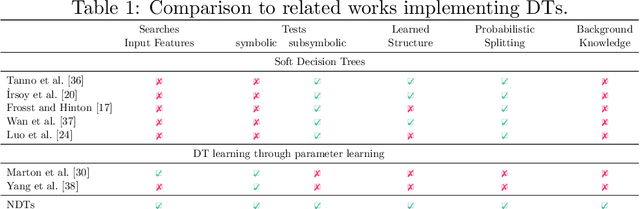
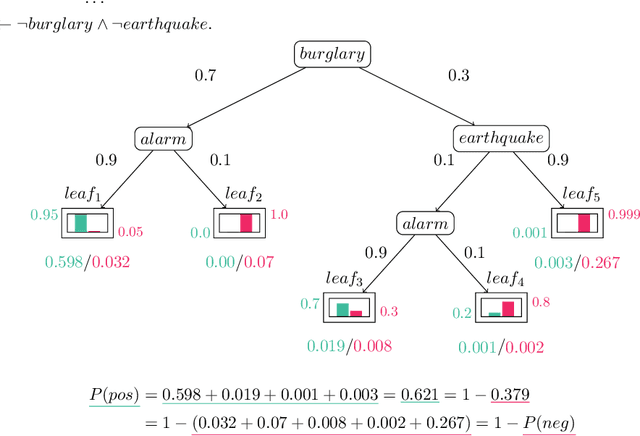
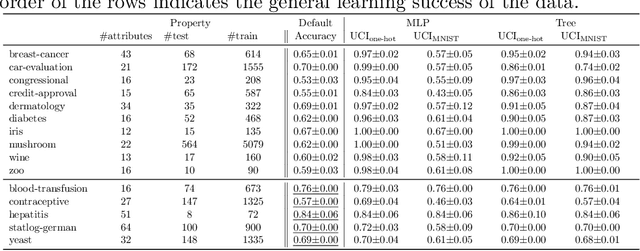
Neurosymbolic (NeSy) AI studies the integration of neural networks (NNs) and symbolic reasoning based on logic. Usually, NeSy techniques focus on learning the neural, probabilistic and/or fuzzy parameters of NeSy models. Learning the symbolic or logical structure of such models has, so far, received less attention. We introduce neurosymbolic decision trees (NDTs), as an extension of decision trees together with a novel NeSy structure learning algorithm, which we dub NeuID3. NeuID3 adapts the standard top-down induction of decision tree algorithms and combines it with a neural probabilistic logic representation, inherited from the DeepProbLog family of models. The key advantage of learning NDTs with NeuID3 is the support of both symbolic and subsymbolic data (such as images), and that they can exploit background knowledge during the induction of the tree structure, In our experimental evaluation we demonstrate the benefits of NeSys structure learning over more traditonal approaches such as purely data-driven learning with neural networks.
The Gradient of Algebraic Model Counting
Feb 25, 2025Algebraic model counting unifies many inference tasks on logic formulas by exploiting semirings. Rather than focusing on inference, we consider learning, especially in statistical-relational and neurosymbolic AI, which combine logical, probabilistic and neural representations. Concretely, we show that the very same semiring perspective of algebraic model counting also applies to learning. This allows us to unify various learning algorithms by generalizing gradients and backpropagation to different semirings. Furthermore, we show how cancellation and ordering properties of a semiring can be exploited for more memory-efficient backpropagation. This allows us to obtain some interesting variations of state-of-the-art gradient-based optimisation methods for probabilistic logical models. We also discuss why algebraic model counting on tractable circuits does not lead to more efficient second-order optimization. Empirically, our algebraic backpropagation exhibits considerable speed-ups as compared to existing approaches.
Relational Neurosymbolic Markov Models
Dec 17, 2024



Sequential problems are ubiquitous in AI, such as in reinforcement learning or natural language processing. State-of-the-art deep sequential models, like transformers, excel in these settings but fail to guarantee the satisfaction of constraints necessary for trustworthy deployment. In contrast, neurosymbolic AI (NeSy) provides a sound formalism to enforce constraints in deep probabilistic models but scales exponentially on sequential problems. To overcome these limitations, we introduce relational neurosymbolic Markov models (NeSy-MMs), a new class of end-to-end differentiable sequential models that integrate and provably satisfy relational logical constraints. We propose a strategy for inference and learning that scales on sequential settings, and that combines approximate Bayesian inference, automated reasoning, and gradient estimation. Our experiments show that NeSy-MMs can solve problems beyond the current state-of-the-art in neurosymbolic AI and still provide strong guarantees with respect to desired properties. Moreover, we show that our models are more interpretable and that constraints can be adapted at test time to out-of-distribution scenarios.
NeSyA: Neurosymbolic Automata
Dec 10, 2024Neurosymbolic Artificial Intelligence (NeSy) has emerged as a promising direction to integrate low level perception with high level reasoning. Unfortunately, little attention has been given to developing NeSy systems tailored to temporal/sequential problems. This entails reasoning symbolically over sequences of subsymbolic observations towards a target prediction. We show that using a probabilistic semantics symbolic automata, which combine the power of automata for temporal structure specification with that of propositional logic, can be used to reason efficiently and differentiably over subsymbolic sequences. The proposed system, which we call NeSyA (Neuro Symbolic Automata), is shown to either scale or perform better than existing NeSy approaches when applied to problems with a temporal component.
EXPLAIN, AGREE, LEARN: Scaling Learning for Neural Probabilistic Logic
Aug 15, 2024



Neural probabilistic logic systems follow the neuro-symbolic (NeSy) paradigm by combining the perceptive and learning capabilities of neural networks with the robustness of probabilistic logic. Learning corresponds to likelihood optimization of the neural networks. However, to obtain the likelihood exactly, expensive probabilistic logic inference is required. To scale learning to more complex systems, we therefore propose to instead optimize a sampling based objective. We prove that the objective has a bounded error with respect to the likelihood, which vanishes when increasing the sample count. Furthermore, the error vanishes faster by exploiting a new concept of sample diversity. We then develop the EXPLAIN, AGREE, LEARN (EXAL) method that uses this objective. EXPLAIN samples explanations for the data. AGREE reweighs each explanation in concordance with the neural component. LEARN uses the reweighed explanations as a signal for learning. In contrast to previous NeSy methods, EXAL can scale to larger problem sizes while retaining theoretical guarantees on the error. Experimentally, our theoretical claims are verified and EXAL outperforms recent NeSy methods when scaling up the MNIST addition and Warcraft pathfinding problems.
Can Large Language Models Reason? A Characterization via 3-SAT
Aug 13, 2024Large Language Models (LLMs) are said to possess advanced reasoning abilities. However, some skepticism exists as recent works show how LLMs often bypass true reasoning using shortcuts. Current methods for assessing the reasoning abilities of LLMs typically rely on open-source benchmarks that may be overrepresented in LLM training data, potentially skewing performance. We instead provide a computational theory perspective of reasoning, using 3-SAT -- the prototypical NP-complete problem that lies at the core of logical reasoning and constraint satisfaction tasks. By examining the phase transitions in 3-SAT, we empirically characterize the reasoning abilities of LLMs and show how they vary with the inherent hardness of the problems. Our experimental evidence shows that LLMs cannot perform true reasoning, as is required for solving 3-SAT problems.