 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTeacher-Student Representational Alignment for Reinforcement Learning-Driven Imitation Learning
May 27, 2026Imitation learning (IL) from a state-based reinforcement learning (RL) policy is a common approach to overcome the curse of dimensionality in complex and high-dimensional observation spaces prevalent in robotics. This paper addresses the irreducible imitation gap that emerges when teacher and student are learned in isolation, and the teacher policy has the liberty to rely on privileged state information that the student cannot infer from its observations. Instead of improving poor student performance with RL finetuning after IL, which often requires a whole new training setup, we propose a novel algorithm which learns a shared embedding space that hides agent-specific observations and thus trains imitable teacher policies by construction. We train the shared embedding space with self-supervised contrastive learning in parallel to the teacher policy and prevent it from extracting private information by limiting its gradients from updating the encoder networks. We perform evaluations on several example domains and compare to state-of-the-art baselines showing that our algorithm enables higher student performance with substantially reduced imitation gap.
COvolve: Adversarial Co-Evolution of Large-Language-Model-Generated Policies and Environments via Two-Player Zero-Sum Game
Mar 30, 2026A central challenge in building continually improving agents is that training environments are typically static or manually constructed. This restricts continual learning and generalization beyond the training distribution. We address this with COvolve, a co-evolutionary framework that leverages large language models (LLMs) to generate both environments and agent policies, expressed as executable Python code. We model the interaction between environment and policy designers as a two-player zero-sum game, ensuring adversarial co-evolution in which environments expose policy weaknesses and policies adapt in response. This process induces an automated curriculum in which environments and policies co-evolve toward increasing complexity. To guarantee robustness and prevent forgetting as the curriculum progresses, we compute the mixed-strategy Nash equilibrium (MSNE) of the zero-sum game, thereby yielding a meta-policy. This MSNE meta-policy ensures that the agent does not forget to solve previously seen environments while learning to solve previously unseen ones. Experiments in urban driving, symbolic maze-solving, and geometric navigation showcase that COvolve produces progressively more complex environments. Our results demonstrate the potential of LLM-driven co-evolution to achieve open-ended learning without predefined task distributions or manual intervention.
Two Constraint Compilation Methods for Lifted Planning
Nov 13, 2025We study planning in a fragment of PDDL with qualitative state-trajectory constraints, capturing safety requirements, task ordering conditions, and intermediate sub-goals commonly found in real-world problems. A prominent approach to tackle such problems is to compile their constraints away, leading to a problem that is supported by state-of-the-art planners. Unfortunately, existing compilers do not scale on problems with a large number of objects and high-arity actions, as they necessitate grounding the problem before compilation. To address this issue, we propose two methods for compiling away constraints without grounding, making them suitable for large-scale planning problems. We prove the correctness of our compilers and outline their worst-case time complexity. Moreover, we present a reproducible empirical evaluation on the domains used in the latest International Planning Competition. Our results demonstrate that our methods are efficient and produce planning specifications that are orders of magnitude more succinct than the ones produced by compilers that ground the domain, while remaining competitive when used for planning with a state-of-the-art planner.
Independence Is Not an Issue in Neurosymbolic AI
Apr 10, 2025


A popular approach to neurosymbolic AI is to take the output of the last layer of a neural network, e.g. a softmax activation, and pass it through a sparse computation graph encoding certain logical constraints one wishes to enforce. This induces a probability distribution over a set of random variables, which happen to be conditionally independent of each other in many commonly used neurosymbolic AI models. Such conditionally independent random variables have been deemed harmful as their presence has been observed to co-occur with a phenomenon dubbed deterministic bias, where systems learn to deterministically prefer one of the valid solutions from the solution space over the others. We provide evidence contesting this conclusion and show that the phenomenon of deterministic bias is an artifact of improperly applying neurosymbolic AI.
Have Large Language Models Learned to Reason? A Characterization via 3-SAT Phase Transition
Apr 04, 2025Large Language Models (LLMs) have been touted as AI models possessing advanced reasoning abilities. In theory, autoregressive LLMs with Chain-of-Thought (CoT) can perform more serial computations to solve complex reasoning tasks. However, recent studies suggest that, despite this capacity, LLMs do not truly learn to reason but instead fit on statistical features. To study the reasoning capabilities in a principled fashion, we adopt a computational theory perspective and propose an experimental protocol centered on 3-SAT -- the prototypical NP-complete problem lying at the core of logical reasoning and constraint satisfaction tasks. Specifically, we examine the phase transitions in random 3-SAT and characterize the reasoning abilities of state-of-the-art LLMs by varying the inherent hardness of the problem instances. By comparing DeepSeek R1 with other LLMs, our findings reveal two key insights (1) LLM accuracy drops significantly on harder instances, suggesting all current models struggle when statistical shortcuts are unavailable (2) Unlike other LLMs, R1 shows signs of having learned the underlying reasoning. Following a principled experimental protocol, our study moves beyond the benchmark-driven evidence often found in LLM reasoning research. Our findings highlight important gaps and suggest clear directions for future research.
Neurosymbolic Decision Trees
Mar 11, 2025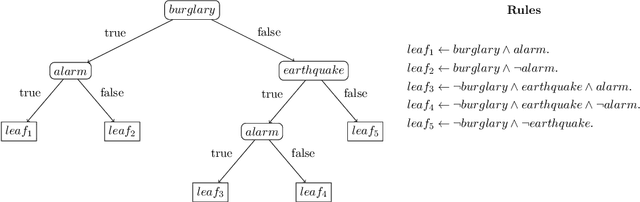
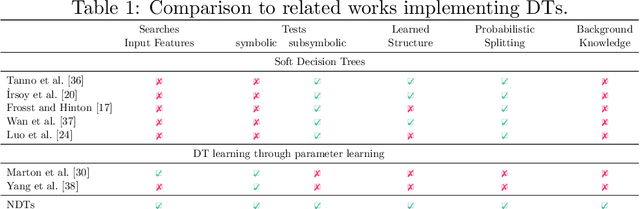
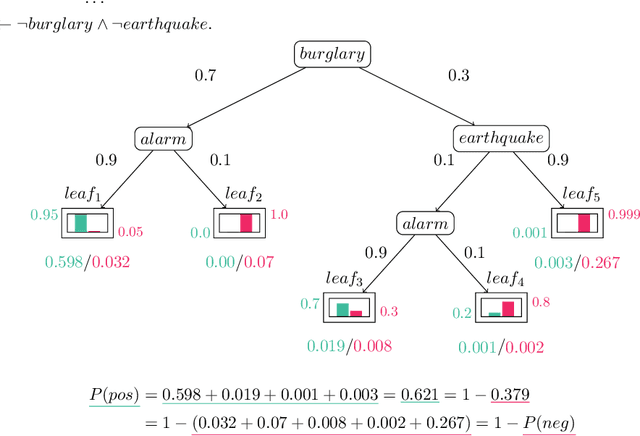
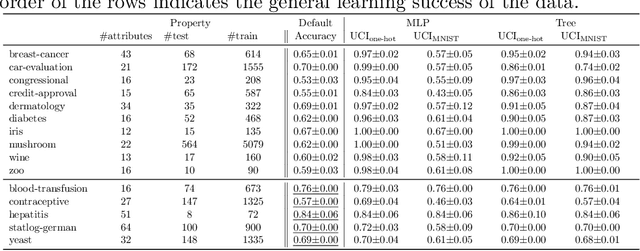
Neurosymbolic (NeSy) AI studies the integration of neural networks (NNs) and symbolic reasoning based on logic. Usually, NeSy techniques focus on learning the neural, probabilistic and/or fuzzy parameters of NeSy models. Learning the symbolic or logical structure of such models has, so far, received less attention. We introduce neurosymbolic decision trees (NDTs), as an extension of decision trees together with a novel NeSy structure learning algorithm, which we dub NeuID3. NeuID3 adapts the standard top-down induction of decision tree algorithms and combines it with a neural probabilistic logic representation, inherited from the DeepProbLog family of models. The key advantage of learning NDTs with NeuID3 is the support of both symbolic and subsymbolic data (such as images), and that they can exploit background knowledge during the induction of the tree structure, In our experimental evaluation we demonstrate the benefits of NeSys structure learning over more traditonal approaches such as purely data-driven learning with neural networks.
A Fast Convoluted Story: Scaling Probabilistic Inference for Integer Arithmetic
Oct 16, 2024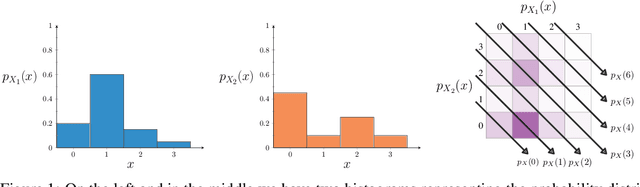
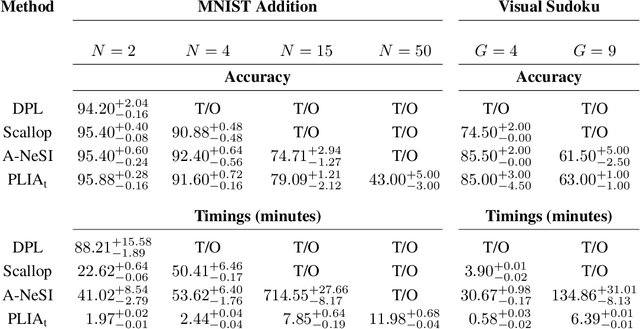
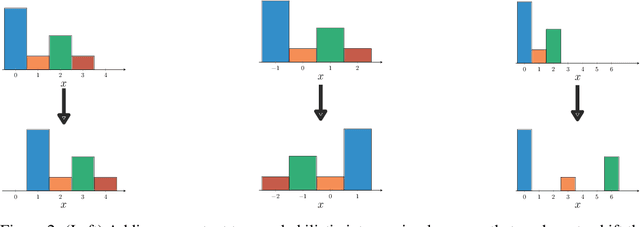

As illustrated by the success of integer linear programming, linear integer arithmetic is a powerful tool for modelling combinatorial problems. Furthermore, the probabilistic extension of linear programming has been used to formulate problems in neurosymbolic AI. However, two key problems persist that prevent the adoption of neurosymbolic techniques beyond toy problems. First, probabilistic inference is inherently hard, #P-hard to be precise. Second, the discrete nature of integers renders the construction of meaningful gradients challenging, which is problematic for learning. In order to mitigate these issues, we formulate linear arithmetic over integer-valued random variables as tensor manipulations that can be implemented in a straightforward fashion using modern deep learning libraries. At the core of our formulation lies the observation that the addition of two integer-valued random variables can be performed by adapting the fast Fourier transform to probabilities in the log-domain. By relying on tensor operations we obtain a differentiable data structure, which unlocks, virtually for free, gradient-based learning. In our experimental validation we show that tensorising probabilistic linear integer arithmetic and leveraging the fast Fourier transform allows us to push the state of the art by several orders of magnitude in terms of inference and learning times.
KLay: Accelerating Neurosymbolic AI
Oct 15, 2024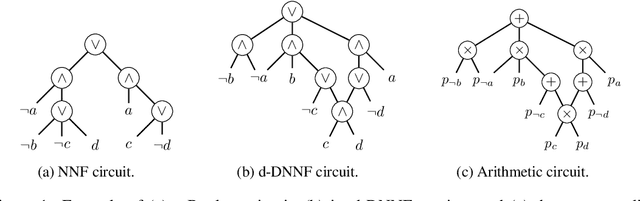
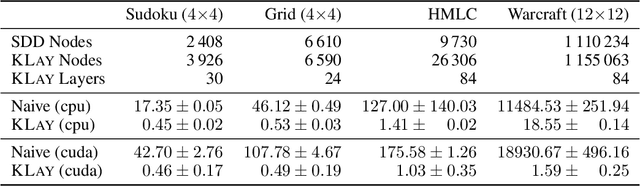
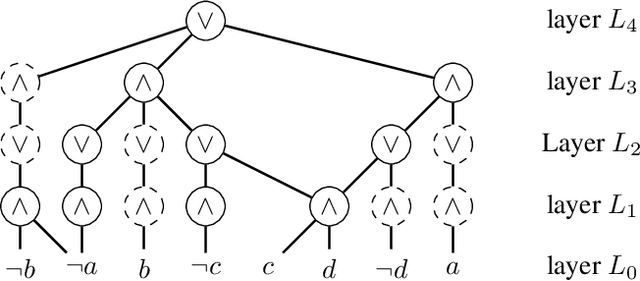

A popular approach to neurosymbolic AI involves mapping logic formulas to arithmetic circuits (computation graphs consisting of sums and products) and passing the outputs of a neural network through these circuits. This approach enforces symbolic constraints onto a neural network in a principled and end-to-end differentiable way. Unfortunately, arithmetic circuits are challenging to run on modern AI accelerators as they exhibit a high degree of irregular sparsity. To address this limitation, we introduce knowledge layers (KLay), a new data structure to represent arithmetic circuits that can be efficiently parallelized on GPUs. Moreover, we contribute two algorithms used in the translation of traditional circuit representations to KLay and a further algorithm that exploits parallelization opportunities during circuit evaluations. We empirically show that KLay achieves speedups of multiple orders of magnitude over the state of the art, thereby paving the way towards scaling neurosymbolic AI to larger real-world applications.
Can Large Language Models Reason? A Characterization via 3-SAT
Aug 13, 2024Large Language Models (LLMs) are said to possess advanced reasoning abilities. However, some skepticism exists as recent works show how LLMs often bypass true reasoning using shortcuts. Current methods for assessing the reasoning abilities of LLMs typically rely on open-source benchmarks that may be overrepresented in LLM training data, potentially skewing performance. We instead provide a computational theory perspective of reasoning, using 3-SAT -- the prototypical NP-complete problem that lies at the core of logical reasoning and constraint satisfaction tasks. By examining the phase transitions in 3-SAT, we empirically characterize the reasoning abilities of LLMs and show how they vary with the inherent hardness of the problems. Our experimental evidence shows that LLMs cannot perform true reasoning, as is required for solving 3-SAT problems.
REvolve: Reward Evolution with Large Language Models for Autonomous Driving
Jun 03, 2024Designing effective reward functions is crucial to training reinforcement learning (RL) algorithms. However, this design is non-trivial, even for domain experts, due to the subjective nature of certain tasks that are hard to quantify explicitly. In recent works, large language models (LLMs) have been used for reward generation from natural language task descriptions, leveraging their extensive instruction tuning and commonsense understanding of human behavior. In this work, we hypothesize that LLMs, guided by human feedback, can be used to formulate human-aligned reward functions. Specifically, we study this in the challenging setting of autonomous driving (AD), wherein notions of "good" driving are tacit and hard to quantify. To this end, we introduce REvolve, an evolutionary framework that uses LLMs for reward design in AD. REvolve creates and refines reward functions by utilizing human feedback to guide the evolution process, effectively translating implicit human knowledge into explicit reward functions for training (deep) RL agents. We demonstrate that agents trained on REvolve-designed rewards align closely with human driving standards, thereby outperforming other state-of-the-art baselines.