 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Double Deep Q-network: Integrating Human Interventions and Evaluative Predictions in Reinforcement Learning of Autonomous Driving
Apr 28, 2025Integrating human expertise with machine learning is crucial for applications demanding high accuracy and safety, such as autonomous driving. This study introduces Interactive Double Deep Q-network (iDDQN), a Human-in-the-Loop (HITL) approach that enhances Reinforcement Learning (RL) by merging human insights directly into the RL training process, improving model performance. Our proposed iDDQN method modifies the Q-value update equation to integrate human and agent actions, establishing a collaborative approach for policy development. Additionally, we present an offline evaluative framework that simulates the agent's trajectory as if no human intervention had occurred, to assess the effectiveness of human interventions. Empirical results in simulated autonomous driving scenarios demonstrate that iDDQN outperforms established approaches, including Behavioral Cloning (BC), HG-DAgger, Deep Q-Learning from Demonstrations (DQfD), and vanilla DRL in leveraging human expertise for improving performance and adaptability.
REvolve: Reward Evolution with Large Language Models for Autonomous Driving
Jun 03, 2024Designing effective reward functions is crucial to training reinforcement learning (RL) algorithms. However, this design is non-trivial, even for domain experts, due to the subjective nature of certain tasks that are hard to quantify explicitly. In recent works, large language models (LLMs) have been used for reward generation from natural language task descriptions, leveraging their extensive instruction tuning and commonsense understanding of human behavior. In this work, we hypothesize that LLMs, guided by human feedback, can be used to formulate human-aligned reward functions. Specifically, we study this in the challenging setting of autonomous driving (AD), wherein notions of "good" driving are tacit and hard to quantify. To this end, we introduce REvolve, an evolutionary framework that uses LLMs for reward design in AD. REvolve creates and refines reward functions by utilizing human feedback to guide the evolution process, effectively translating implicit human knowledge into explicit reward functions for training (deep) RL agents. We demonstrate that agents trained on REvolve-designed rewards align closely with human driving standards, thereby outperforming other state-of-the-art baselines.
Symbolic Learning and Reasoning with Noisy Data for Probabilistic Anchoring
Feb 24, 2020
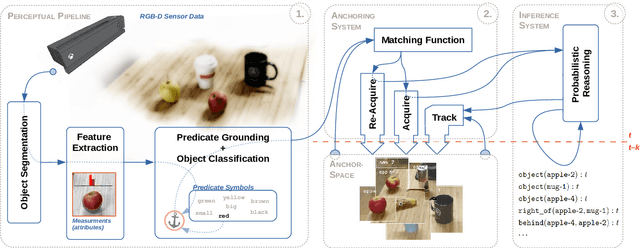


Robotic agents should be able to learn from sub-symbolic sensor data, and at the same time, be able to reason about objects and communicate with humans on a symbolic level. This raises the question of how to overcome the gap between symbolic and sub-symbolic artificial intelligence. We propose a semantic world modeling approach based on bottom-up object anchoring using an object-centered representation of the world. Perceptual anchoring processes continuous perceptual sensor data and maintains a correspondence to a symbolic representation. We extend the definitions of anchoring to handle multi-modal probability distributions and we couple the resulting symbol anchoring system to a probabilistic logic reasoner for performing inference. Furthermore, we use statistical relational learning to enable the anchoring framework to learn symbolic knowledge in the form of a set of probabilistic logic rules of the world from noisy and sub-symbolic sensor input. The resulting framework, which combines perceptual anchoring and statistical relational learning, is able to maintain a semantic world model of all the objects that have been perceived over time, while still exploiting the expressiveness of logical rules to reason about the state of objects which are not directly observed through sensory input data. To validate our approach we demonstrate, on the one hand, the ability of our system to perform probabilistic reasoning over multi-modal probability distributions, and on the other hand, the learning of probabilistic logical rules from anchored objects produced by perceptual observations. The learned logical rules are, subsequently, used to assess our proposed probabilistic anchoring procedure. We demonstrate our system in a setting involving object interactions where object occlusions arise and where probabilistic inference is needed to correctly anchor objects.
Learning from Implicit Information in Natural Language Instructions for Robotic Manipulations
Apr 30, 2019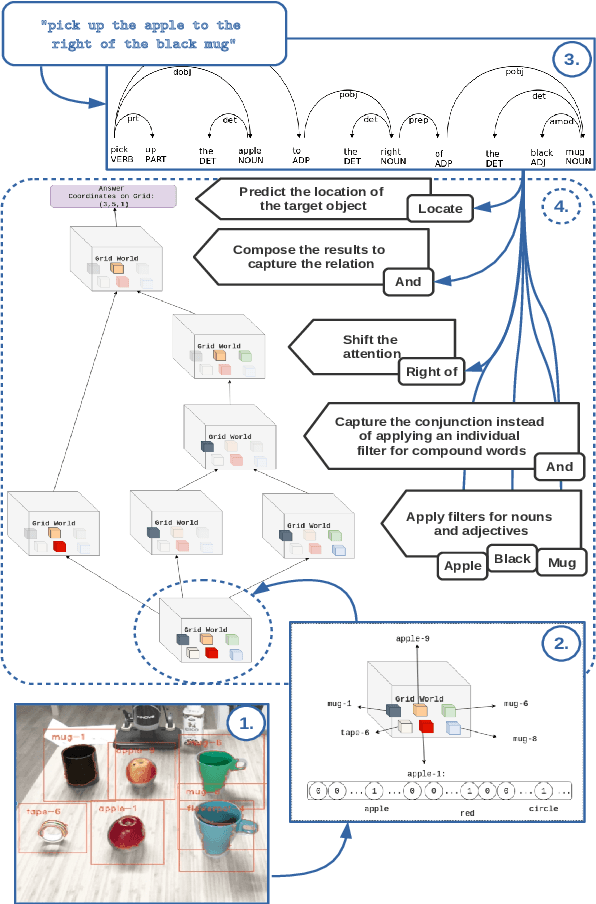
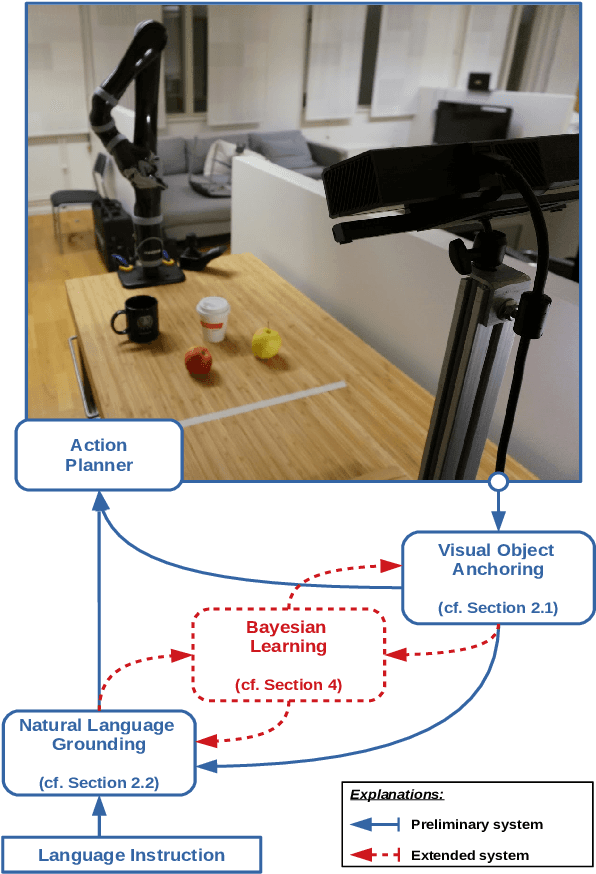
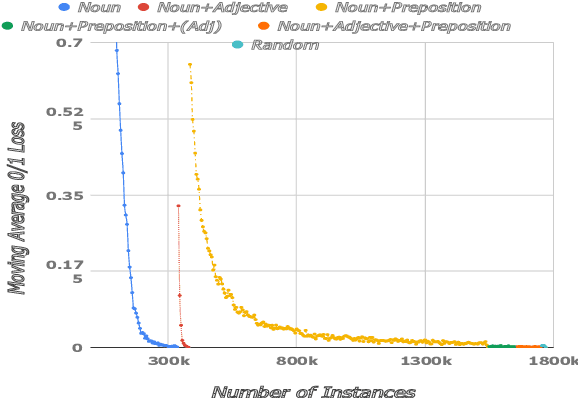

Human-robot interaction often occurs in the form of instructions given from a human to a robot. For a robot to successfully follow instructions, a common representation of the world and objects in it should be shared between humans and the robot so that the instructions can be grounded. Achieving this representation can be done via learning, where both the world representation and the language grounding are learned simultaneously. However, in robotics this can be a difficult task due to the cost and scarcity of data. In this paper, we tackle the problem by separately learning the world representation of the robot and the language grounding. While this approach can address the challenges in getting sufficient data, it may give rise to inconsistencies between both learned components. Therefore, we further propose Bayesian learning to resolve such inconsistencies between the natural language grounding and a robot's world representation by exploiting spatio-relational information that is implicitly present in instructions given by a human. Moreover, we demonstrate the feasibility of our approach on a scenario involving a robotic arm in the physical world.
Semantic Relational Object Tracking
Feb 26, 2019


This paper addresses the topic of semantic world modeling by conjoining probabilistic reasoning and object anchoring. The proposed approach uses a so-called bottom-up object anchoring method that relies on the rich continuous data from perceptual sensor data. A novel anchoring matching function method learns to maintain object entities in space and time and is validated using a large set of trained humanly annotated ground truth data of real-world objects. For more complex scenarios, a high-level probabilistic object tracker has been integrated with the anchoring framework and handles the tracking of occluded objects via reasoning about the state of unobserved objects. We demonstrate the performance of our integrated approach through scenarios such as the shell game scenario, where we illustrate how anchored objects are retained by preserving relations through probabilistic reasoning.