 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiLingUNet: Image Segmentation by Modulating Top-Down and Bottom-Up Visual Processing with Referring Expressions
Mar 28, 2020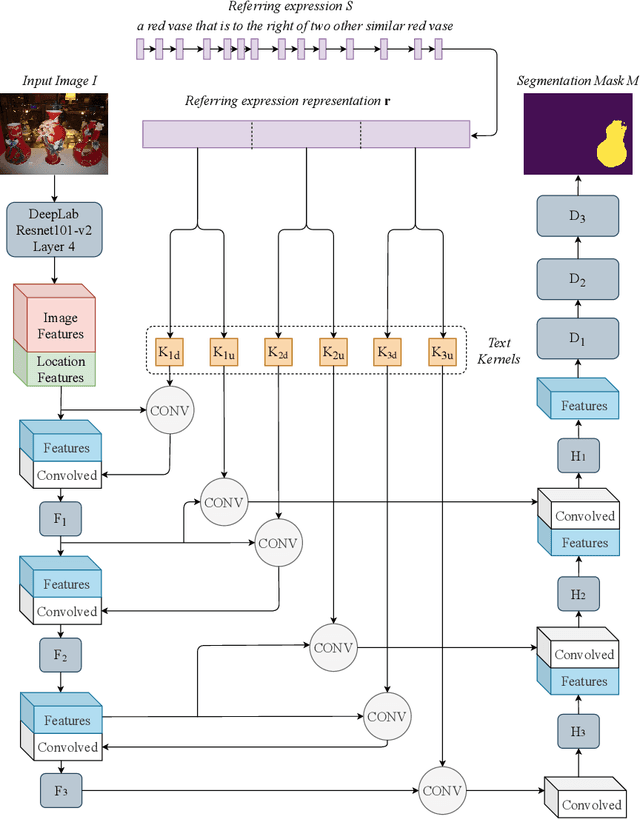
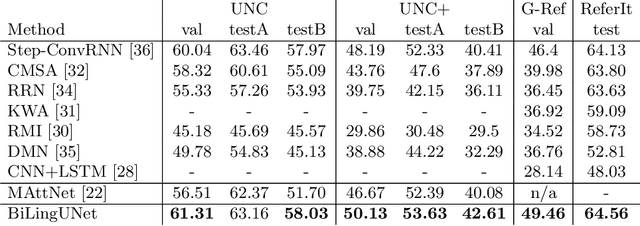
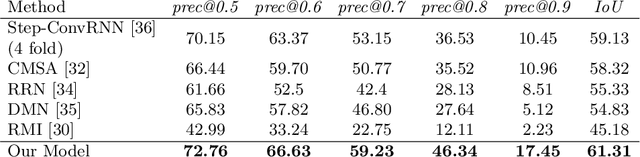

We present BiLingUNet, a state-of-the-art model for image segmentation using referring expressions. BiLingUNet uses language to customize visual filters and outperforms approaches that concatenate a linguistic representation to the visual input. We find that using language to modulate both bottom-up and top-down visual processing works better than just making the top-down processing language-conditional. We argue that common 1x1 language-conditional filters cannot represent relational concepts and experimentally demonstrate that wider filters work better. Our model achieves state-of-the-art performance on four referring expression datasets.
Learning from Implicit Information in Natural Language Instructions for Robotic Manipulations
Apr 30, 2019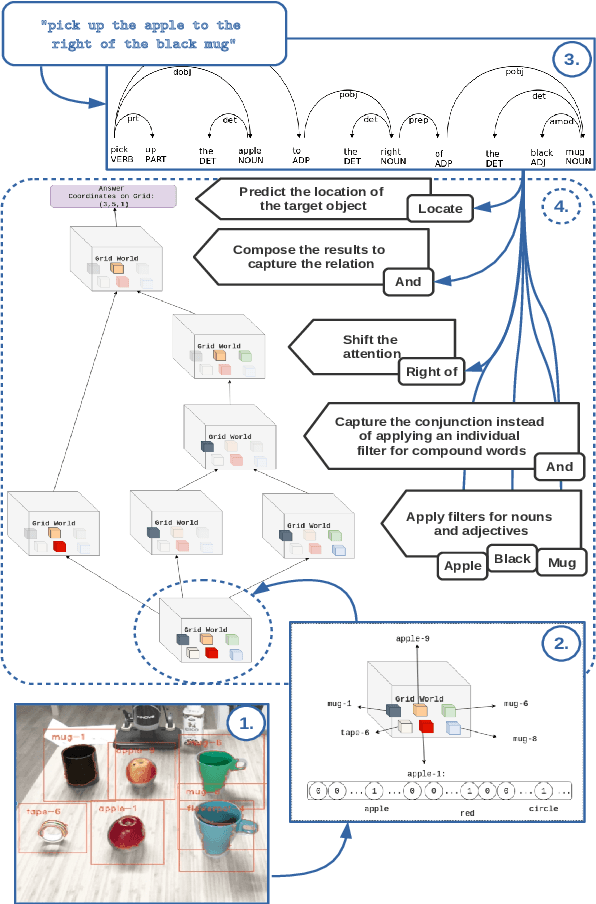
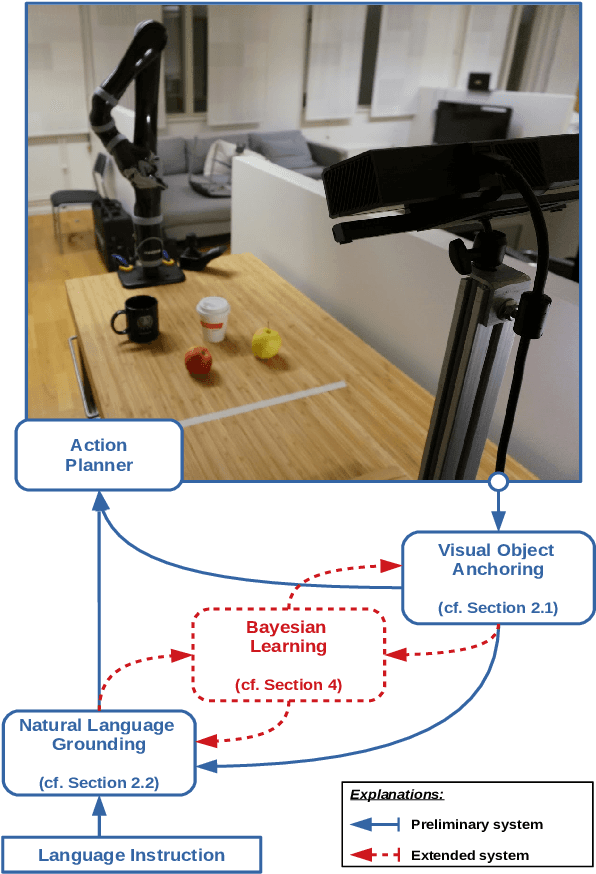
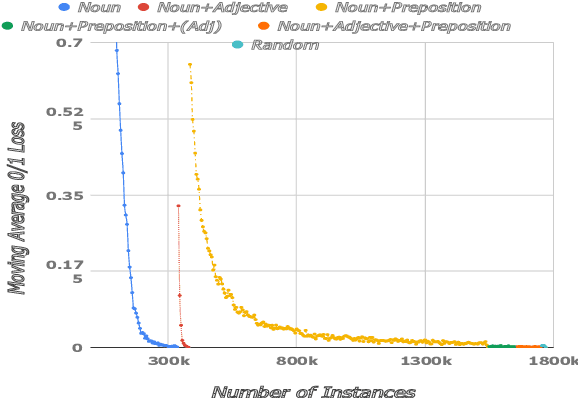

Human-robot interaction often occurs in the form of instructions given from a human to a robot. For a robot to successfully follow instructions, a common representation of the world and objects in it should be shared between humans and the robot so that the instructions can be grounded. Achieving this representation can be done via learning, where both the world representation and the language grounding are learned simultaneously. However, in robotics this can be a difficult task due to the cost and scarcity of data. In this paper, we tackle the problem by separately learning the world representation of the robot and the language grounding. While this approach can address the challenges in getting sufficient data, it may give rise to inconsistencies between both learned components. Therefore, we further propose Bayesian learning to resolve such inconsistencies between the natural language grounding and a robot's world representation by exploiting spatio-relational information that is implicitly present in instructions given by a human. Moreover, we demonstrate the feasibility of our approach on a scenario involving a robotic arm in the physical world.
A new dataset and model for learning to understand navigational instructions
May 21, 2018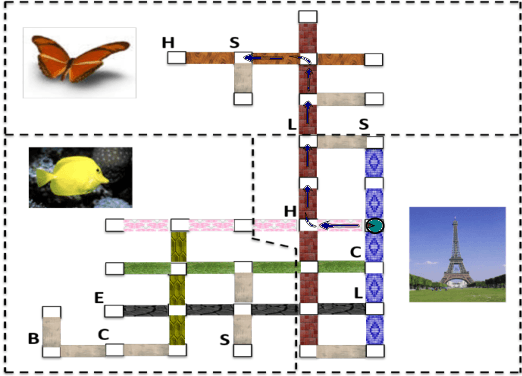



In this paper, we present a state-of-the-art model and introduce a new dataset for grounded language learning. Our goal is to develop a model that can learn to follow new instructions given prior instruction-perception-action examples. We based our work on the SAIL dataset which consists of navigational instructions and actions in a maze-like environment. The new model we propose achieves the best results to date on the SAIL dataset by using an improved perceptual component that can represent relative positions of objects. We also analyze the problems with the SAIL dataset regarding its size and balance. We argue that performance on a small, fixed-size dataset is no longer a good measure to differentiate state-of-the-art models. We introduce SAILx, a synthetic dataset generator, and perform experiments where the size and balance of the dataset are controlled.