 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocations of Characters in Narratives: Andersen and Persuasion Datasets
Apr 04, 2025



The ability of machines to grasp spatial understanding within narrative contexts is an intriguing aspect of reading comprehension that continues to be studied. Motivated by the goal to test the AI's competence in understanding the relationship between characters and their respective locations in narratives, we introduce two new datasets: Andersen and Persuasion. For the Andersen dataset, we selected fifteen children's stories from "Andersen's Fairy Tales" by Hans Christian Andersen and manually annotated the characters and their respective locations throughout each story. Similarly, for the Persuasion dataset, characters and their locations in the novel "Persuasion" by Jane Austen were also manually annotated. We used these datasets to prompt Large Language Models (LLMs). The prompts are created by extracting excerpts from the stories or the novel and combining them with a question asking the location of a character mentioned in that excerpt. Out of the five LLMs we tested, the best-performing one for the Andersen dataset accurately identified the location in 61.85% of the examples, while for the Persuasion dataset, the best-performing one did so in 56.06% of the cases.
How much do LLMs learn from negative examples?
Mar 18, 2025

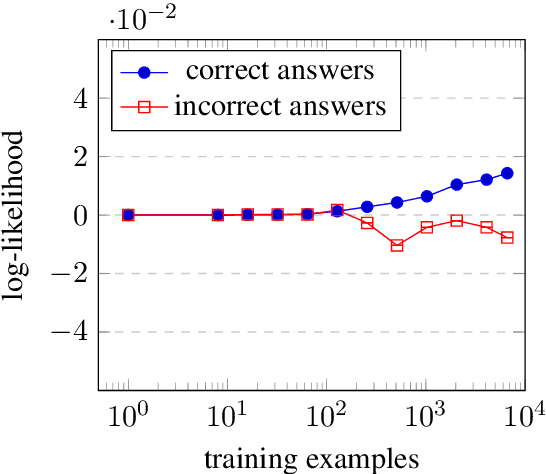

Large language models (LLMs) undergo a three-phase training process: unsupervised pre-training, supervised fine-tuning (SFT), and learning from human feedback (RLHF/DPO). Notably, it is during the final phase that these models are exposed to negative examples -- incorrect, rejected, or suboptimal responses to queries. This paper delves into the role of negative examples in the training of LLMs, using a likelihood-ratio (Likra) model on multiple-choice question answering benchmarks to precisely manage the influence and the volume of negative examples. Our findings reveal three key insights: (1) During a critical phase in training, Likra with negative examples demonstrates a significantly larger improvement per training example compared to SFT using only positive examples. This leads to a sharp jump in the learning curve for Likra unlike the smooth and gradual improvement of SFT; (2) negative examples that are plausible but incorrect (near-misses) exert a greater influence; and (3) while training with positive examples fails to significantly decrease the likelihood of plausible but incorrect answers, training with negative examples more accurately identifies them. These results indicate a potentially significant role for negative examples in improving accuracy and reducing hallucinations for LLMs.
Neurocache: Efficient Vector Retrieval for Long-range Language Modeling
Jul 02, 2024This paper introduces Neurocache, an approach to extend the effective context size of large language models (LLMs) using an external vector cache to store its past states. Like recent vector retrieval approaches, Neurocache uses an efficient k-nearest-neighbor (kNN) algorithm to retrieve relevant past states and incorporate them into the attention process. Neurocache improves upon previous methods by (1) storing compressed states, which reduces cache size; (2) performing a single retrieval operation per token which increases inference speed; and (3) extending the retrieval window to neighboring states, which improves both language modeling and downstream task accuracy. Our experiments show the effectiveness of Neurocache both for models trained from scratch and for pre-trained models such as Llama2-7B and Mistral-7B when enhanced with the cache mechanism. We also compare Neurocache with text retrieval methods and show improvements in single-document question-answering and few-shot learning tasks. We made the source code available under: https://github.com/alisafaya/neurocache
Bridging the Bosphorus: Advancing Turkish Large Language Models through Strategies for Low-Resource Language Adaptation and Benchmarking
May 07, 2024Large Language Models (LLMs) are becoming crucial across various fields, emphasizing the urgency for high-quality models in underrepresented languages. This study explores the unique challenges faced by low-resource languages, such as data scarcity, model selection, evaluation, and computational limitations, with a special focus on Turkish. We conduct an in-depth analysis to evaluate the impact of training strategies, model choices, and data availability on the performance of LLMs designed for underrepresented languages. Our approach includes two methodologies: (i) adapting existing LLMs originally pretrained in English to understand Turkish, and (ii) developing a model from the ground up using Turkish pretraining data, both supplemented with supervised fine-tuning on a novel Turkish instruction-tuning dataset aimed at enhancing reasoning capabilities. The relative performance of these methods is evaluated through the creation of a new leaderboard for Turkish LLMs, featuring benchmarks that assess different reasoning and knowledge skills. Furthermore, we conducted experiments on data and model scaling, both during pretraining and fine-tuning, simultaneously emphasizing the capacity for knowledge transfer across languages and addressing the challenges of catastrophic forgetting encountered during fine-tuning on a different language. Our goal is to offer a detailed guide for advancing the LLM framework in low-resource linguistic contexts, thereby making natural language processing (NLP) benefits more globally accessible.
Sequential Compositional Generalization in Multimodal Models
Apr 18, 2024
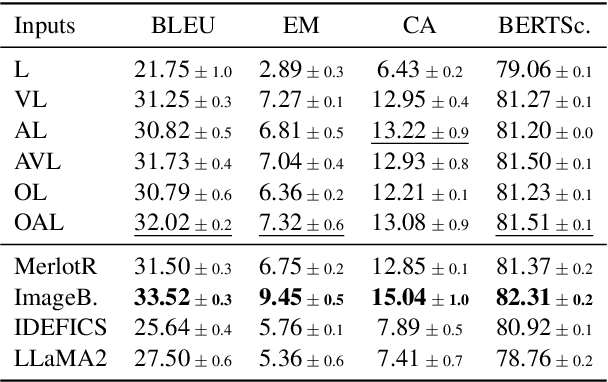
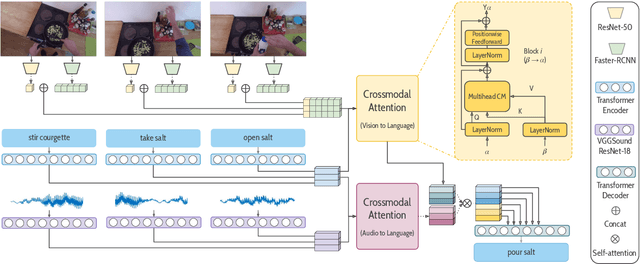
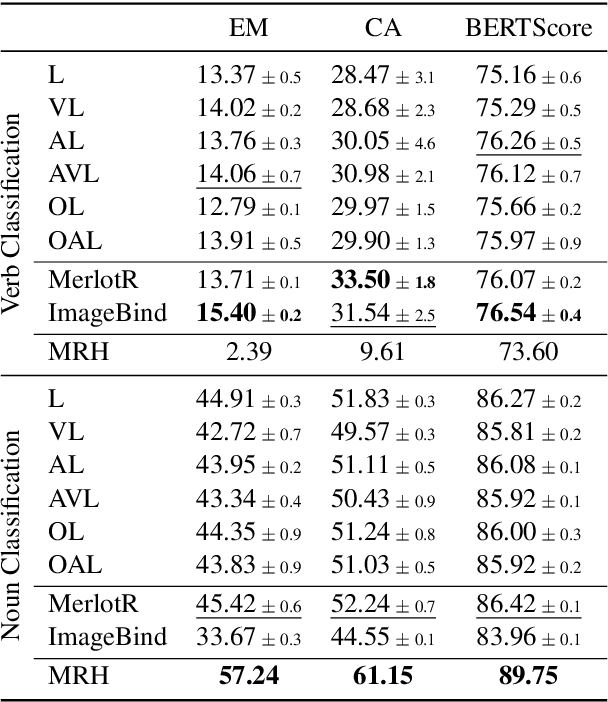
The rise of large-scale multimodal models has paved the pathway for groundbreaking advances in generative modeling and reasoning, unlocking transformative applications in a variety of complex tasks. However, a pressing question that remains is their genuine capability for stronger forms of generalization, which has been largely underexplored in the multimodal setting. Our study aims to address this by examining sequential compositional generalization using \textsc{CompAct} (\underline{Comp}ositional \underline{Act}ivities)\footnote{Project Page: \url{http://cyberiada.github.io/CompAct}}, a carefully constructed, perceptually grounded dataset set within a rich backdrop of egocentric kitchen activity videos. Each instance in our dataset is represented with a combination of raw video footage, naturally occurring sound, and crowd-sourced step-by-step descriptions. More importantly, our setup ensures that the individual concepts are consistently distributed across training and evaluation sets, while their compositions are novel in the evaluation set. We conduct a comprehensive assessment of several unimodal and multimodal models. Our findings reveal that bi-modal and tri-modal models exhibit a clear edge over their text-only counterparts. This highlights the importance of multimodality while charting a trajectory for future research in this domain.
Identity-Aware Semi-Supervised Learning for Comic Character Re-Identification
Aug 17, 2023Character re-identification, recognizing characters consistently across different panels in comics, presents significant challenges due to limited annotated data and complex variations in character appearances. To tackle this issue, we introduce a robust semi-supervised framework that combines metric learning with a novel 'Identity-Aware' self-supervision method by contrastive learning of face and body pairs of characters. Our approach involves processing both facial and bodily features within a unified network architecture, facilitating the extraction of identity-aligned character embeddings that capture individual identities while preserving the effectiveness of face and body features. This integrated character representation enhances feature extraction and improves character re-identification compared to re-identification by face or body independently, offering a parameter-efficient solution. By extensively validating our method using in-series and inter-series evaluation metrics, we demonstrate its effectiveness in consistently re-identifying comic characters. Compared to existing methods, our approach not only addresses the challenge of character re-identification but also serves as a foundation for downstream tasks since it can produce character embeddings without restrictions of face and body availability, enriching the comprehension of comic books. In our experiments, we leverage two newly curated datasets: the 'Comic Character Instances Dataset', comprising over a million character instances and the 'Comic Sequence Identity Dataset', containing annotations of identities within more than 3000 sets of four consecutive comic panels that we collected.
CLIP-Guided StyleGAN Inversion for Text-Driven Real Image Editing
Jul 18, 2023


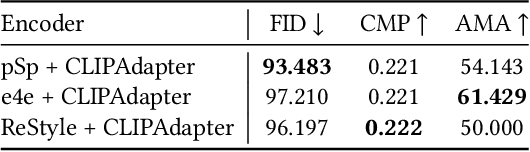
Researchers have recently begun exploring the use of StyleGAN-based models for real image editing. One particularly interesting application is using natural language descriptions to guide the editing process. Existing approaches for editing images using language either resort to instance-level latent code optimization or map predefined text prompts to some editing directions in the latent space. However, these approaches have inherent limitations. The former is not very efficient, while the latter often struggles to effectively handle multi-attribute changes. To address these weaknesses, we present CLIPInverter, a new text-driven image editing approach that is able to efficiently and reliably perform multi-attribute changes. The core of our method is the use of novel, lightweight text-conditioned adapter layers integrated into pretrained GAN-inversion networks. We demonstrate that by conditioning the initial inversion step on the CLIP embedding of the target description, we are able to obtain more successful edit directions. Additionally, we use a CLIP-guided refinement step to make corrections in the resulting residual latent codes, which further improves the alignment with the text prompt. Our method outperforms competing approaches in terms of manipulation accuracy and photo-realism on various domains including human faces, cats, and birds, as shown by our qualitative and quantitative results.
Machine learning in and out of equilibrium
Jun 06, 2023The algorithms used to train neural networks, like stochastic gradient descent (SGD), have close parallels to natural processes that navigate a high-dimensional parameter space -- for example protein folding or evolution. Our study uses a Fokker-Planck approach, adapted from statistical physics, to explore these parallels in a single, unified framework. We focus in particular on the stationary state of the system in the long-time limit, which in conventional SGD is out of equilibrium, exhibiting persistent currents in the space of network parameters. As in its physical analogues, the current is associated with an entropy production rate for any given training trajectory. The stationary distribution of these rates obeys the integral and detailed fluctuation theorems -- nonequilibrium generalizations of the second law of thermodynamics. We validate these relations in two numerical examples, a nonlinear regression network and MNIST digit classification. While the fluctuation theorems are universal, there are other aspects of the stationary state that are highly sensitive to the training details. Surprisingly, the effective loss landscape and diffusion matrix that determine the shape of the stationary distribution vary depending on the simple choice of minibatching done with or without replacement. We can take advantage of this nonequilibrium sensitivity to engineer an equilibrium stationary state for a particular application: sampling from a posterior distribution of network weights in Bayesian machine learning. We propose a new variation of stochastic gradient Langevin dynamics (SGLD) that harnesses without replacement minibatching. In an example system where the posterior is exactly known, this SGWORLD algorithm outperforms SGLD, converging to the posterior orders of magnitude faster as a function of the learning rate.
A Comprehensive Gold Standard and Benchmark for Comics Text Detection and Recognition
Dec 27, 2022



This study focuses on improving the optical character recognition (OCR) data for panels in the COMICS dataset, the largest dataset containing text and images from comic books. To do this, we developed a pipeline for OCR processing and labeling of comic books and created the first text detection and recognition datasets for western comics, called "COMICS Text+: Detection" and "COMICS Text+: Recognition". We evaluated the performance of state-of-the-art text detection and recognition models on these datasets and found significant improvement in word accuracy and normalized edit distance compared to the text in COMICS. We also created a new dataset called "COMICS Text+", which contains the extracted text from the textboxes in the COMICS dataset. Using the improved text data of COMICS Text+ in the comics processing model from resulted in state-of-the-art performance on cloze-style tasks without changing the model architecture. The COMICS Text+ dataset can be a valuable resource for researchers working on tasks including text detection, recognition, and high-level processing of comics, such as narrative understanding, character relations, and story generation. All the data and inference instructions can be accessed in https://github.com/gsoykan/comics_text_plus.
Domain-Adaptive Self-Supervised Pre-Training for Face & Body Detection in Drawings
Nov 19, 2022Drawings are powerful means of pictorial abstraction and communication. Understanding diverse forms of drawings, including digital arts, cartoons, and comics, has been a major problem of interest for the computer vision and computer graphics communities. Although there are large amounts of digitized drawings from comic books and cartoons, they contain vast stylistic variations, which necessitate expensive manual labeling for training domain-specific recognizers. In this work, we show how self-supervised learning, based on a teacher-student network with a modified student network update design, can be used to build face and body detectors. Our setup allows exploiting large amounts of unlabeled data from the target domain when labels are provided for only a small subset of it. We further demonstrate that style transfer can be incorporated into our learning pipeline to bootstrap detectors using a vast amount of out-of-domain labeled images from natural images (i.e., images from the real world). Our combined architecture yields detectors with state-of-the-art (SOTA) and near-SOTA performance using minimal annotation effort.