 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTangent Space Fine-Tuning for Directional Preference Alignment in Large Language Models
Feb 01, 2026Our goal is to enable large language models (LLMs) to balance multiple human preference dimensions; such as helpfulness, safety, and verbosity, through principled and controllable alignment. Existing preference optimization methods, including Direct Preference Optimization (DPO), collapse feedback into a single scalar reward, fixing one balance among objectives and preventing traversal of the Pareto front. Recent work by Ortiz-Jimenez et al. (2023) showed that fine-tuning can be viewed in a model's tangent space, where linearized updates act as additive vectors that can be composed to jointly perform well on multiple tasks. Building on this formulation, we extend this idea to preference alignment and propose Tangent-Space Direct Preference Optimization (TS-DPO), which performs DPO within this locally linear regime to learn per-objective update directions. These directions can be linearly combined at inference to generate user-specified behaviors without additional optimization. Evaluated on the helpfulness-verbosity trade-off using the HelpSteer and UltraFeedback datasets, TS-DPO achieves broader Pareto-optimal coverage and smoother preference control than scalarized DPO. Canonical Correlation Analysis (CCA) further shows that tangent-space training amplifies canonical directions aligned with distinct preferences, improving disentanglement.
Efficient Large Language Model Inference with Neural Block Linearization
May 27, 2025The high inference demands of transformer-based Large Language Models (LLMs) pose substantial challenges in their deployment. To this end, we introduce Neural Block Linearization (NBL), a novel framework for accelerating transformer model inference by replacing self-attention layers with linear approximations derived from Linear Minimum Mean Squared Error estimators. NBL leverages Canonical Correlation Analysis to compute a theoretical upper bound on the approximation error. Then, we use this bound as a criterion for substitution, selecting the LLM layers with the lowest linearization error. NBL can be efficiently applied to pre-trained LLMs without the need for fine-tuning. In experiments, NBL achieves notable computational speed-ups while preserving competitive accuracy on multiple reasoning benchmarks. For instance, applying NBL to 12 self-attention layers in DeepSeek-R1-Distill-Llama-8B increases the inference speed by 32% with less than 1% accuracy trade-off, making it a flexible and promising solution to improve the inference efficiency of LLMs.
SVD Based Least Squares for X-Ray Pneumonia Classification Using Deep Features
Apr 29, 2025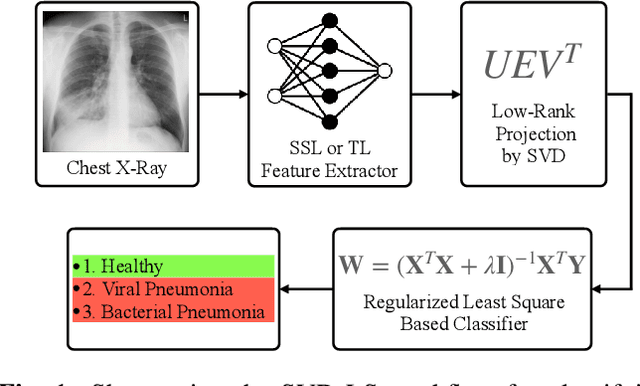
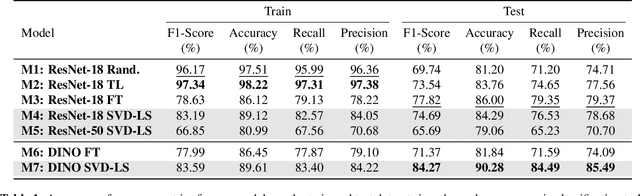
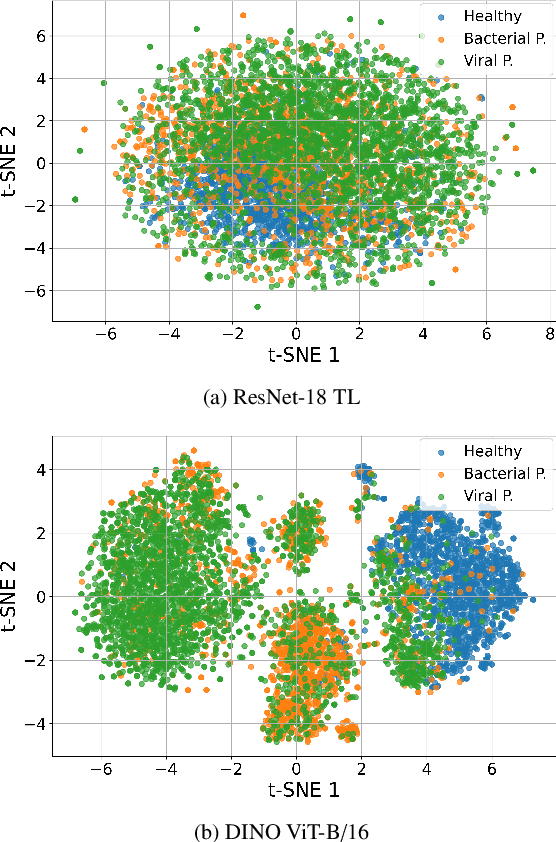

Accurate and early diagnosis of pneumonia through X-ray imaging is essential for effective treatment and improved patient outcomes. Recent advancements in machine learning have enabled automated diagnostic tools that assist radiologists in making more reliable and efficient decisions. In this work, we propose a Singular Value Decomposition-based Least Squares (SVD-LS) framework for multi-class pneumonia classification, leveraging powerful feature representations from state-of-the-art self-supervised and transfer learning models. Rather than relying on computationally expensive gradient based fine-tuning, we employ a closed-form, non-iterative classification approach that ensures efficiency without compromising accuracy. Experimental results demonstrate that SVD-LS achieves competitive performance while offering significantly reduced computational costs, making it a viable alternative for real-time medical imaging applications.
Error Broadcast and Decorrelation as a Potential Artificial and Natural Learning Mechanism
Apr 15, 2025We introduce the Error Broadcast and Decorrelation (EBD) algorithm, a novel learning framework that addresses the credit assignment problem in neural networks by directly broadcasting output error to individual layers. Leveraging the stochastic orthogonality property of the optimal minimum mean square error (MMSE) estimator, EBD defines layerwise loss functions to penalize correlations between layer activations and output errors, offering a principled approach to error broadcasting without the need for weight transport. The optimization framework naturally leads to the experimentally observed three-factor learning rule and integrates with biologically plausible frameworks to enhance performance and plausibility. Numerical experiments demonstrate that EBD achieves performance comparable to or better than known error-broadcast methods on benchmark datasets. While the scalability of EBD to very large or complex datasets remains to be further explored, our findings suggest it provides a biologically plausible, efficient, and adaptable alternative for neural network training. This approach could inform future advancements in artificial and natural learning paradigms.
Bridging the Bosphorus: Advancing Turkish Large Language Models through Strategies for Low-Resource Language Adaptation and Benchmarking
May 07, 2024Large Language Models (LLMs) are becoming crucial across various fields, emphasizing the urgency for high-quality models in underrepresented languages. This study explores the unique challenges faced by low-resource languages, such as data scarcity, model selection, evaluation, and computational limitations, with a special focus on Turkish. We conduct an in-depth analysis to evaluate the impact of training strategies, model choices, and data availability on the performance of LLMs designed for underrepresented languages. Our approach includes two methodologies: (i) adapting existing LLMs originally pretrained in English to understand Turkish, and (ii) developing a model from the ground up using Turkish pretraining data, both supplemented with supervised fine-tuning on a novel Turkish instruction-tuning dataset aimed at enhancing reasoning capabilities. The relative performance of these methods is evaluated through the creation of a new leaderboard for Turkish LLMs, featuring benchmarks that assess different reasoning and knowledge skills. Furthermore, we conducted experiments on data and model scaling, both during pretraining and fine-tuning, simultaneously emphasizing the capacity for knowledge transfer across languages and addressing the challenges of catastrophic forgetting encountered during fine-tuning on a different language. Our goal is to offer a detailed guide for advancing the LLM framework in low-resource linguistic contexts, thereby making natural language processing (NLP) benefits more globally accessible.
Machine Learning and Kalman Filtering for Nanomechanical Mass Spectrometry
Jun 01, 2023



Nanomechanical resonant sensors are used in mass spectrometry via detection of resonance frequency jumps. There is a fundamental trade-off between detection speed and accuracy. Temporal and size resolution are limited by the resonator characteristics and noise. A Kalman filtering technique, augmented with maximum-likelihood estimation, was recently proposed as a Pareto optimal solution. We present enhancements and robust realizations for this technique, including a confidence boosted thresholding approach as well as machine learning for event detection. We describe learning techniques that are based on neural networks and boosted decision trees for temporal location and event size estimation. In the pure learning based approach that discards the Kalman filter, the raw data from the sensor are used in training a model for both location and size prediction. In the alternative approach that augments a Kalman filter, the event likelihood history is used in a binary classifier for event occurrence. Locations and sizes are predicted using maximum-likelihood, followed by a Kalman filter that continually improves the size estimate. We present detailed comparisons of the learning based schemes and the confidence boosted thresholding approach, and demonstrate robust performance for a practical realization.