 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaD-Mix: Multi-Modal Data Mixtures via Latent Space Coupling for Vision-Language Model Training
Feb 08, 2026Vision-Language Models (VLMs) are typically trained on a diverse set of multi-modal domains, yet current practices rely on costly manual tuning. We propose MaD-Mix, a principled and computationally efficient framework that derives multi-modal data mixtures for VLM training. MaD-Mix formulates data mixing as modality-aware domain alignment maximization and obtains closed-form multi-modal alignment scores from the Fenchel dual through inter-modal coupling variables. MaD-Mix systematically handles domains with missing modalities, allowing for the integration of language-only domains. Empirical evaluations across 0.5B and 7B models demonstrate that MaD-Mix accelerates VLM training across diverse benchmarks. MaD-Mix matches human-tuned data mixtures using 22% fewer training steps in image-text instruction tuning. In complex tri-modal video-image-text scenarios, where manual tuning becomes impractical, MaD-Mix boosts average accuracy over uniform weights, with negligible mixture computation overhead (< 1 GPU-hour), enabling scalable mixture design for modern VLM pipelines.
Accelerating Spectral Clustering under Fairness Constraints
Jun 09, 2025Fairness of decision-making algorithms is an increasingly important issue. In this paper, we focus on spectral clustering with group fairness constraints, where every demographic group is represented in each cluster proportionally as in the general population. We present a new efficient method for fair spectral clustering (Fair SC) by casting the Fair SC problem within the difference of convex functions (DC) framework. To this end, we introduce a novel variable augmentation strategy and employ an alternating direction method of multipliers type of algorithm adapted to DC problems. We show that each associated subproblem can be solved efficiently, resulting in higher computational efficiency compared to prior work, which required a computationally expensive eigendecomposition. Numerical experiments demonstrate the effectiveness of our approach on both synthetic and real-world benchmarks, showing significant speedups in computation time over prior art, especially as the problem size grows. This work thus represents a considerable step forward towards the adoption of fair clustering in real-world applications.
Chameleon: A Flexible Data-mixing Framework for Language Model Pretraining and Finetuning
May 30, 2025Training data mixtures greatly impact the generalization performance of large language models. Existing domain reweighting methods often rely on costly weight computations and require retraining when new data is introduced. To this end, we introduce a flexible and efficient data mixing framework, Chameleon, that employs leverage scores to quantify domain importance within a learned embedding space. We first construct a domain affinity matrix over domain embeddings. The induced leverage scores determine a mixture that upweights domains sharing common representations in embedding space. This formulation allows direct transfer to new data by computing the new domain embeddings. In experiments, we demonstrate improvements over three key scenarios: (i) our computed weights improve performance on pretraining domains with a fraction of the compute of existing methods; (ii) Chameleon can adapt to data changes without proxy retraining, boosting few-shot reasoning accuracies when transferred to new data; (iii) our method enables efficient domain reweighting in finetuning, consistently improving test perplexity on all finetuning domains over uniform mixture. Our code is available at https://github.com/LIONS-EPFL/Chameleon.
Efficient Large Language Model Inference with Neural Block Linearization
May 27, 2025The high inference demands of transformer-based Large Language Models (LLMs) pose substantial challenges in their deployment. To this end, we introduce Neural Block Linearization (NBL), a novel framework for accelerating transformer model inference by replacing self-attention layers with linear approximations derived from Linear Minimum Mean Squared Error estimators. NBL leverages Canonical Correlation Analysis to compute a theoretical upper bound on the approximation error. Then, we use this bound as a criterion for substitution, selecting the LLM layers with the lowest linearization error. NBL can be efficiently applied to pre-trained LLMs without the need for fine-tuning. In experiments, NBL achieves notable computational speed-ups while preserving competitive accuracy on multiple reasoning benchmarks. For instance, applying NBL to 12 self-attention layers in DeepSeek-R1-Distill-Llama-8B increases the inference speed by 32% with less than 1% accuracy trade-off, making it a flexible and promising solution to improve the inference efficiency of LLMs.
Quantum-PEFT: Ultra parameter-efficient fine-tuning
Mar 07, 2025This paper introduces Quantum-PEFT that leverages quantum computations for parameter-efficient fine-tuning (PEFT). Unlike other additive PEFT methods, such as low-rank adaptation (LoRA), Quantum-PEFT exploits an underlying full-rank yet surprisingly parameter efficient quantum unitary parameterization. With the use of Pauli parameterization, the number of trainable parameters grows only logarithmically with the ambient dimension, as opposed to linearly as in LoRA-based PEFT methods. Quantum-PEFT achieves vanishingly smaller number of trainable parameters than the lowest-rank LoRA as dimensions grow, enhancing parameter efficiency while maintaining a competitive performance. We apply Quantum-PEFT to several transfer learning benchmarks in language and vision, demonstrating significant advantages in parameter efficiency.
Linear Attention for Efficient Bidirectional Sequence Modeling
Feb 22, 2025Transformers with linear attention enable fast and parallel training. Moreover, they can be formulated as Recurrent Neural Networks (RNNs), for efficient linear-time inference. While extensively evaluated in causal sequence modeling, they have yet to be extended to the bidirectional setting. This work introduces the LION framework, establishing new theoretical foundations for linear transformers in bidirectional sequence modeling. LION constructs a bidirectional RNN equivalent to full Linear Attention. This extends the benefits of linear transformers: parallel training, and efficient inference, into the bidirectional setting. Using LION, we cast three linear transformers to their bidirectional form: LION-LIT, the bidirectional variant corresponding to (Katharopoulos et al., 2020); LION-D, extending RetNet (Sun et al., 2023); and LION-S, a linear transformer with a stable selective mask inspired by selectivity of SSMs (Dao & Gu, 2024). Replacing the attention block with LION (-LIT, -D, -S) achieves performance on bidirectional tasks that approaches that of Transformers and State-Space Models (SSMs), while delivering significant improvements in training speed. Our implementation is available in http://github.com/LIONS-EPFL/LION.
Membership Inference Attacks against Large Vision-Language Models
Nov 05, 2024



Large vision-language models (VLLMs) exhibit promising capabilities for processing multi-modal tasks across various application scenarios. However, their emergence also raises significant data security concerns, given the potential inclusion of sensitive information, such as private photos and medical records, in their training datasets. Detecting inappropriately used data in VLLMs remains a critical and unresolved issue, mainly due to the lack of standardized datasets and suitable methodologies. In this study, we introduce the first membership inference attack (MIA) benchmark tailored for various VLLMs to facilitate training data detection. Then, we propose a novel MIA pipeline specifically designed for token-level image detection. Lastly, we present a new metric called MaxR\'enyi-K%, which is based on the confidence of the model output and applies to both text and image data. We believe that our work can deepen the understanding and methodology of MIAs in the context of VLLMs. Our code and datasets are available at https://github.com/LIONS-EPFL/VL-MIA.
Learning in Feature Spaces via Coupled Covariances: Asymmetric Kernel SVD and Nyström method
Jun 13, 2024



In contrast with Mercer kernel-based approaches as used e.g., in Kernel Principal Component Analysis (KPCA), it was previously shown that Singular Value Decomposition (SVD) inherently relates to asymmetric kernels and Asymmetric Kernel Singular Value Decomposition (KSVD) has been proposed. However, the existing formulation to KSVD cannot work with infinite-dimensional feature mappings, the variational objective can be unbounded, and needs further numerical evaluation and exploration towards machine learning. In this work, i) we introduce a new asymmetric learning paradigm based on coupled covariance eigenproblem (CCE) through covariance operators, allowing infinite-dimensional feature maps. The solution to CCE is ultimately obtained from the SVD of the induced asymmetric kernel matrix, providing links to KSVD. ii) Starting from the integral equations corresponding to a pair of coupled adjoint eigenfunctions, we formalize the asymmetric Nystr\"om method through a finite sample approximation to speed up training. iii) We provide the first empirical evaluations verifying the practical utility and benefits of KSVD and compare with methods resorting to symmetrization or linear SVD across multiple tasks.
* 19 pages, 9 tables, 6 figures
HeNCler: Node Clustering in Heterophilous Graphs through Learned Asymmetric Similarity
May 27, 2024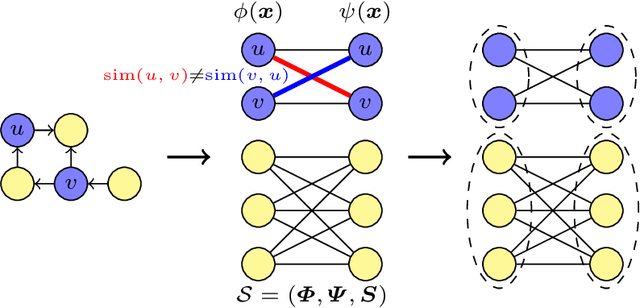
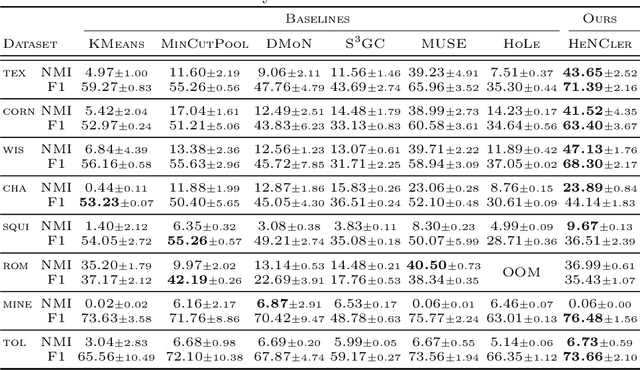
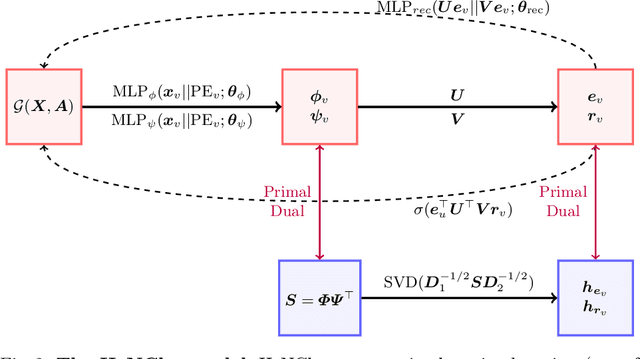
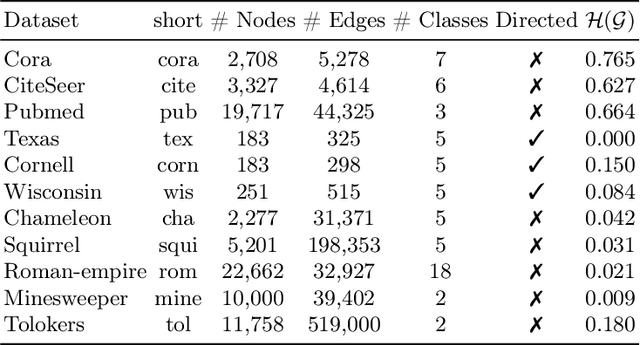
Clustering nodes in heterophilous graphs presents unique challenges due to the asymmetric relationships often overlooked by traditional methods, which moreover assume that good clustering corresponds to high intra-cluster and low inter-cluster connectivity. To address these issues, we introduce HeNCler - a novel approach for Heterophilous Node Clustering. Our method begins by defining a weighted kernel singular value decomposition to create an asymmetric similarity graph, applicable to both directed and undirected graphs. We further establish that the dual problem of this formulation aligns with asymmetric kernel spectral clustering, interpreting learned graph similarities without relying on homophily. We demonstrate the ability to solve the primal problem directly, circumventing the computational difficulties of the dual approach. Experimental evidence confirms that HeNCler significantly enhances performance in node clustering tasks within heterophilous graph contexts.
Self-Attention through Kernel-Eigen Pair Sparse Variational Gaussian Processes
Feb 02, 2024



While the great capability of Transformers significantly boosts prediction accuracy, it could also yield overconfident predictions and require calibrated uncertainty estimation, which can be commonly tackled by Gaussian processes (GPs). Existing works apply GPs with symmetric kernels under variational inference to the attention kernel; however, omitting the fact that attention kernels are in essence asymmetric. Moreover, the complexity of deriving the GP posteriors remains high for large-scale data. In this work, we propose Kernel-Eigen Pair Sparse Variational Gaussian Processes (KEP-SVGP) for building uncertainty-aware self-attention where the asymmetry of attention kernels is tackled by Kernel SVD (KSVD) and a reduced complexity is acquired. Through KEP-SVGP, i) the SVGP pair induced by the two sets of singular vectors from KSVD w.r.t. the attention kernel fully characterizes the asymmetry; ii) using only a small set of adjoint eigenfunctions from KSVD, the derivation of SVGP posteriors can be based on the inversion of a diagonal matrix containing singular values, contributing to a reduction in time complexity; iii) an evidence lower bound is derived so that variational parameters can be optimized towards this objective. Experiments verify our excellent performances and efficiency on in-distribution, distribution-shift and out-of-distribution benchmarks.