 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMT-NAM: An Efficient and Adaptive Model for Epileptic Seizure Detection
Mar 11, 2025Enhancing the accuracy and efficiency of machine learning algorithms employed in neural interface systems is crucial for advancing next-generation intelligent therapeutic devices. However, current systems often utilize basic machine learning models that do not fully exploit the natural structure of brain signals. Additionally, existing learning models used for neural signal processing often demonstrate low speed and efficiency during inference. To address these challenges, this study introduces Micro Tree-based NAM (MT-NAM), a distilled model based on the recently proposed Neural Additive Models (NAM). The MT-NAM achieves a remarkable 100$\times$ improvement in inference speed compared to standard NAM, without compromising accuracy. We evaluate our approach on the CHB-MIT scalp EEG dataset, which includes recordings from 24 patients with varying numbers of sessions and seizures. NAM achieves an 85.3\% window-based sensitivity and 95\% specificity. Interestingly, our proposed MT-NAM shows only a 2\% reduction in sensitivity compared to the original NAM. To regain this sensitivity, we utilize a test-time template adjuster (T3A) as an update mechanism, enabling our model to achieve higher sensitivity during test time by accommodating transient shifts in neural signals. With this online update approach, MT-NAM achieves the same sensitivity as the standard NAM while achieving approximately 50$\times$ acceleration in inference speed.
Linear Attention for Efficient Bidirectional Sequence Modeling
Feb 22, 2025Transformers with linear attention enable fast and parallel training. Moreover, they can be formulated as Recurrent Neural Networks (RNNs), for efficient linear-time inference. While extensively evaluated in causal sequence modeling, they have yet to be extended to the bidirectional setting. This work introduces the LION framework, establishing new theoretical foundations for linear transformers in bidirectional sequence modeling. LION constructs a bidirectional RNN equivalent to full Linear Attention. This extends the benefits of linear transformers: parallel training, and efficient inference, into the bidirectional setting. Using LION, we cast three linear transformers to their bidirectional form: LION-LIT, the bidirectional variant corresponding to (Katharopoulos et al., 2020); LION-D, extending RetNet (Sun et al., 2023); and LION-S, a linear transformer with a stable selective mask inspired by selectivity of SSMs (Dao & Gu, 2024). Replacing the attention block with LION (-LIT, -D, -S) achieves performance on bidirectional tasks that approaches that of Transformers and State-Space Models (SSMs), while delivering significant improvements in training speed. Our implementation is available in http://github.com/LIONS-EPFL/LION.
Challenges and Opportunities of Edge AI for Next-Generation Implantable BMIs
Apr 13, 2022
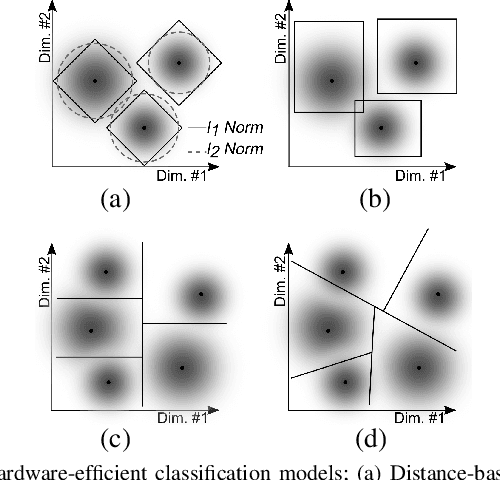
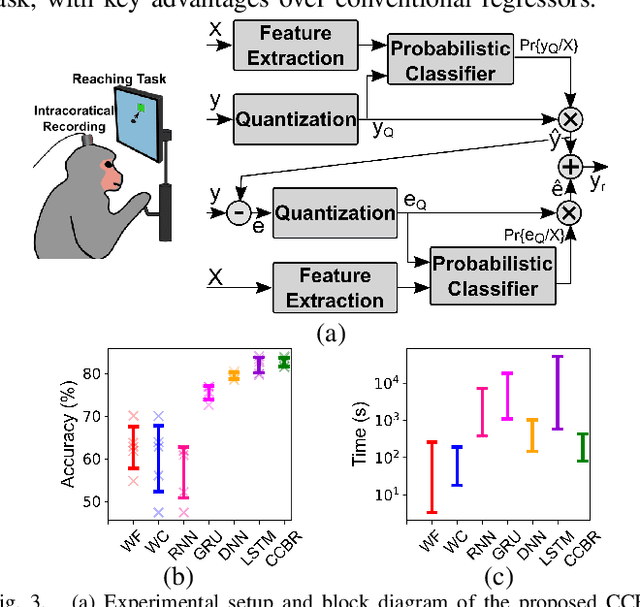
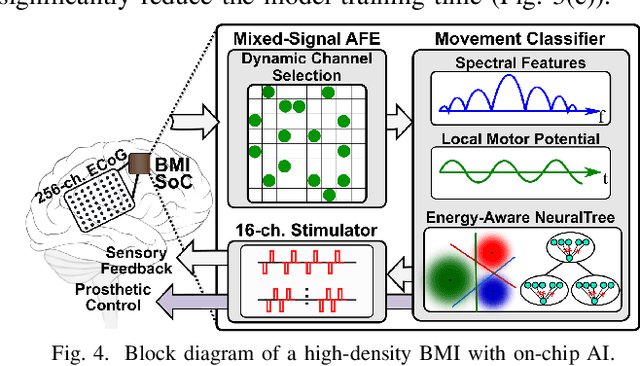
Neuroscience and neurotechnology are currently being revolutionized by artificial intelligence (AI) and machine learning. AI is widely used to study and interpret neural signals (analytical applications), assist people with disabilities (prosthetic applications), and treat underlying neurological symptoms (therapeutic applications). In this brief, we will review the emerging opportunities of on-chip AI for the next-generation implantable brain-machine interfaces (BMIs), with a focus on state-of-the-art prosthetic BMIs. Major technological challenges for the effectiveness of AI models will be discussed. Finally, we will present algorithmic and IC design solutions to enable a new generation of AI-enhanced and high-channel-count BMIs.