 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEasy Data Unlearning Bench
Feb 18, 2026Evaluating machine unlearning methods remains technically challenging, with recent benchmarks requiring complex setups and significant engineering overhead. We introduce a unified and extensible benchmarking suite that simplifies the evaluation of unlearning algorithms using the KLoM (KL divergence of Margins) metric. Our framework provides precomputed model ensembles, oracle outputs, and streamlined infrastructure for running evaluations out of the box. By standardizing setup and metrics, it enables reproducible, scalable, and fair comparison across unlearning methods. We aim for this benchmark to serve as a practical foundation for accelerating research and promoting best practices in machine unlearning. Our code and data are publicly available.
Linear Attention for Efficient Bidirectional Sequence Modeling
Feb 22, 2025Transformers with linear attention enable fast and parallel training. Moreover, they can be formulated as Recurrent Neural Networks (RNNs), for efficient linear-time inference. While extensively evaluated in causal sequence modeling, they have yet to be extended to the bidirectional setting. This work introduces the LION framework, establishing new theoretical foundations for linear transformers in bidirectional sequence modeling. LION constructs a bidirectional RNN equivalent to full Linear Attention. This extends the benefits of linear transformers: parallel training, and efficient inference, into the bidirectional setting. Using LION, we cast three linear transformers to their bidirectional form: LION-LIT, the bidirectional variant corresponding to (Katharopoulos et al., 2020); LION-D, extending RetNet (Sun et al., 2023); and LION-S, a linear transformer with a stable selective mask inspired by selectivity of SSMs (Dao & Gu, 2024). Replacing the attention block with LION (-LIT, -D, -S) achieves performance on bidirectional tasks that approaches that of Transformers and State-Space Models (SSMs), while delivering significant improvements in training speed. Our implementation is available in http://github.com/LIONS-EPFL/LION.
A Data-Driven Approach to Dataflow-Aware Online Scheduling for Graph Neural Network Inference
Nov 25, 2024Graph Neural Networks (GNNs) have shown significant promise in various domains, such as recommendation systems, bioinformatics, and network analysis. However, the irregularity of graph data poses unique challenges for efficient computation, leading to the development of specialized GNN accelerator architectures that surpass traditional CPU and GPU performance. Despite this, the structural diversity of input graphs results in varying performance across different GNN accelerators, depending on their dataflows. This variability in performance due to differing dataflows and graph properties remains largely unexplored, limiting the adaptability of GNN accelerators. To address this, we propose a data-driven framework for dataflow-aware latency prediction in GNN inference. Our approach involves training regressors to predict the latency of executing specific graphs on particular dataflows, using simulations on synthetic graphs. Experimental results indicate that our regressors can predict the optimal dataflow for a given graph with up to 91.28% accuracy and a Mean Absolute Percentage Error (MAPE) of 3.78%. Additionally, we introduce an online scheduling algorithm that uses these regressors to enhance scheduling decisions. Our experiments demonstrate that this algorithm achieves up to $3.17\times$ speedup in mean completion time and $6.26\times$ speedup in mean execution time compared to the best feasible baseline across all datasets.
Learning to Remove Cuts in Integer Linear Programming
Jun 26, 2024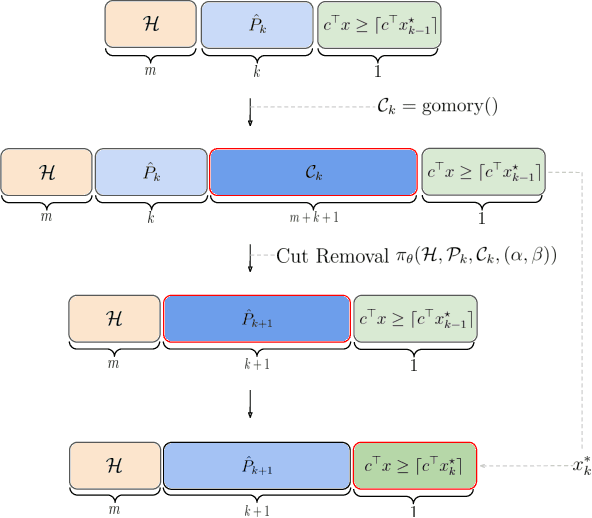
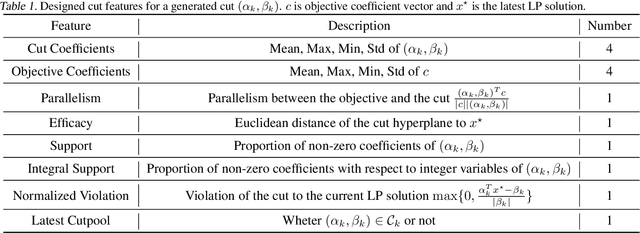
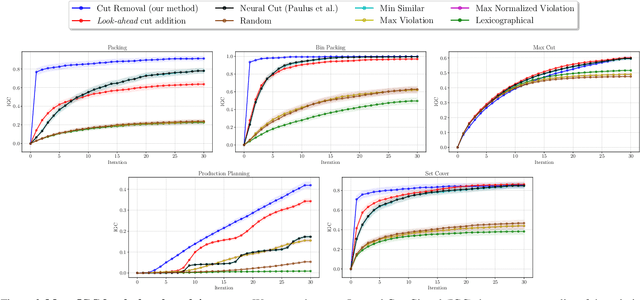

Cutting plane methods are a fundamental approach for solving integer linear programs (ILPs). In each iteration of such methods, additional linear constraints (cuts) are introduced to the constraint set with the aim of excluding the previous fractional optimal solution while not affecting the optimal integer solution. In this work, we explore a novel approach within cutting plane methods: instead of only adding new cuts, we also consider the removal of previous cuts introduced at any of the preceding iterations of the method under a learnable parametric criteria. We demonstrate that in fundamental combinatorial optimization settings such cut removal policies can lead to significant improvements over both human-based and machine learning-guided cut addition policies even when implemented with simple models.