 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffCAP: Diffusion-based Cumulative Adversarial Purification for Vision Language Models
Jun 04, 2025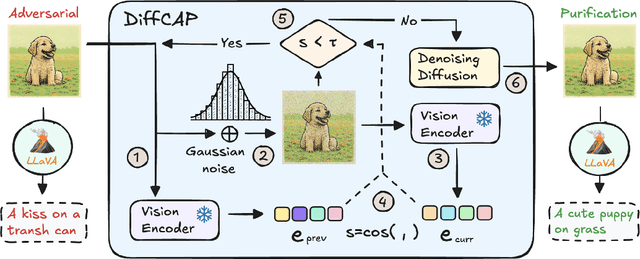
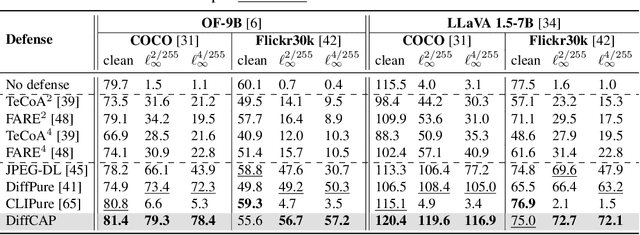
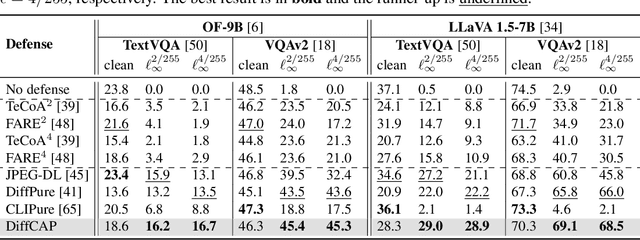
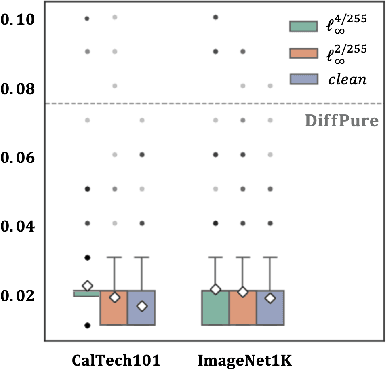
Vision Language Models (VLMs) have shown remarkable capabilities in multimodal understanding, yet their susceptibility to perturbations poses a significant threat to their reliability in real-world applications. Despite often being imperceptible to humans, these perturbations can drastically alter model outputs, leading to erroneous interpretations and decisions. This paper introduces DiffCAP, a novel diffusion-based purification strategy that can effectively neutralize adversarial corruptions in VLMs. We observe that adding minimal noise to an adversarially corrupted image significantly alters its latent embedding with respect to VLMs. Building on this insight, DiffCAP cumulatively injects random Gaussian noise into adversarially perturbed input data. This process continues until the embeddings of two consecutive noisy images reach a predefined similarity threshold, indicating a potential approach to neutralize the adversarial effect. Subsequently, a pretrained diffusion model is employed to denoise the stabilized image, recovering a clean representation suitable for the VLMs to produce an output. Through extensive experiments across six datasets with three VLMs under varying attack strengths in three task scenarios, we show that DiffCAP consistently outperforms existing defense techniques by a substantial margin. Notably, DiffCAP significantly reduces both hyperparameter tuning complexity and the required diffusion time, thereby accelerating the denoising process. Equipped with strong theoretical and empirical support, DiffCAP provides a robust and practical solution for securely deploying VLMs in adversarial environments.
Hadamard product in deep learning: Introduction, Advances and Challenges
Apr 17, 2025While convolution and self-attention mechanisms have dominated architectural design in deep learning, this survey examines a fundamental yet understudied primitive: the Hadamard product. Despite its widespread implementation across various applications, the Hadamard product has not been systematically analyzed as a core architectural primitive. We present the first comprehensive taxonomy of its applications in deep learning, identifying four principal domains: higher-order correlation, multimodal data fusion, dynamic representation modulation, and efficient pairwise operations. The Hadamard product's ability to model nonlinear interactions with linear computational complexity makes it particularly valuable for resource-constrained deployments and edge computing scenarios. We demonstrate its natural applicability in multimodal fusion tasks, such as visual question answering, and its effectiveness in representation masking for applications including image inpainting and pruning. This systematic review not only consolidates existing knowledge about the Hadamard product's role in deep learning architectures but also establishes a foundation for future architectural innovations. Our analysis reveals the Hadamard product as a versatile primitive that offers compelling trade-offs between computational efficiency and representational power, positioning it as a crucial component in the deep learning toolkit.
Quantum-PEFT: Ultra parameter-efficient fine-tuning
Mar 07, 2025This paper introduces Quantum-PEFT that leverages quantum computations for parameter-efficient fine-tuning (PEFT). Unlike other additive PEFT methods, such as low-rank adaptation (LoRA), Quantum-PEFT exploits an underlying full-rank yet surprisingly parameter efficient quantum unitary parameterization. With the use of Pauli parameterization, the number of trainable parameters grows only logarithmically with the ambient dimension, as opposed to linearly as in LoRA-based PEFT methods. Quantum-PEFT achieves vanishingly smaller number of trainable parameters than the lowest-rank LoRA as dimensions grow, enhancing parameter efficiency while maintaining a competitive performance. We apply Quantum-PEFT to several transfer learning benchmarks in language and vision, demonstrating significant advantages in parameter efficiency.
Linear Attention for Efficient Bidirectional Sequence Modeling
Feb 22, 2025Transformers with linear attention enable fast and parallel training. Moreover, they can be formulated as Recurrent Neural Networks (RNNs), for efficient linear-time inference. While extensively evaluated in causal sequence modeling, they have yet to be extended to the bidirectional setting. This work introduces the LION framework, establishing new theoretical foundations for linear transformers in bidirectional sequence modeling. LION constructs a bidirectional RNN equivalent to full Linear Attention. This extends the benefits of linear transformers: parallel training, and efficient inference, into the bidirectional setting. Using LION, we cast three linear transformers to their bidirectional form: LION-LIT, the bidirectional variant corresponding to (Katharopoulos et al., 2020); LION-D, extending RetNet (Sun et al., 2023); and LION-S, a linear transformer with a stable selective mask inspired by selectivity of SSMs (Dao & Gu, 2024). Replacing the attention block with LION (-LIT, -D, -S) achieves performance on bidirectional tasks that approaches that of Transformers and State-Space Models (SSMs), while delivering significant improvements in training speed. Our implementation is available in http://github.com/LIONS-EPFL/LION.
Single-pass Detection of Jailbreaking Input in Large Language Models
Feb 21, 2025Defending aligned Large Language Models (LLMs) against jailbreaking attacks is a challenging problem, with existing approaches requiring multiple requests or even queries to auxiliary LLMs, making them computationally heavy. Instead, we focus on detecting jailbreaking input in a single forward pass. Our method, called Single Pass Detection SPD, leverages the information carried by the logits to predict whether the output sentence will be harmful. This allows us to defend in just one forward pass. SPD can not only detect attacks effectively on open-source models, but also minimizes the misclassification of harmless inputs. Furthermore, we show that SPD remains effective even without complete logit access in GPT-3.5 and GPT-4. We believe that our proposed method offers a promising approach to efficiently safeguard LLMs against adversarial attacks.
Multi-Step Alignment as Markov Games: An Optimistic Online Gradient Descent Approach with Convergence Guarantees
Feb 18, 2025



Reinforcement Learning from Human Feedback (RLHF) has been highly successful in aligning large language models with human preferences. While prevalent methods like DPO have demonstrated strong performance, they frame interactions with the language model as a bandit problem, which limits their applicability in real-world scenarios where multi-turn conversations are common. Additionally, DPO relies on the Bradley-Terry model assumption, which does not adequately capture the non-transitive nature of human preferences. In this paper, we address these challenges by modeling the alignment problem as a two-player constant-sum Markov game, where each player seeks to maximize their winning rate against the other across all steps of the conversation. Our approach Multi-step Preference Optimization (MPO) is built upon the natural actor-critic framework~\citep{peters2008natural}. We further develop OMPO based on the optimistic online gradient descent algorithm~\citep{rakhlin2013online,joulani17a}. Theoretically, we provide a rigorous analysis for both algorithms on convergence and show that OMPO requires $\mathcal{O}(\epsilon^{-1})$ policy updates to converge to an $\epsilon$-approximate Nash equilibrium. We also validate the effectiveness of our method on multi-turn conversations dataset and math reasoning dataset.
Membership Inference Attacks against Large Vision-Language Models
Nov 05, 2024



Large vision-language models (VLLMs) exhibit promising capabilities for processing multi-modal tasks across various application scenarios. However, their emergence also raises significant data security concerns, given the potential inclusion of sensitive information, such as private photos and medical records, in their training datasets. Detecting inappropriately used data in VLLMs remains a critical and unresolved issue, mainly due to the lack of standardized datasets and suitable methodologies. In this study, we introduce the first membership inference attack (MIA) benchmark tailored for various VLLMs to facilitate training data detection. Then, we propose a novel MIA pipeline specifically designed for token-level image detection. Lastly, we present a new metric called MaxR\'enyi-K%, which is based on the confidence of the model output and applies to both text and image data. We believe that our work can deepen the understanding and methodology of MIAs in the context of VLLMs. Our code and datasets are available at https://github.com/LIONS-EPFL/VL-MIA.
Revisiting character-level adversarial attacks
May 07, 2024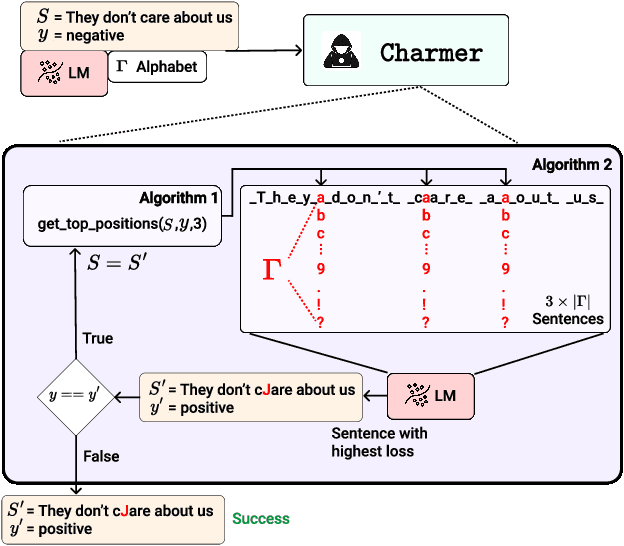

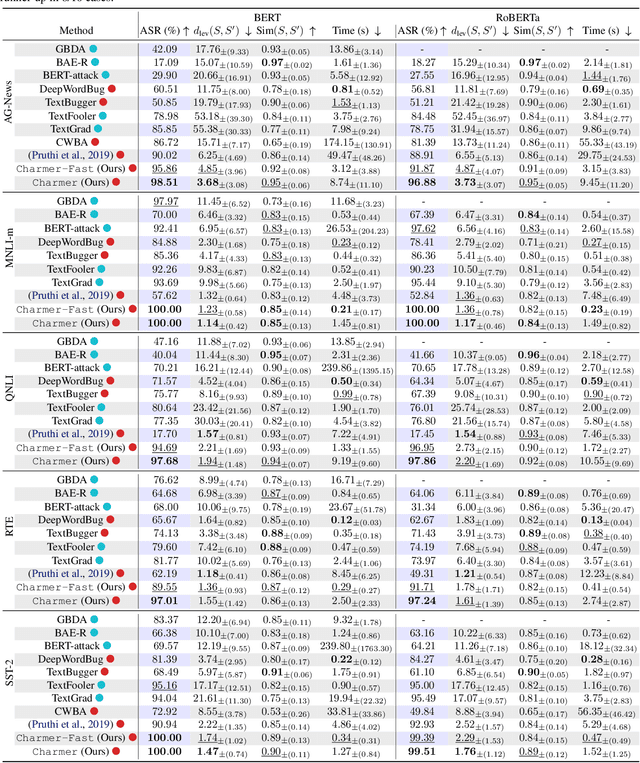
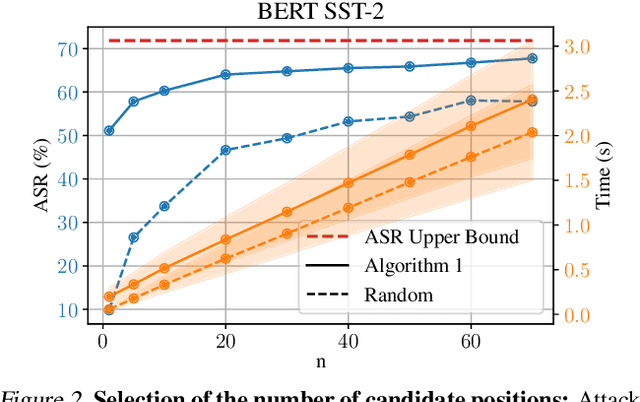
Adversarial attacks in Natural Language Processing apply perturbations in the character or token levels. Token-level attacks, gaining prominence for their use of gradient-based methods, are susceptible to altering sentence semantics, leading to invalid adversarial examples. While character-level attacks easily maintain semantics, they have received less attention as they cannot easily adopt popular gradient-based methods, and are thought to be easy to defend. Challenging these beliefs, we introduce Charmer, an efficient query-based adversarial attack capable of achieving high attack success rate (ASR) while generating highly similar adversarial examples. Our method successfully targets both small (BERT) and large (Llama 2) models. Specifically, on BERT with SST-2, Charmer improves the ASR in 4.84% points and the USE similarity in 8% points with respect to the previous art. Our implementation is available in https://github.com/LIONS-EPFL/Charmer.
Robust NAS under adversarial training: benchmark, theory, and beyond
Mar 19, 2024
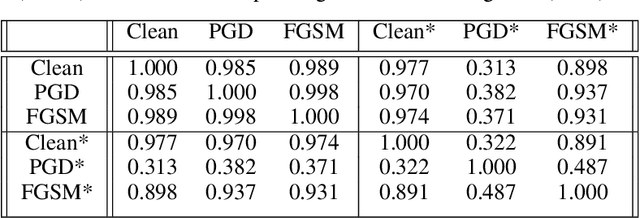
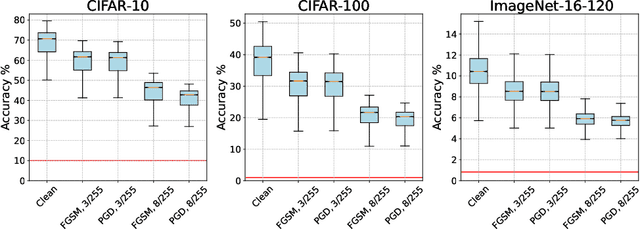

Recent developments in neural architecture search (NAS) emphasize the significance of considering robust architectures against malicious data. However, there is a notable absence of benchmark evaluations and theoretical guarantees for searching these robust architectures, especially when adversarial training is considered. In this work, we aim to address these two challenges, making twofold contributions. First, we release a comprehensive data set that encompasses both clean accuracy and robust accuracy for a vast array of adversarially trained networks from the NAS-Bench-201 search space on image datasets. Then, leveraging the neural tangent kernel (NTK) tool from deep learning theory, we establish a generalization theory for searching architecture in terms of clean accuracy and robust accuracy under multi-objective adversarial training. We firmly believe that our benchmark and theoretical insights will significantly benefit the NAS community through reliable reproducibility, efficient assessment, and theoretical foundation, particularly in the pursuit of robust architectures.
On the Convergence of Encoder-only Shallow Transformers
Nov 02, 2023In this paper, we aim to build the global convergence theory of encoder-only shallow Transformers under a realistic setting from the perspective of architectures, initialization, and scaling under a finite width regime. The difficulty lies in how to tackle the softmax in self-attention mechanism, the core ingredient of Transformer. In particular, we diagnose the scaling scheme, carefully tackle the input/output of softmax, and prove that quadratic overparameterization is sufficient for global convergence of our shallow Transformers under commonly-used He/LeCun initialization in practice. Besides, neural tangent kernel (NTK) based analysis is also given, which facilitates a comprehensive comparison. Our theory demonstrates the separation on the importance of different scaling schemes and initialization. We believe our results can pave the way for a better understanding of modern Transformers, particularly on training dynamics.