 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorrective Diffusion Language Models
Dec 17, 2025
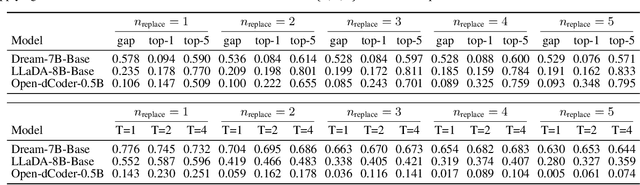
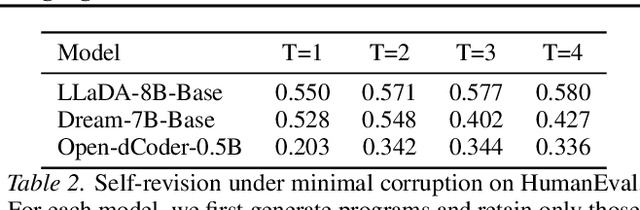
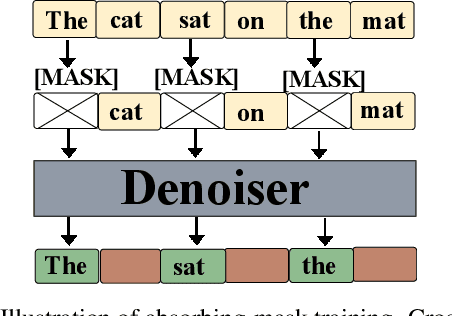
Diffusion language models are structurally well-suited for iterative error correction, as their non-causal denoising dynamics allow arbitrary positions in a sequence to be revised. However, standard masked diffusion language model (MDLM) training fails to reliably induce this behavior, as models often cannot identify unreliable tokens in a complete input, rendering confidence-guided refinement ineffective. We study corrective behavior in diffusion language models, defined as the ability to assign lower confidence to incorrect tokens and iteratively refine them while preserving correct content. We show that this capability is not induced by conventional masked diffusion objectives and propose a correction-oriented post-training principle that explicitly supervises visible incorrect tokens, enabling error-aware confidence and targeted refinement. To evaluate corrective behavior, we introduce the Code Revision Benchmark (CRB), a controllable and executable benchmark for assessing error localization and in-place correction. Experiments on code revision tasks and controlled settings demonstrate that models trained with our approach substantially outperform standard MDLMs in correction scenarios, while also improving pure completion performance. Our code is publicly available at https://github.com/zhangshuibai/CDLM.
Single-pass Detection of Jailbreaking Input in Large Language Models
Feb 21, 2025Defending aligned Large Language Models (LLMs) against jailbreaking attacks is a challenging problem, with existing approaches requiring multiple requests or even queries to auxiliary LLMs, making them computationally heavy. Instead, we focus on detecting jailbreaking input in a single forward pass. Our method, called Single Pass Detection SPD, leverages the information carried by the logits to predict whether the output sentence will be harmful. This allows us to defend in just one forward pass. SPD can not only detect attacks effectively on open-source models, but also minimizes the misclassification of harmless inputs. Furthermore, we show that SPD remains effective even without complete logit access in GPT-3.5 and GPT-4. We believe that our proposed method offers a promising approach to efficiently safeguard LLMs against adversarial attacks.
Certified Robustness Under Bounded Levenshtein Distance
Jan 23, 2025



Text classifiers suffer from small perturbations, that if chosen adversarially, can dramatically change the output of the model. Verification methods can provide robustness certificates against such adversarial perturbations, by computing a sound lower bound on the robust accuracy. Nevertheless, existing verification methods incur in prohibitive costs and cannot practically handle Levenshtein distance constraints. We propose the first method for computing the Lipschitz constant of convolutional classifiers with respect to the Levenshtein distance. We use these Lipschitz constant estimates for training 1-Lipschitz classifiers. This enables computing the certified radius of a classifier in a single forward pass. Our method, LipsLev, is able to obtain $38.80$% and $13.93$% verified accuracy at distance $1$ and $2$ respectively in the AG-News dataset, while being $4$ orders of magnitude faster than existing approaches. We believe our work can open the door to more efficient verification in the text domain.
MIGS: Multi-Identity Gaussian Splatting via Tensor Decomposition
Jul 10, 2024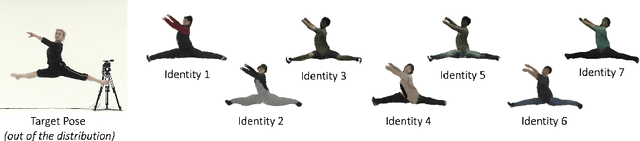

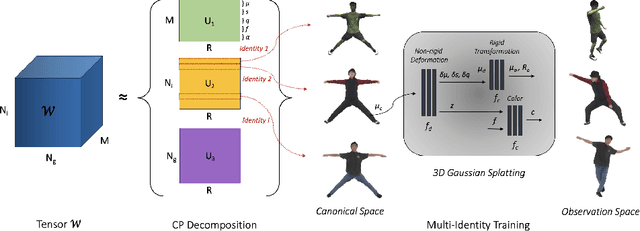

We introduce MIGS (Multi-Identity Gaussian Splatting), a novel method that learns a single neural representation for multiple identities, using only monocular videos. Recent 3D Gaussian Splatting (3DGS) approaches for human avatars require per-identity optimization. However, learning a multi-identity representation presents advantages in robustly animating humans under arbitrary poses. We propose to construct a high-order tensor that combines all the learnable 3DGS parameters for all the training identities. By assuming a low-rank structure and factorizing the tensor, we model the complex rigid and non-rigid deformations of multiple subjects in a unified network, significantly reducing the total number of parameters. Our proposed approach leverages information from all the training identities, enabling robust animation under challenging unseen poses, outperforming existing approaches. We also demonstrate how it can be extended to learn unseen identities.
Revisiting character-level adversarial attacks
May 07, 2024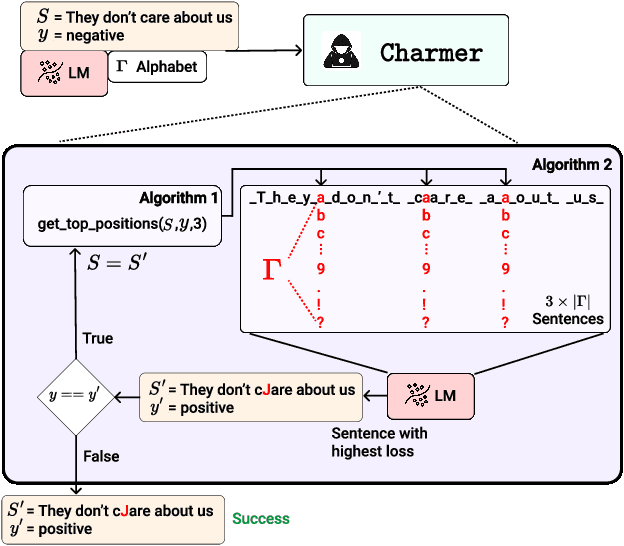

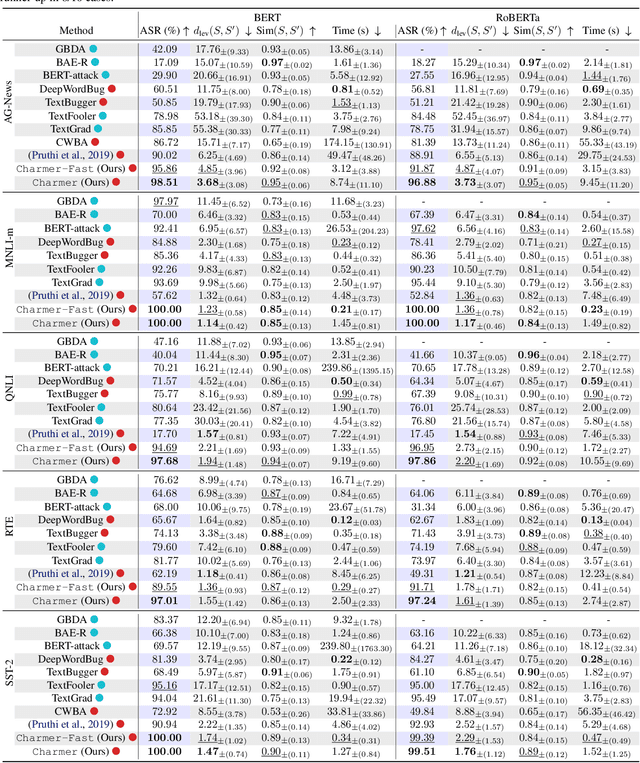
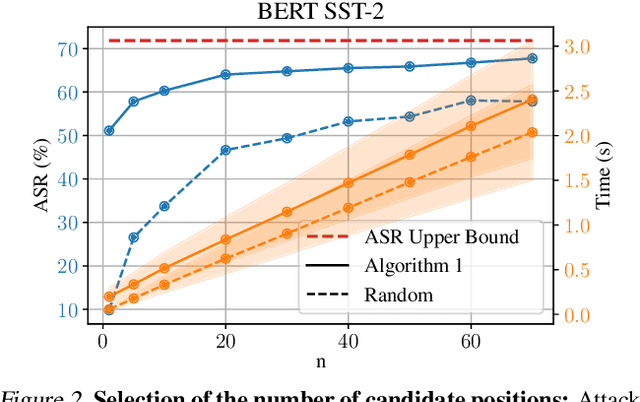
Adversarial attacks in Natural Language Processing apply perturbations in the character or token levels. Token-level attacks, gaining prominence for their use of gradient-based methods, are susceptible to altering sentence semantics, leading to invalid adversarial examples. While character-level attacks easily maintain semantics, they have received less attention as they cannot easily adopt popular gradient-based methods, and are thought to be easy to defend. Challenging these beliefs, we introduce Charmer, an efficient query-based adversarial attack capable of achieving high attack success rate (ASR) while generating highly similar adversarial examples. Our method successfully targets both small (BERT) and large (Llama 2) models. Specifically, on BERT with SST-2, Charmer improves the ASR in 4.84% points and the USE similarity in 8% points with respect to the previous art. Our implementation is available in https://github.com/LIONS-EPFL/Charmer.
MI-NeRF: Learning a Single Face NeRF from Multiple Identities
Apr 03, 2024



In this work, we introduce a method that learns a single dynamic neural radiance field (NeRF) from monocular talking face videos of multiple identities. NeRFs have shown remarkable results in modeling the 4D dynamics and appearance of human faces. However, they require per-identity optimization. Although recent approaches have proposed techniques to reduce the training and rendering time, increasing the number of identities can be expensive. We introduce MI-NeRF (multi-identity NeRF), a single unified network that models complex non-rigid facial motion for multiple identities, using only monocular videos of arbitrary length. The core premise in our method is to learn the non-linear interactions between identity and non-identity specific information with a multiplicative module. By training on multiple videos simultaneously, MI-NeRF not only reduces the total training time compared to standard single-identity NeRFs, but also demonstrates robustness in synthesizing novel expressions for any input identity. We present results for both facial expression transfer and talking face video synthesis. Our method can be further personalized for a target identity given only a short video.
Generalization of Scaled Deep ResNets in the Mean-Field Regime
Mar 14, 2024Despite the widespread empirical success of ResNet, the generalization properties of deep ResNet are rarely explored beyond the lazy training regime. In this work, we investigate \emph{scaled} ResNet in the limit of infinitely deep and wide neural networks, of which the gradient flow is described by a partial differential equation in the large-neural network limit, i.e., the \emph{mean-field} regime. To derive the generalization bounds under this setting, our analysis necessitates a shift from the conventional time-invariant Gram matrix employed in the lazy training regime to a time-variant, distribution-dependent version. To this end, we provide a global lower bound on the minimum eigenvalue of the Gram matrix under the mean-field regime. Besides, for the traceability of the dynamic of Kullback-Leibler (KL) divergence, we establish the linear convergence of the empirical error and estimate the upper bound of the KL divergence over parameters distribution. Finally, we build the uniform convergence for generalization bound via Rademacher complexity. Our results offer new insights into the generalization ability of deep ResNet beyond the lazy training regime and contribute to advancing the understanding of the fundamental properties of deep neural networks.
Multilinear Mixture of Experts: Scalable Expert Specialization through Factorization
Feb 19, 2024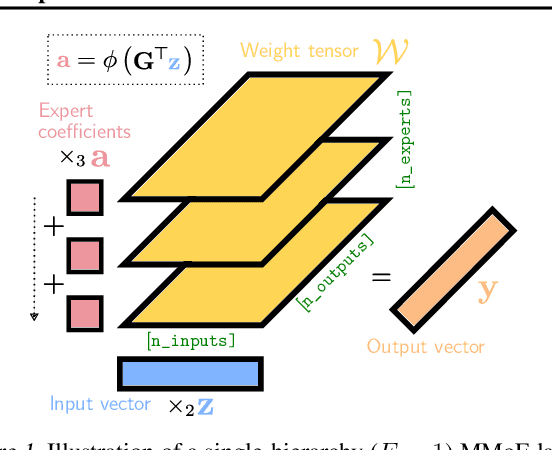



The Mixture of Experts (MoE) paradigm provides a powerful way to decompose inscrutable dense layers into smaller, modular computations often more amenable to human interpretation, debugging, and editability. A major problem however lies in the computational cost of scaling the number of experts to achieve sufficiently fine-grained specialization. In this paper, we propose the Multilinear Mixutre of Experts (MMoE) layer to address this, focusing on vision models. MMoE layers perform an implicit computation on prohibitively large weight tensors entirely in factorized form. Consequently, MMoEs both (1) avoid the issues incurred through the discrete expert routing in the popular 'sparse' MoE models, yet (2) do not incur the restrictively high inference-time costs of 'soft' MoE alternatives. We present both qualitative and quantitative evidence (through visualization and counterfactual interventions respectively) that scaling MMoE layers when fine-tuning foundation models for vision tasks leads to more specialized experts at the class-level whilst remaining competitive with the performance of parameter-matched linear layer counterparts. Finally, we show that learned expert specialism further facilitates manual correction of demographic bias in CelebA attribute classification. Our MMoE model code is available at https://github.com/james-oldfield/MMoE.
Leveraging the Context through Multi-Round Interactions for Jailbreaking Attacks
Feb 14, 2024



Large Language Models (LLMs) are susceptible to Jailbreaking attacks, which aim to extract harmful information by subtly modifying the attack query. As defense mechanisms evolve, directly obtaining harmful information becomes increasingly challenging for Jailbreaking attacks. In this work, inspired by human practices of indirect context to elicit harmful information, we focus on a new attack form called Contextual Interaction Attack. The idea relies on the autoregressive nature of the generation process in LLMs. We contend that the prior context--the information preceding the attack query--plays a pivotal role in enabling potent Jailbreaking attacks. Specifically, we propose an approach that leverages preliminary question-answer pairs to interact with the LLM. By doing so, we guide the responses of the model toward revealing the 'desired' harmful information. We conduct experiments on four different LLMs and demonstrate the efficacy of this attack, which is black-box and can also transfer across LLMs. We believe this can lead to further developments and understanding of the context vector in LLMs.
Multilinear Operator Networks
Jan 31, 2024Despite the remarkable capabilities of deep neural networks in image recognition, the dependence on activation functions remains a largely unexplored area and has yet to be eliminated. On the other hand, Polynomial Networks is a class of models that does not require activation functions, but have yet to perform on par with modern architectures. In this work, we aim close this gap and propose MONet, which relies solely on multilinear operators. The core layer of MONet, called Mu-Layer, captures multiplicative interactions of the elements of the input token. MONet captures high-degree interactions of the input elements and we demonstrate the efficacy of our approach on a series of image recognition and scientific computing benchmarks. The proposed model outperforms prior polynomial networks and performs on par with modern architectures. We believe that MONet can inspire further research on models that use entirely multilinear operations.