 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolySAE: Modeling Feature Interactions in Sparse Autoencoders via Polynomial Decoding
Feb 01, 2026Sparse autoencoders (SAEs) have emerged as a promising method for interpreting neural network representations by decomposing activations into sparse combinations of dictionary atoms. However, SAEs assume that features combine additively through linear reconstruction, an assumption that cannot capture compositional structure: linear models cannot distinguish whether "Starbucks" arises from the composition of "star" and "coffee" features or merely their co-occurrence. This forces SAEs to allocate monolithic features for compound concepts rather than decomposing them into interpretable constituents. We introduce PolySAE, which extends the SAE decoder with higher-order terms to model feature interactions while preserving the linear encoder essential for interpretability. Through low-rank tensor factorization on a shared projection subspace, PolySAE captures pairwise and triple feature interactions with small parameter overhead (3% on GPT2). Across four language models and three SAE variants, PolySAE achieves an average improvement of approximately 8% in probing F1 while maintaining comparable reconstruction error, and produces 2-10$\times$ larger Wasserstein distances between class-conditional feature distributions. Critically, learned interaction weights exhibit negligible correlation with co-occurrence frequency ($r = 0.06$ vs. $r = 0.82$ for SAE feature covariance), suggesting that polynomial terms capture compositional structure, such as morphological binding and phrasal composition, largely independent of surface statistics.
Towards Interpretability Without Sacrifice: Faithful Dense Layer Decomposition with Mixture of Decoders
May 27, 2025Multilayer perceptrons (MLPs) are an integral part of large language models, yet their dense representations render them difficult to understand, edit, and steer. Recent methods learn interpretable approximations via neuron-level sparsity, yet fail to faithfully reconstruct the original mapping--significantly increasing model's next-token cross-entropy loss. In this paper, we advocate for moving to layer-level sparsity to overcome the accuracy trade-off in sparse layer approximation. Under this paradigm, we introduce Mixture of Decoders (MxDs). MxDs generalize MLPs and Gated Linear Units, expanding pre-trained dense layers into tens of thousands of specialized sublayers. Through a flexible form of tensor factorization, each sparsely activating MxD sublayer implements a linear transformation with full-rank weights--preserving the original decoders' expressive capacity even under heavy sparsity. Experimentally, we show that MxDs significantly outperform state-of-the-art methods (e.g., Transcoders) on the sparsity-accuracy frontier in language models with up to 3B parameters. Further evaluations on sparse probing and feature steering demonstrate that MxDs learn similarly specialized features of natural language--opening up a promising new avenue for designing interpretable yet faithful decompositions. Our code is included at: https://github.com/james-oldfield/MxD/.
Multilinear Mixture of Experts: Scalable Expert Specialization through Factorization
Feb 19, 2024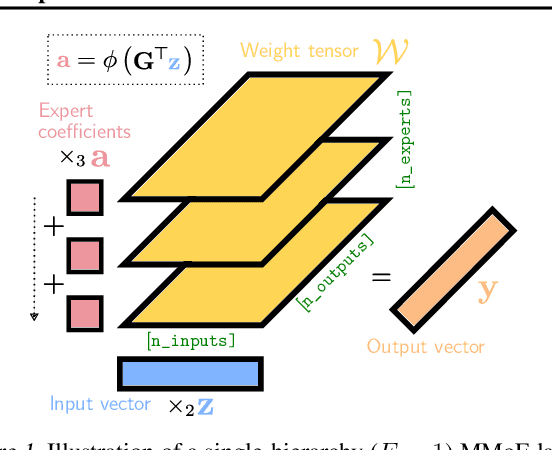



The Mixture of Experts (MoE) paradigm provides a powerful way to decompose inscrutable dense layers into smaller, modular computations often more amenable to human interpretation, debugging, and editability. A major problem however lies in the computational cost of scaling the number of experts to achieve sufficiently fine-grained specialization. In this paper, we propose the Multilinear Mixutre of Experts (MMoE) layer to address this, focusing on vision models. MMoE layers perform an implicit computation on prohibitively large weight tensors entirely in factorized form. Consequently, MMoEs both (1) avoid the issues incurred through the discrete expert routing in the popular 'sparse' MoE models, yet (2) do not incur the restrictively high inference-time costs of 'soft' MoE alternatives. We present both qualitative and quantitative evidence (through visualization and counterfactual interventions respectively) that scaling MMoE layers when fine-tuning foundation models for vision tasks leads to more specialized experts at the class-level whilst remaining competitive with the performance of parameter-matched linear layer counterparts. Finally, we show that learned expert specialism further facilitates manual correction of demographic bias in CelebA attribute classification. Our MMoE model code is available at https://github.com/james-oldfield/MMoE.
Parts of Speech-Grounded Subspaces in Vision-Language Models
May 23, 2023

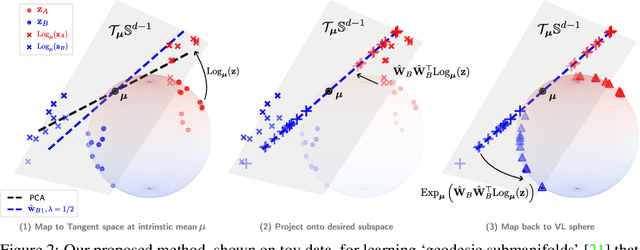
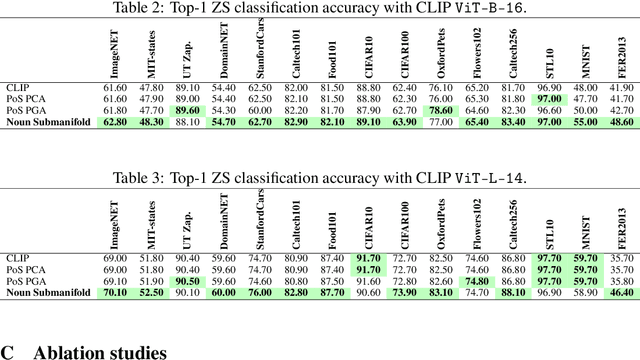
Latent image representations arising from vision-language models have proved immensely useful for a variety of downstream tasks. However, their utility is limited by their entanglement with respect to different visual attributes. For instance, recent work has shown that CLIP image representations are often biased toward specific visual properties (such as objects or actions) in an unpredictable manner. In this paper, we propose to separate representations of the different visual modalities in CLIP's joint vision-language space by leveraging the association between parts of speech and specific visual modes of variation (e.g. nouns relate to objects, adjectives describe appearance). This is achieved by formulating an appropriate component analysis model that learns subspaces capturing variability corresponding to a specific part of speech, while jointly minimising variability to the rest. Such a subspace yields disentangled representations of the different visual properties of an image or text in closed form while respecting the underlying geometry of the manifold on which the representations lie. What's more, we show the proposed model additionally facilitates learning subspaces corresponding to specific visual appearances (e.g. artists' painting styles), which enables the selective removal of entire visual themes from CLIP-based text-to-image synthesis. We validate the model both qualitatively, by visualising the subspace projections with a text-to-image model and by preventing the imitation of artists' styles, and quantitatively, through class invariance metrics and improvements to baseline zero-shot classification. Our code is available at: https://github.com/james-oldfield/PoS-subspaces.
ContraCLIP: Interpretable GAN generation driven by pairs of contrasting sentences
Jun 05, 2022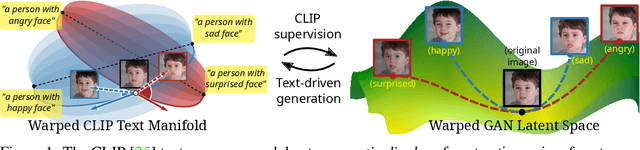
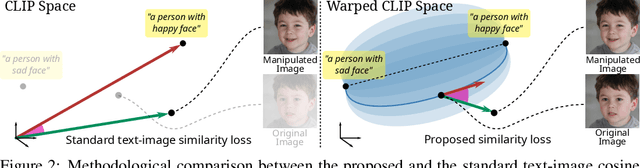

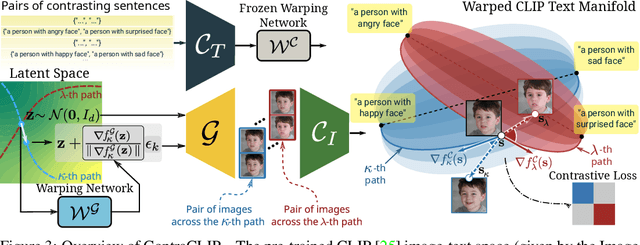
This work addresses the problem of discovering non-linear interpretable paths in the latent space of pre-trained GANs in a model-agnostic manner. In the proposed method, the discovery is driven by a set of pairs of natural language sentences with contrasting semantics, named semantic dipoles, that serve as the limits of the interpretation that we require by the trainable latent paths to encode. By using the pre-trained CLIP encoder, the sentences are projected into the vision-language space, where they serve as dipoles, and where RBF-based warping functions define a set of non-linear directional paths, one for each semantic dipole, allowing in this way traversals from one semantic pole to the other. By defining an objective that discovers paths in the latent space of GANs that generate changes along the desired paths in the vision-language embedding space, we provide an intuitive way of controlling the underlying generative factors and address some of the limitations of the state-of-the-art works, namely, that a) they are typically tailored to specific GAN architectures (i.e., StyleGAN), b) they disregard the relative position of the manipulated and the original image in the image embedding and the relative position of the image and the text embeddings, and c) they lead to abrupt image manipulations and quickly arrive at regions of low density and, thus, low image quality, providing limited control of the generative factors. We provide extensive qualitative and quantitative results that demonstrate our claims with two pre-trained GANs, and make the code and the pre-trained models publicly available at: https://github.com/chi0tzp/ContraCLIP
PandA: Unsupervised Learning of Parts and Appearances in the Feature Maps of GANs
May 31, 2022

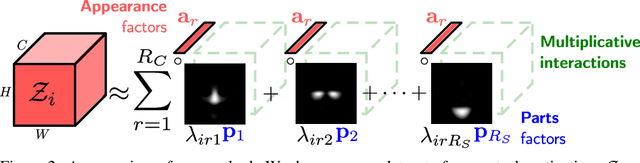
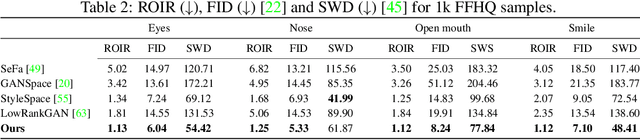
Recent advances in the understanding of Generative Adversarial Networks (GANs) have led to remarkable progress in visual editing and synthesis tasks, capitalizing on the rich semantics that are embedded in the latent spaces of pre-trained GANs. However, existing methods are often tailored to specific GAN architectures and are limited to either discovering global semantic directions that do not facilitate localized control, or require some form of supervision through manually provided regions or segmentation masks. In this light, we present an architecture-agnostic approach that jointly discovers factors representing spatial parts and their appearances in an entirely unsupervised fashion. These factors are obtained by applying a semi-nonnegative tensor factorization on the feature maps, which in turn enables context-aware local image editing with pixel-level control. In addition, we show that the discovered appearance factors correspond to saliency maps that localize concepts of interest, without using any labels. Experiments on a wide range of GAN architectures and datasets show that, in comparison to the state of the art, our method is far more efficient in terms of training time and, most importantly, provides much more accurate localized control. Our code is available at: https://github.com/james-oldfield/PandA.
Cluster-guided Image Synthesis with Unconditional Models
Dec 24, 2021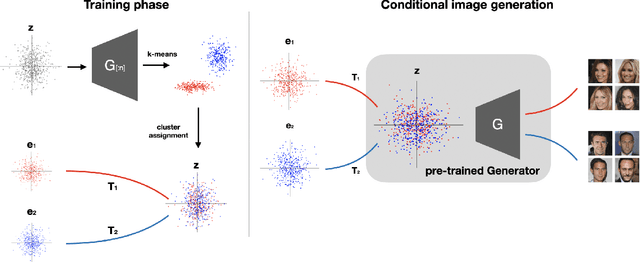
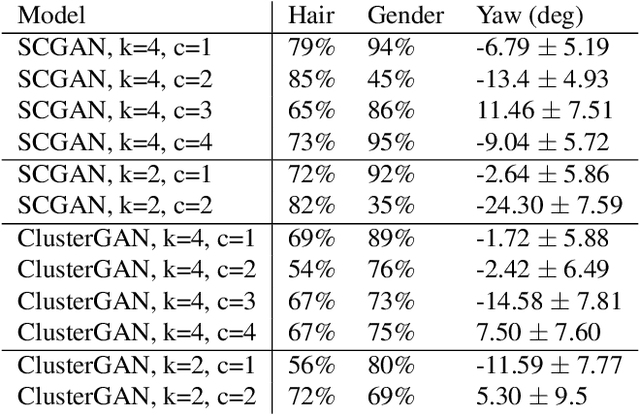

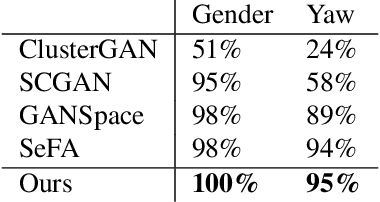
Generative Adversarial Networks (GANs) are the driving force behind the state-of-the-art in image generation. Despite their ability to synthesize high-resolution photo-realistic images, generating content with on-demand conditioning of different granularity remains a challenge. This challenge is usually tackled by annotating massive datasets with the attributes of interest, a laborious task that is not always a viable option. Therefore, it is vital to introduce control into the generation process of unsupervised generative models. In this work, we focus on controllable image generation by leveraging GANs that are well-trained in an unsupervised fashion. To this end, we discover that the representation space of intermediate layers of the generator forms a number of clusters that separate the data according to semantically meaningful attributes (e.g., hair color and pose). By conditioning on the cluster assignments, the proposed method is able to control the semantic class of the generated image. Our approach enables sampling from each cluster by Implicit Maximum Likelihood Estimation (IMLE). We showcase the efficacy of our approach on faces (CelebA-HQ and FFHQ), animals (Imagenet) and objects (LSUN) using different pre-trained generative models. The results highlight the ability of our approach to condition image generation on attributes like gender, pose and hair style on faces, as well as a variety of features on different object classes.
Tensor Component Analysis for Interpreting the Latent Space of GANs
Nov 23, 2021
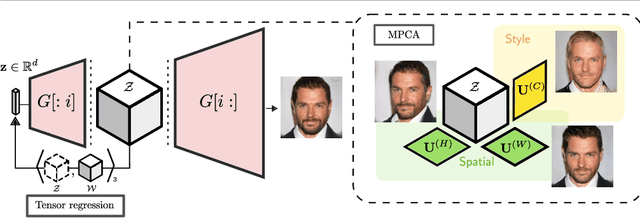
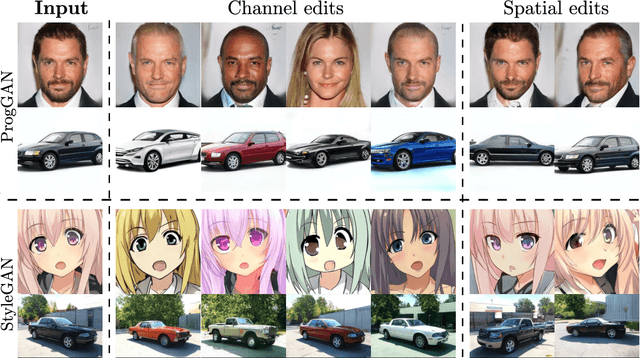

This paper addresses the problem of finding interpretable directions in the latent space of pre-trained Generative Adversarial Networks (GANs) to facilitate controllable image synthesis. Such interpretable directions correspond to transformations that can affect both the style and geometry of the synthetic images. However, existing approaches that utilise linear techniques to find these transformations often fail to provide an intuitive way to separate these two sources of variation. To address this, we propose to a) perform a multilinear decomposition of the tensor of intermediate representations, and b) use a tensor-based regression to map directions found using this decomposition to the latent space. Our scheme allows for both linear edits corresponding to the individual modes of the tensor, and non-linear ones that model the multiplicative interactions between them. We show experimentally that we can utilise the former to better separate style- from geometry-based transformations, and the latter to generate an extended set of possible transformations in comparison to prior works. We demonstrate our approach's efficacy both quantitatively and qualitatively compared to the current state-of-the-art.
Tensor Methods in Computer Vision and Deep Learning
Jul 07, 2021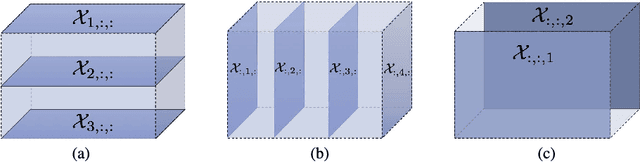
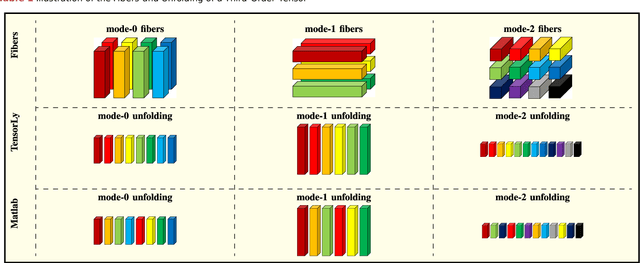
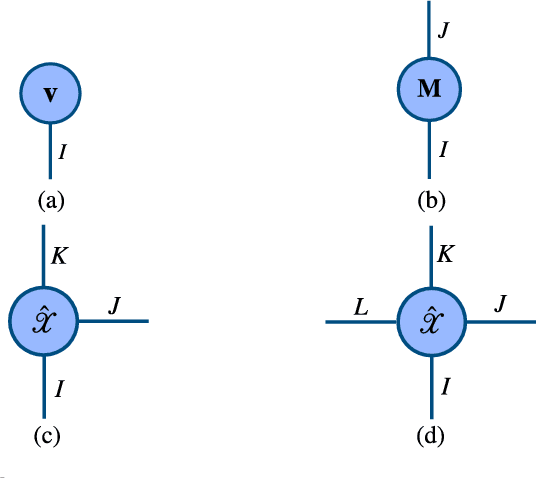
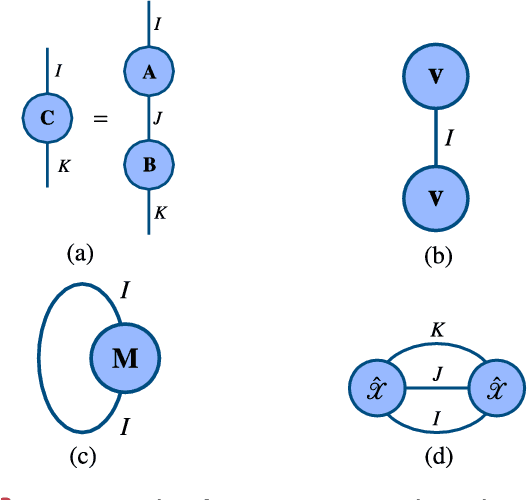
Tensors, or multidimensional arrays, are data structures that can naturally represent visual data of multiple dimensions. Inherently able to efficiently capture structured, latent semantic spaces and high-order interactions, tensors have a long history of applications in a wide span of computer vision problems. With the advent of the deep learning paradigm shift in computer vision, tensors have become even more fundamental. Indeed, essential ingredients in modern deep learning architectures, such as convolutions and attention mechanisms, can readily be considered as tensor mappings. In effect, tensor methods are increasingly finding significant applications in deep learning, including the design of memory and compute efficient network architectures, improving robustness to random noise and adversarial attacks, and aiding the theoretical understanding of deep networks. This article provides an in-depth and practical review of tensors and tensor methods in the context of representation learning and deep learning, with a particular focus on visual data analysis and computer vision applications. Concretely, besides fundamental work in tensor-based visual data analysis methods, we focus on recent developments that have brought on a gradual increase of tensor methods, especially in deep learning architectures, and their implications in computer vision applications. To further enable the newcomer to grasp such concepts quickly, we provide companion Python notebooks, covering key aspects of the paper and implementing them, step-by-step with TensorLy.
Enhancing Facial Data Diversity with Style-based Face Aging
Jun 06, 2020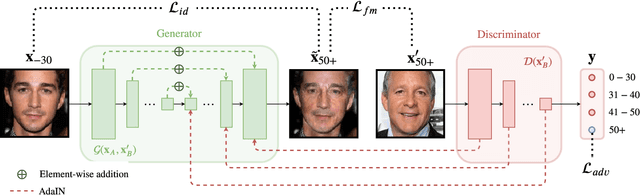
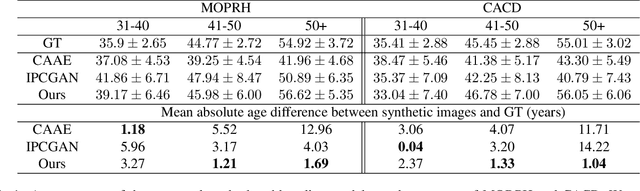


A significant limiting factor in training fair classifiers relates to the presence of dataset bias. In particular, face datasets are typically biased in terms of attributes such as gender, age, and race. If not mitigated, bias leads to algorithms that exhibit unfair behaviour towards such groups. In this work, we address the problem of increasing the diversity of face datasets with respect to age. Concretely, we propose a novel, generative style-based architecture for data augmentation that captures fine-grained aging patterns by conditioning on multi-resolution age-discriminative representations. By evaluating on several age-annotated datasets in both single- and cross-database experiments, we show that the proposed method outperforms state-of-the-art algorithms for age transfer, especially in the case of age groups that lie in the tails of the label distribution. We further show significantly increased diversity in the augmented datasets, outperforming all compared methods according to established metrics.