 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Principled Framework for Multi-View Contrastive Learning
Jul 09, 2025Contrastive Learning (CL), a leading paradigm in Self-Supervised Learning (SSL), typically relies on pairs of data views generated through augmentation. While multiple augmentations per instance (more than two) improve generalization in supervised learning, current CL methods handle additional views suboptimally by simply aggregating different pairwise objectives. This approach suffers from four critical limitations: (L1) it utilizes multiple optimization terms per data point resulting to conflicting objectives, (L2) it fails to model all interactions across views and data points, (L3) it inherits fundamental limitations (e.g. alignment-uniformity coupling) from pairwise CL losses, and (L4) it prevents fully realizing the benefits of increased view multiplicity observed in supervised settings. We address these limitations through two novel loss functions: MV-InfoNCE, which extends InfoNCE to incorporate all possible view interactions simultaneously in one term per data point, and MV-DHEL, which decouples alignment from uniformity across views while scaling interaction complexity with view multiplicity. Both approaches are theoretically grounded - we prove they asymptotically optimize for alignment of all views and uniformity, providing principled extensions to multi-view contrastive learning. Our empirical results on ImageNet1K and three other datasets demonstrate that our methods consistently outperform existing multi-view approaches and effectively scale with increasing view multiplicity. We also apply our objectives to multimodal data and show that, in contrast to other contrastive objectives, they can scale beyond just two modalities. Most significantly, ablation studies reveal that MV-DHEL with five or more views effectively mitigates dimensionality collapse by fully utilizing the embedding space, thereby delivering multi-view benefits observed in supervised learning.
Towards Interpretability Without Sacrifice: Faithful Dense Layer Decomposition with Mixture of Decoders
May 27, 2025Multilayer perceptrons (MLPs) are an integral part of large language models, yet their dense representations render them difficult to understand, edit, and steer. Recent methods learn interpretable approximations via neuron-level sparsity, yet fail to faithfully reconstruct the original mapping--significantly increasing model's next-token cross-entropy loss. In this paper, we advocate for moving to layer-level sparsity to overcome the accuracy trade-off in sparse layer approximation. Under this paradigm, we introduce Mixture of Decoders (MxDs). MxDs generalize MLPs and Gated Linear Units, expanding pre-trained dense layers into tens of thousands of specialized sublayers. Through a flexible form of tensor factorization, each sparsely activating MxD sublayer implements a linear transformation with full-rank weights--preserving the original decoders' expressive capacity even under heavy sparsity. Experimentally, we show that MxDs significantly outperform state-of-the-art methods (e.g., Transcoders) on the sparsity-accuracy frontier in language models with up to 3B parameters. Further evaluations on sparse probing and feature steering demonstrate that MxDs learn similarly specialized features of natural language--opening up a promising new avenue for designing interpretable yet faithful decompositions. Our code is included at: https://github.com/james-oldfield/MxD/.
Enabling Local Editing in Diffusion Models by Joint and Individual Component Analysis
Sep 02, 2024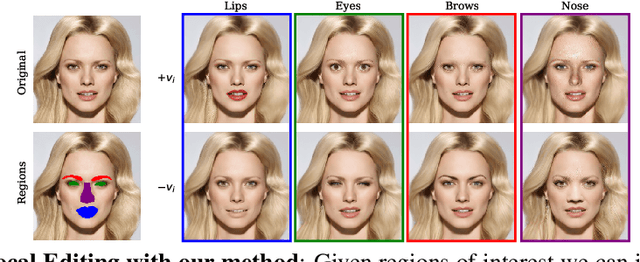

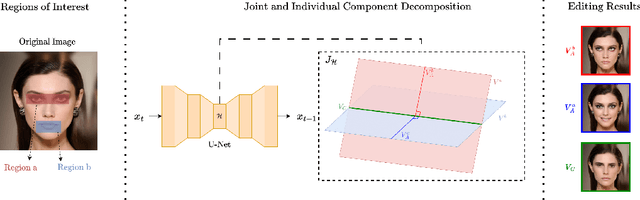

Recent advances in Diffusion Models (DMs) have led to significant progress in visual synthesis and editing tasks, establishing them as a strong competitor to Generative Adversarial Networks (GANs). However, the latent space of DMs is not as well understood as that of GANs. Recent research has focused on unsupervised semantic discovery in the latent space of DMs by leveraging the bottleneck layer of the denoising network, which has been shown to exhibit properties of a semantic latent space. However, these approaches are limited to discovering global attributes. In this paper we address, the challenge of local image manipulation in DMs and introduce an unsupervised method to factorize the latent semantics learned by the denoising network of pre-trained DMs. Given an arbitrary image and defined regions of interest, we utilize the Jacobian of the denoising network to establish a relation between the regions of interest and their corresponding subspaces in the latent space. Furthermore, we disentangle the joint and individual components of these subspaces to identify latent directions that enable local image manipulation. Once discovered, these directions can be applied to different images to produce semantically consistent edits, making our method suitable for practical applications. Experimental results on various datasets demonstrate that our method can produce semantic edits that are more localized and have better fidelity compared to the state-of-the-art.
Multilinear Mixture of Experts: Scalable Expert Specialization through Factorization
Feb 19, 2024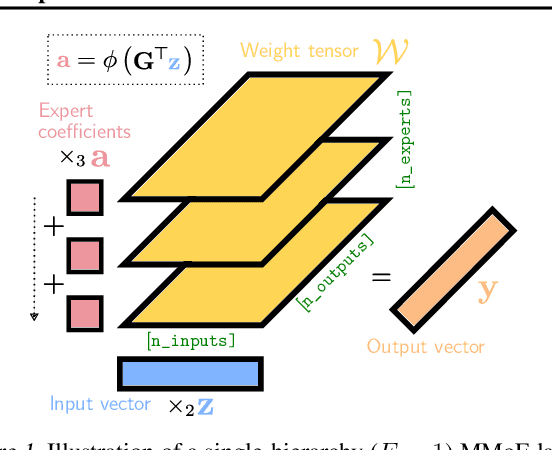



The Mixture of Experts (MoE) paradigm provides a powerful way to decompose inscrutable dense layers into smaller, modular computations often more amenable to human interpretation, debugging, and editability. A major problem however lies in the computational cost of scaling the number of experts to achieve sufficiently fine-grained specialization. In this paper, we propose the Multilinear Mixutre of Experts (MMoE) layer to address this, focusing on vision models. MMoE layers perform an implicit computation on prohibitively large weight tensors entirely in factorized form. Consequently, MMoEs both (1) avoid the issues incurred through the discrete expert routing in the popular 'sparse' MoE models, yet (2) do not incur the restrictively high inference-time costs of 'soft' MoE alternatives. We present both qualitative and quantitative evidence (through visualization and counterfactual interventions respectively) that scaling MMoE layers when fine-tuning foundation models for vision tasks leads to more specialized experts at the class-level whilst remaining competitive with the performance of parameter-matched linear layer counterparts. Finally, we show that learned expert specialism further facilitates manual correction of demographic bias in CelebA attribute classification. Our MMoE model code is available at https://github.com/james-oldfield/MMoE.
Locality-preserving Directions for Interpreting the Latent Space of Satellite Image GANs
Sep 26, 2023



We present a locality-aware method for interpreting the latent space of wavelet-based Generative Adversarial Networks (GANs), that can well capture the large spatial and spectral variability that is characteristic to satellite imagery. By focusing on preserving locality, the proposed method is able to decompose the weight-space of pre-trained GANs and recover interpretable directions that correspond to high-level semantic concepts (such as urbanization, structure density, flora presence) - that can subsequently be used for guided synthesis of satellite imagery. In contrast to typically used approaches that focus on capturing the variability of the weight-space in a reduced dimensionality space (i.e., based on Principal Component Analysis, PCA), we show that preserving locality leads to vectors with different angles, that are more robust to artifacts and can better preserve class information. Via a set of quantitative and qualitative examples, we further show that the proposed approach can outperform both baseline geometric augmentations, as well as global, PCA-based approaches for data synthesis in the context of data augmentation for satellite scene classification.
Parts of Speech-Grounded Subspaces in Vision-Language Models
May 23, 2023

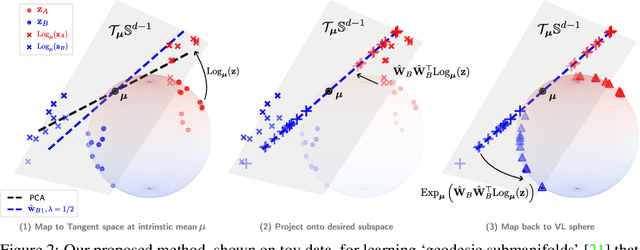
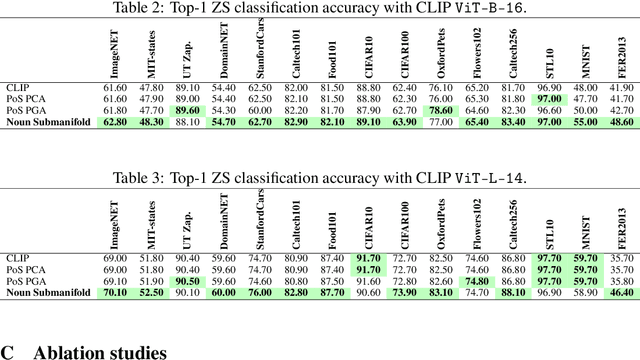
Latent image representations arising from vision-language models have proved immensely useful for a variety of downstream tasks. However, their utility is limited by their entanglement with respect to different visual attributes. For instance, recent work has shown that CLIP image representations are often biased toward specific visual properties (such as objects or actions) in an unpredictable manner. In this paper, we propose to separate representations of the different visual modalities in CLIP's joint vision-language space by leveraging the association between parts of speech and specific visual modes of variation (e.g. nouns relate to objects, adjectives describe appearance). This is achieved by formulating an appropriate component analysis model that learns subspaces capturing variability corresponding to a specific part of speech, while jointly minimising variability to the rest. Such a subspace yields disentangled representations of the different visual properties of an image or text in closed form while respecting the underlying geometry of the manifold on which the representations lie. What's more, we show the proposed model additionally facilitates learning subspaces corresponding to specific visual appearances (e.g. artists' painting styles), which enables the selective removal of entire visual themes from CLIP-based text-to-image synthesis. We validate the model both qualitatively, by visualising the subspace projections with a text-to-image model and by preventing the imitation of artists' styles, and quantitatively, through class invariance metrics and improvements to baseline zero-shot classification. Our code is available at: https://github.com/james-oldfield/PoS-subspaces.
Unsupervised Discovery of Semantic Concepts in Satellite Imagery with Style-based Wavelet-driven Generative Models
Aug 03, 2022


In recent years, considerable advancements have been made in the area of Generative Adversarial Networks (GANs), particularly with the advent of style-based architectures that address many key shortcomings - both in terms of modeling capabilities and network interpretability. Despite these improvements, the adoption of such approaches in the domain of satellite imagery is not straightforward. Typical vision datasets used in generative tasks are well-aligned and annotated, and exhibit limited variability. In contrast, satellite imagery exhibits great spatial and spectral variability, wide presence of fine, high-frequency details, while the tedious nature of annotating satellite imagery leads to annotation scarcity - further motivating developments in unsupervised learning. In this light, we present the first pre-trained style- and wavelet-based GAN model that can readily synthesize a wide gamut of realistic satellite images in a variety of settings and conditions - while also preserving high-frequency information. Furthermore, we show that by analyzing the intermediate activations of our network, one can discover a multitude of interpretable semantic directions that facilitate the guided synthesis of satellite images in terms of high-level concepts (e.g., urbanization) without using any form of supervision. Via a set of qualitative and quantitative experiments we demonstrate the efficacy of our framework, in terms of suitability for downstream tasks (e.g., data augmentation), quality of synthetic imagery, as well as generalization capabilities to unseen datasets.
PandA: Unsupervised Learning of Parts and Appearances in the Feature Maps of GANs
May 31, 2022

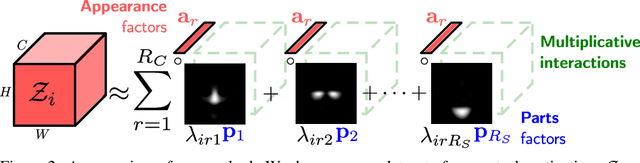
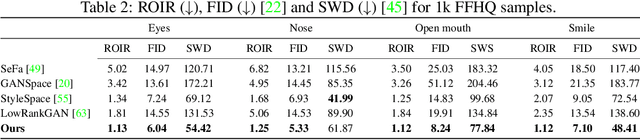
Recent advances in the understanding of Generative Adversarial Networks (GANs) have led to remarkable progress in visual editing and synthesis tasks, capitalizing on the rich semantics that are embedded in the latent spaces of pre-trained GANs. However, existing methods are often tailored to specific GAN architectures and are limited to either discovering global semantic directions that do not facilitate localized control, or require some form of supervision through manually provided regions or segmentation masks. In this light, we present an architecture-agnostic approach that jointly discovers factors representing spatial parts and their appearances in an entirely unsupervised fashion. These factors are obtained by applying a semi-nonnegative tensor factorization on the feature maps, which in turn enables context-aware local image editing with pixel-level control. In addition, we show that the discovered appearance factors correspond to saliency maps that localize concepts of interest, without using any labels. Experiments on a wide range of GAN architectures and datasets show that, in comparison to the state of the art, our method is far more efficient in terms of training time and, most importantly, provides much more accurate localized control. Our code is available at: https://github.com/james-oldfield/PandA.
Tensor Component Analysis for Interpreting the Latent Space of GANs
Nov 23, 2021
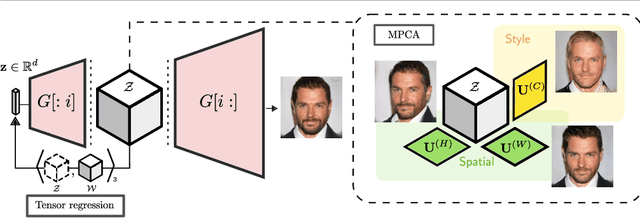
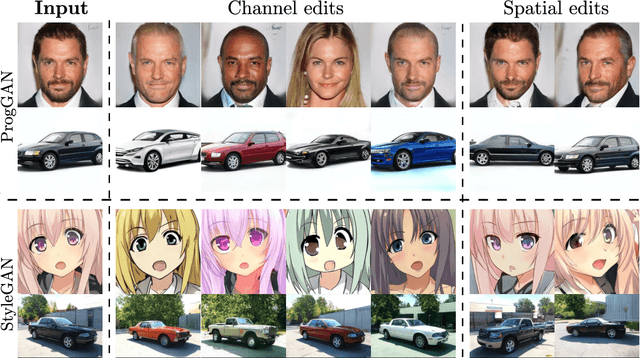

This paper addresses the problem of finding interpretable directions in the latent space of pre-trained Generative Adversarial Networks (GANs) to facilitate controllable image synthesis. Such interpretable directions correspond to transformations that can affect both the style and geometry of the synthetic images. However, existing approaches that utilise linear techniques to find these transformations often fail to provide an intuitive way to separate these two sources of variation. To address this, we propose to a) perform a multilinear decomposition of the tensor of intermediate representations, and b) use a tensor-based regression to map directions found using this decomposition to the latent space. Our scheme allows for both linear edits corresponding to the individual modes of the tensor, and non-linear ones that model the multiplicative interactions between them. We show experimentally that we can utilise the former to better separate style- from geometry-based transformations, and the latter to generate an extended set of possible transformations in comparison to prior works. We demonstrate our approach's efficacy both quantitatively and qualitatively compared to the current state-of-the-art.
Classification of Influenza Hemagglutinin Protein Sequences using Convolutional Neural Networks
Aug 09, 2021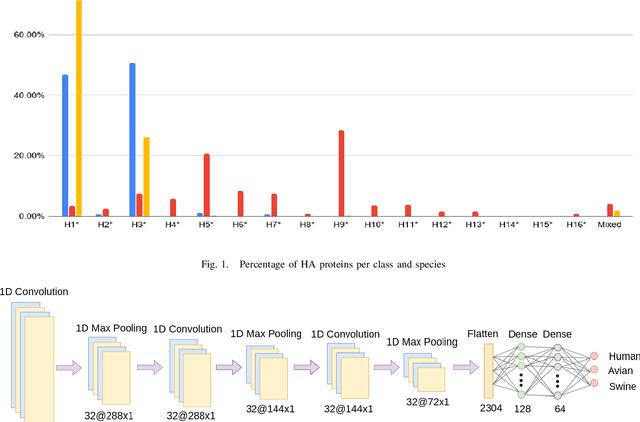
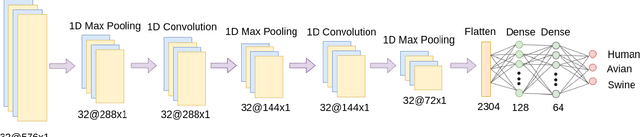


The Influenza virus can be considered as one of the most severe viruses that can infect multiple species with often fatal consequences to the hosts. The Hemagglutinin (HA) gene of the virus can be a target for antiviral drug development realised through accurate identification of its sub-types and possible the targeted hosts. This paper focuses on accurately predicting if an Influenza type A virus can infect specific hosts, and more specifically, Human, Avian and Swine hosts, using only the protein sequence of the HA gene. In more detail, we propose encoding the protein sequences into numerical signals using the Hydrophobicity Index and subsequently utilising a Convolutional Neural Network-based predictive model. The Influenza HA protein sequences used in the proposed work are obtained from the Influenza Research Database (IRD). Specifically, complete and unique HA protein sequences were used for avian, human and swine hosts. The data obtained for this work was 17999 human-host proteins, 17667 avian-host proteins and 9278 swine-host proteins. Given this set of collected proteins, the proposed method yields as much as 10% higher accuracy for an individual class (namely, Avian) and 5% higher overall accuracy than in an earlier study. It is also observed that the accuracy for each class in this work is more balanced than what was presented in this earlier study. As the results show, the proposed model can distinguish HA protein sequences with high accuracy whenever the virus under investigation can infect Human, Avian or Swine hosts.