 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetanetworks as Regulatory Operators: Learning to Edit for Requirement Compliance
Dec 17, 2025As machine learning models are increasingly deployed in high-stakes settings, e.g. as decision support systems in various societal sectors or in critical infrastructure, designers and auditors are facing the need to ensure that models satisfy a wider variety of requirements (e.g. compliance with regulations, fairness, computational constraints) beyond performance. Although most of them are the subject of ongoing studies, typical approaches face critical challenges: post-processing methods tend to compromise performance, which is often counteracted by fine-tuning or, worse, training from scratch, an often time-consuming or even unavailable strategy. This raises the following question: "Can we efficiently edit models to satisfy requirements, without sacrificing their utility?" In this work, we approach this with a unifying framework, in a data-driven manner, i.e. we learn to edit neural networks (NNs), where the editor is an NN itself - a graph metanetwork - and editing amounts to a single inference step. In particular, the metanetwork is trained on NN populations to minimise an objective consisting of two terms: the requirement to be enforced and the preservation of the NN's utility. We experiment with diverse tasks (the data minimisation principle, bias mitigation and weight pruning) improving the trade-offs between performance, requirement satisfaction and time efficiency compared to popular post-processing or re-training alternatives.
Exposing Hidden Biases in Text-to-Image Models via Automated Prompt Search
Dec 09, 2025Text-to-image (TTI) diffusion models have achieved remarkable visual quality, yet they have been repeatedly shown to exhibit social biases across sensitive attributes such as gender, race and age. To mitigate these biases, existing approaches frequently depend on curated prompt datasets - either manually constructed or generated with large language models (LLMs) - as part of their training and/or evaluation procedures. Beside the curation cost, this also risks overlooking unanticipated, less obvious prompts that trigger biased generation, even in models that have undergone debiasing. In this work, we introduce Bias-Guided Prompt Search (BGPS), a framework that automatically generates prompts that aim to maximize the presence of biases in the resulting images. BGPS comprises two components: (1) an LLM instructed to produce attribute-neutral prompts and (2) attribute classifiers acting on the TTI's internal representations that steer the decoding process of the LLM toward regions of the prompt space that amplify the image attributes of interest. We conduct extensive experiments on Stable Diffusion 1.5 and a state-of-the-art debiased model and discover an array of subtle and previously undocumented biases that severely deteriorate fairness metrics. Crucially, the discovered prompts are interpretable, i.e they may be entered by a typical user, quantitatively improving the perplexity metric compared to a prominent hard prompt optimization counterpart. Our findings uncover TTI vulnerabilities, while BGPS expands the bias search space and can act as a new evaluation tool for bias mitigation.
A Principled Framework for Multi-View Contrastive Learning
Jul 09, 2025Contrastive Learning (CL), a leading paradigm in Self-Supervised Learning (SSL), typically relies on pairs of data views generated through augmentation. While multiple augmentations per instance (more than two) improve generalization in supervised learning, current CL methods handle additional views suboptimally by simply aggregating different pairwise objectives. This approach suffers from four critical limitations: (L1) it utilizes multiple optimization terms per data point resulting to conflicting objectives, (L2) it fails to model all interactions across views and data points, (L3) it inherits fundamental limitations (e.g. alignment-uniformity coupling) from pairwise CL losses, and (L4) it prevents fully realizing the benefits of increased view multiplicity observed in supervised settings. We address these limitations through two novel loss functions: MV-InfoNCE, which extends InfoNCE to incorporate all possible view interactions simultaneously in one term per data point, and MV-DHEL, which decouples alignment from uniformity across views while scaling interaction complexity with view multiplicity. Both approaches are theoretically grounded - we prove they asymptotically optimize for alignment of all views and uniformity, providing principled extensions to multi-view contrastive learning. Our empirical results on ImageNet1K and three other datasets demonstrate that our methods consistently outperform existing multi-view approaches and effectively scale with increasing view multiplicity. We also apply our objectives to multimodal data and show that, in contrast to other contrastive objectives, they can scale beyond just two modalities. Most significantly, ablation studies reveal that MV-DHEL with five or more views effectively mitigates dimensionality collapse by fully utilizing the embedding space, thereby delivering multi-view benefits observed in supervised learning.
Scale Equivariant Graph Metanetworks
Jun 15, 2024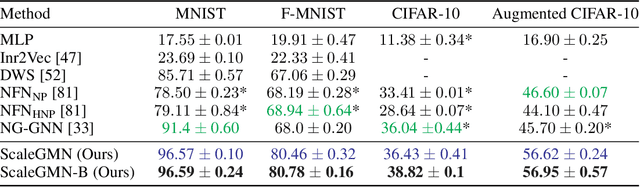
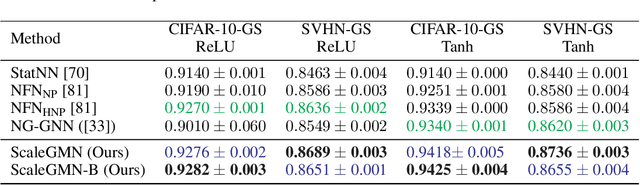
This paper pertains to an emerging machine learning paradigm: learning higher-order functions, i.e. functions whose inputs are functions themselves, $\textit{particularly when these inputs are Neural Networks (NNs)}$. With the growing interest in architectures that process NNs, a recurring design principle has permeated the field: adhering to the permutation symmetries arising from the connectionist structure of NNs. $\textit{However, are these the sole symmetries present in NN parameterizations}$? Zooming into most practical activation functions (e.g. sine, ReLU, tanh) answers this question negatively and gives rise to intriguing new symmetries, which we collectively refer to as $\textit{scaling symmetries}$, that is, non-zero scalar multiplications and divisions of weights and biases. In this work, we propose $\textit{Scale Equivariant Graph MetaNetworks - ScaleGMNs}$, a framework that adapts the Graph Metanetwork (message-passing) paradigm by incorporating scaling symmetries and thus rendering neuron and edge representations equivariant to valid scalings. We introduce novel building blocks, of independent technical interest, that allow for equivariance or invariance with respect to individual scalar multipliers or their product and use them in all components of ScaleGMN. Furthermore, we prove that, under certain expressivity conditions, ScaleGMN can simulate the forward and backward pass of any input feedforward neural network. Experimental results demonstrate that our method advances the state-of-the-art performance for several datasets and activation functions, highlighting the power of scaling symmetries as an inductive bias for NN processing.
Bridging Mini-Batch and Asymptotic Analysis in Contrastive Learning: From InfoNCE to Kernel-Based Losses
May 28, 2024



What do different contrastive learning (CL) losses actually optimize for? Although multiple CL methods have demonstrated remarkable representation learning capabilities, the differences in their inner workings remain largely opaque. In this work, we analyse several CL families and prove that, under certain conditions, they admit the same minimisers when optimizing either their batch-level objectives or their expectations asymptotically. In both cases, an intimate connection with the hyperspherical energy minimisation (HEM) problem resurfaces. Drawing inspiration from this, we introduce a novel CL objective, coined Decoupled Hyperspherical Energy Loss (DHEL). DHEL simplifies the problem by decoupling the target hyperspherical energy from the alignment of positive examples while preserving the same theoretical guarantees. Going one step further, we show the same results hold for another relevant CL family, namely kernel contrastive learning (KCL), with the additional advantage of the expected loss being independent of batch size, thus identifying the minimisers in the non-asymptotic regime. Empirical results demonstrate improved downstream performance and robustness across combinations of different batch sizes and hyperparameters and reduced dimensionality collapse, on several computer vision datasets.
Revisiting Point Cloud Simplification: A Learnable Feature Preserving Approach
Sep 30, 2021
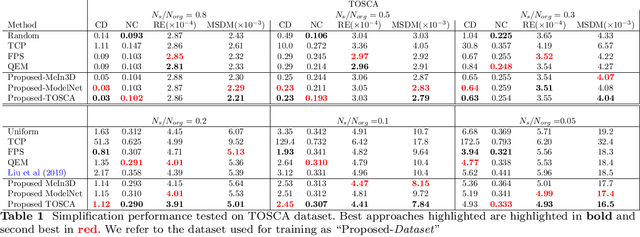

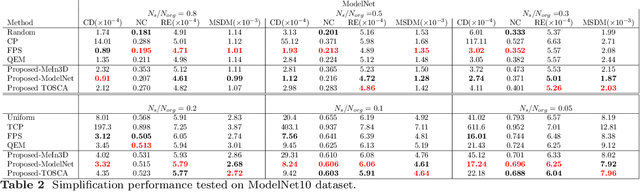
The recent advances in 3D sensing technology have made possible the capture of point clouds in significantly high resolution. However, increased detail usually comes at the expense of high storage, as well as computational costs in terms of processing and visualization operations. Mesh and Point Cloud simplification methods aim to reduce the complexity of 3D models while retaining visual quality and relevant salient features. Traditional simplification techniques usually rely on solving a time-consuming optimization problem, hence they are impractical for large-scale datasets. In an attempt to alleviate this computational burden, we propose a fast point cloud simplification method by learning to sample salient points. The proposed method relies on a graph neural network architecture trained to select an arbitrary, user-defined, number of points from the input space and to re-arrange their positions so as to minimize the visual perception error. The approach is extensively evaluated on various datasets using several perceptual metrics. Importantly, our method is able to generalize to out-of-distribution shapes, hence demonstrating zero-shot capabilities.
Partition and Code: learning how to compress graphs
Jul 05, 2021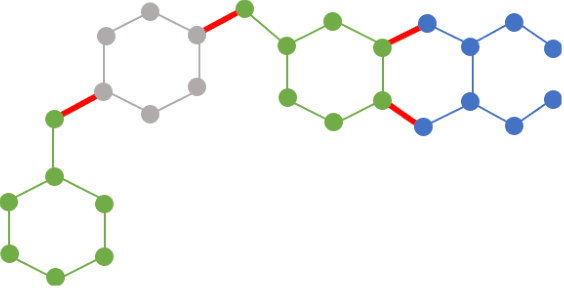
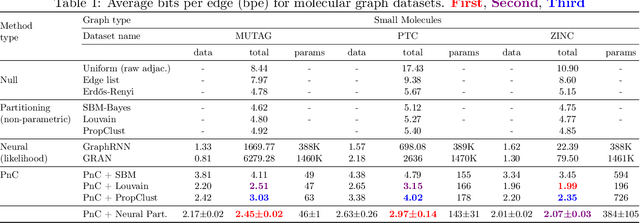
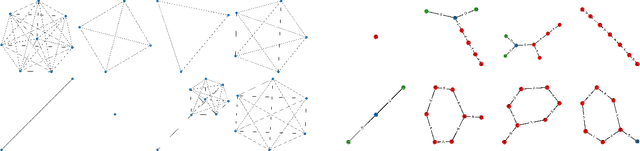
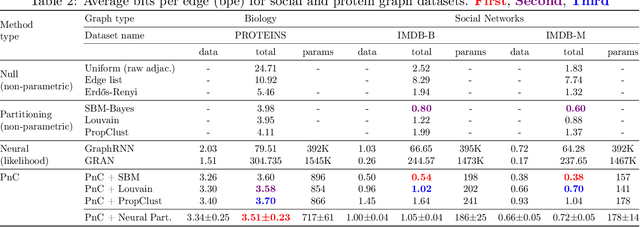
Can we use machine learning to compress graph data? The absence of ordering in graphs poses a significant challenge to conventional compression algorithms, limiting their attainable gains as well as their ability to discover relevant patterns. On the other hand, most graph compression approaches rely on domain-dependent handcrafted representations and cannot adapt to different underlying graph distributions. This work aims to establish the necessary principles a lossless graph compression method should follow to approach the entropy storage lower bound. Instead of making rigid assumptions about the graph distribution, we formulate the compressor as a probabilistic model that can be learned from data and generalise to unseen instances. Our "Partition and Code" framework entails three steps: first, a partitioning algorithm decomposes the graph into elementary structures, then these are mapped to the elements of a small dictionary on which we learn a probability distribution, and finally, an entropy encoder translates the representation into bits. All three steps are parametric and can be trained with gradient descent. We theoretically compare the compression quality of several graph encodings and prove, under mild conditions, a total ordering of their expected description lengths. Moreover, we show that, under the same conditions, PnC achieves compression gains w.r.t. the baselines that grow either linearly or quadratically with the number of vertices. Our algorithms are quantitatively evaluated on diverse real-world networks obtaining significant performance improvements with respect to different families of non-parametric and parametric graph compressors.
3D Facial Matching by Spiral Convolutional Metric Learning and a Biometric Fusion-Net of Demographic Properties
Sep 10, 2020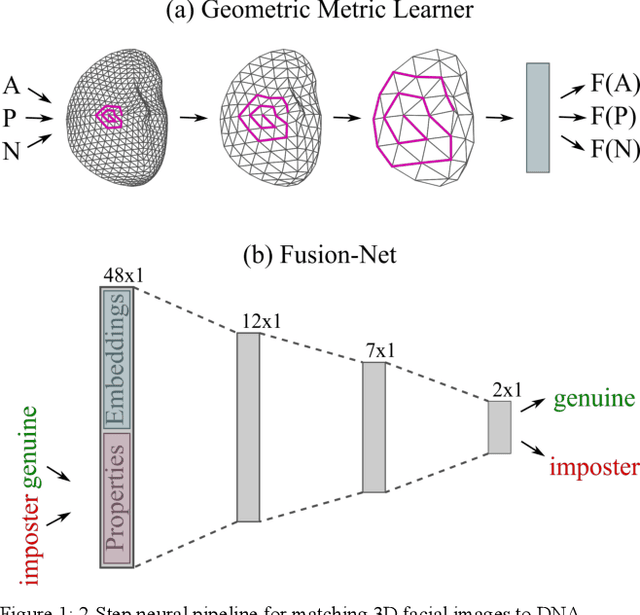
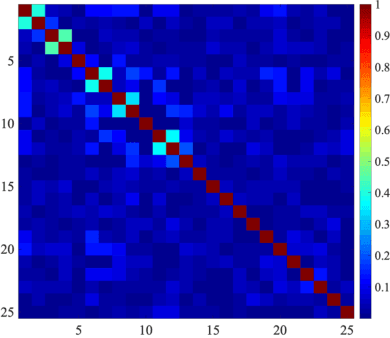

Face recognition is a widely accepted biometric verification tool, as the face contains a lot of information about the identity of a person. In this study, a 2-step neural-based pipeline is presented for matching 3D facial shape to multiple DNA-related properties (sex, age, BMI and genomic background). The first step consists of a triplet loss-based metric learner that compresses facial shape into a lower dimensional embedding while preserving information about the property of interest. Most studies in the field of metric learning have only focused on Euclidean data. In this work, geometric deep learning is employed to learn directly from 3D facial meshes. To this end, spiral convolutions are used along with a novel mesh-sampling scheme that retains uniformly sampled 3D points at different levels of resolution. The second step is a multi-biometric fusion by a fully connected neural network. The network takes an ensemble of embeddings and property labels as input and returns genuine and imposter scores. Since embeddings are accepted as an input, there is no need to train classifiers for the different properties and available data can be used more efficiently. Results obtained by a 10-fold cross-validation for biometric verification show that combining multiple properties leads to stronger biometric systems. Furthermore, the proposed neural-based pipeline outperforms a linear baseline, which consists of principal component analysis, followed by classification with linear support vector machines and a Naive Bayes-based score-fuser.
Learning to Generate Customized Dynamic 3D Facial Expressions
Jul 21, 2020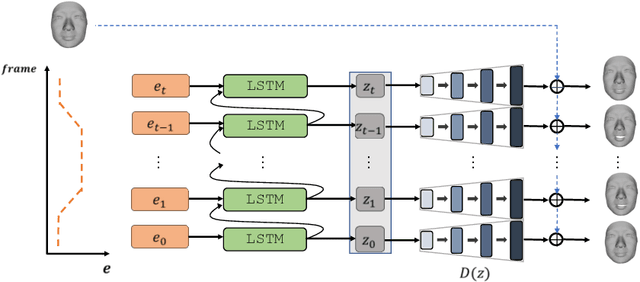
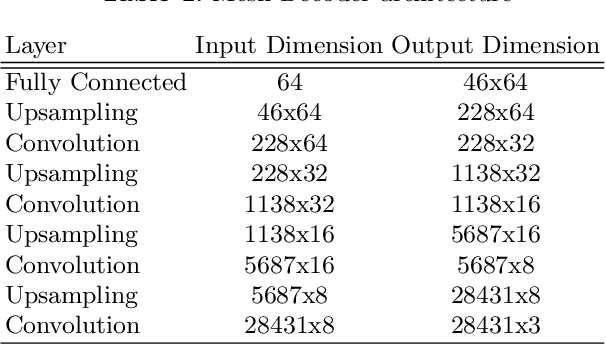
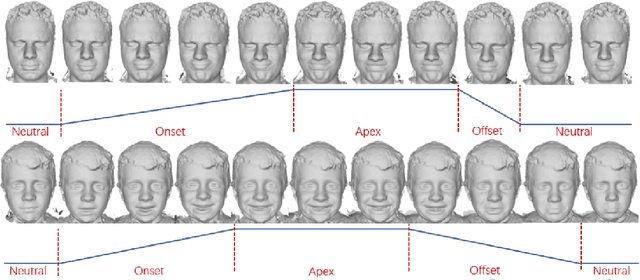

Recent advances in deep learning have significantly pushed the state-of-the-art in photorealistic video animation given a single image. In this paper, we extrapolate those advances to the 3D domain, by studying 3D image-to-video translation with a particular focus on 4D facial expressions. Although 3D facial generative models have been widely explored during the past years, 4D animation remains relatively unexplored. To this end, in this study we employ a deep mesh encoder-decoder like architecture to synthesize realistic high resolution facial expressions by using a single neutral frame along with an expression identification. In addition, processing 3D meshes remains a non-trivial task compared to data that live on grid-like structures, such as images. Given the recent progress in mesh processing with graph convolutions, we make use of a recently introduced learnable operator which acts directly on the mesh structure by taking advantage of local vertex orderings. In order to generalize to 4D facial expressions across subjects, we trained our model using a high resolution dataset with 4D scans of six facial expressions from 180 subjects. Experimental results demonstrate that our approach preserves the subject's identity information even for unseen subjects and generates high quality expressions. To the best of our knowledge, this is the first study tackling the problem of 4D facial expression synthesis.
Deep Polynomial Neural Networks
Jun 20, 2020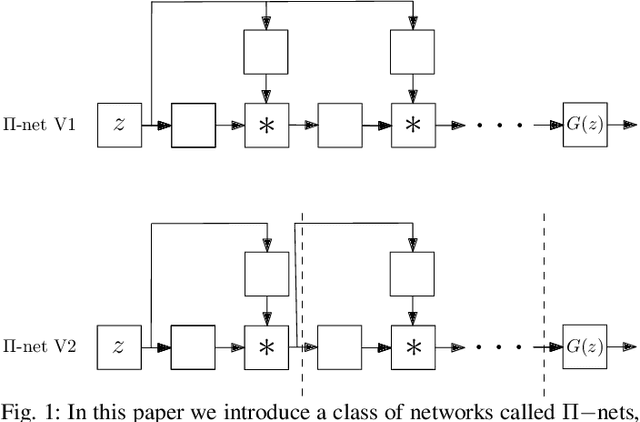

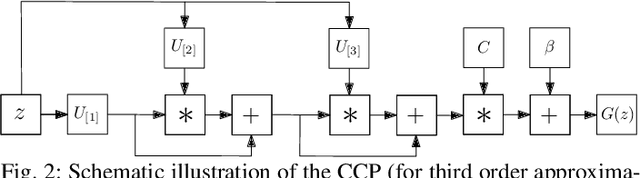
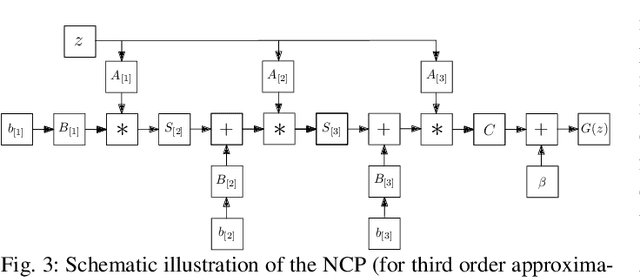
Deep Convolutional Neural Networks (DCNNs) are currently the method of choice both for generative, as well as for discriminative learning in computer vision and machine learning. The success of DCNNs can be attributed to the careful selection of their building blocks (e.g., residual blocks, rectifiers, sophisticated normalization schemes, to mention but a few). In this paper, we propose $\Pi$-Nets, a new class of DCNNs. $\Pi$-Nets are polynomial neural networks, i.e., the output is a high-order polynomial of the input. The unknown parameters, which are naturally represented by high-order tensors, are estimated through a collective tensor factorization with factors sharing. We introduce three tensor decompositions that significantly reduce the number of parameters and show how they can be efficiently implemented by hierarchical neural networks. We empirically demonstrate that $\Pi$-Nets are very expressive and they even produce good results without the use of non-linear activation functions in a large battery of tasks and signals, i.e., images, graphs, and audio. When used in conjunction with activation functions, $\Pi$-Nets produce state-of-the-art results in three challenging tasks, i.e. image generation, face verification and 3D mesh representation learning.