 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartition and Code: learning how to compress graphs
Paper and Code
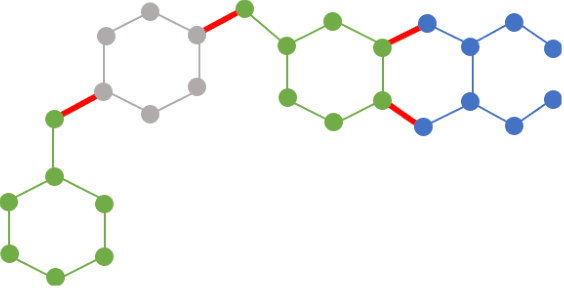
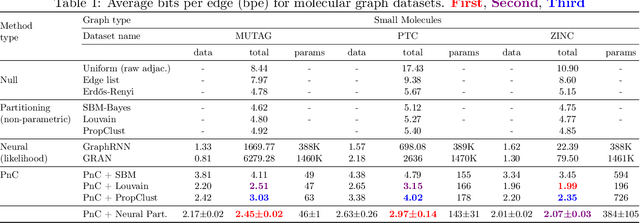
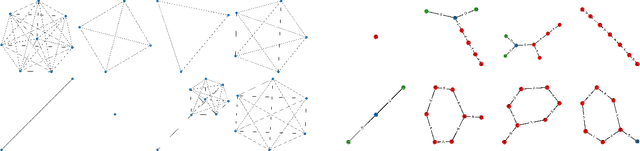
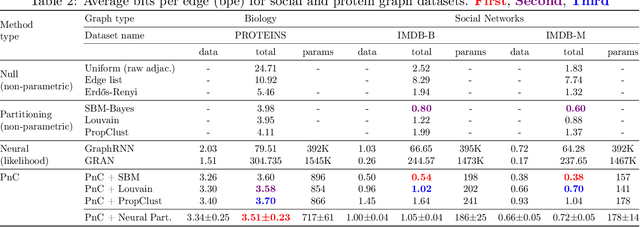
Can we use machine learning to compress graph data? The absence of ordering in graphs poses a significant challenge to conventional compression algorithms, limiting their attainable gains as well as their ability to discover relevant patterns. On the other hand, most graph compression approaches rely on domain-dependent handcrafted representations and cannot adapt to different underlying graph distributions. This work aims to establish the necessary principles a lossless graph compression method should follow to approach the entropy storage lower bound. Instead of making rigid assumptions about the graph distribution, we formulate the compressor as a probabilistic model that can be learned from data and generalise to unseen instances. Our "Partition and Code" framework entails three steps: first, a partitioning algorithm decomposes the graph into elementary structures, then these are mapped to the elements of a small dictionary on which we learn a probability distribution, and finally, an entropy encoder translates the representation into bits. All three steps are parametric and can be trained with gradient descent. We theoretically compare the compression quality of several graph encodings and prove, under mild conditions, a total ordering of their expected description lengths. Moreover, we show that, under the same conditions, PnC achieves compression gains w.r.t. the baselines that grow either linearly or quadratically with the number of vertices. Our algorithms are quantitatively evaluated on diverse real-world networks obtaining significant performance improvements with respect to different families of non-parametric and parametric graph compressors.