 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolySAE: Modeling Feature Interactions in Sparse Autoencoders via Polynomial Decoding
Feb 01, 2026Sparse autoencoders (SAEs) have emerged as a promising method for interpreting neural network representations by decomposing activations into sparse combinations of dictionary atoms. However, SAEs assume that features combine additively through linear reconstruction, an assumption that cannot capture compositional structure: linear models cannot distinguish whether "Starbucks" arises from the composition of "star" and "coffee" features or merely their co-occurrence. This forces SAEs to allocate monolithic features for compound concepts rather than decomposing them into interpretable constituents. We introduce PolySAE, which extends the SAE decoder with higher-order terms to model feature interactions while preserving the linear encoder essential for interpretability. Through low-rank tensor factorization on a shared projection subspace, PolySAE captures pairwise and triple feature interactions with small parameter overhead (3% on GPT2). Across four language models and three SAE variants, PolySAE achieves an average improvement of approximately 8% in probing F1 while maintaining comparable reconstruction error, and produces 2-10$\times$ larger Wasserstein distances between class-conditional feature distributions. Critically, learned interaction weights exhibit negligible correlation with co-occurrence frequency ($r = 0.06$ vs. $r = 0.82$ for SAE feature covariance), suggesting that polynomial terms capture compositional structure, such as morphological binding and phrasal composition, largely independent of surface statistics.
Bridging Mini-Batch and Asymptotic Analysis in Contrastive Learning: From InfoNCE to Kernel-Based Losses
May 28, 2024



What do different contrastive learning (CL) losses actually optimize for? Although multiple CL methods have demonstrated remarkable representation learning capabilities, the differences in their inner workings remain largely opaque. In this work, we analyse several CL families and prove that, under certain conditions, they admit the same minimisers when optimizing either their batch-level objectives or their expectations asymptotically. In both cases, an intimate connection with the hyperspherical energy minimisation (HEM) problem resurfaces. Drawing inspiration from this, we introduce a novel CL objective, coined Decoupled Hyperspherical Energy Loss (DHEL). DHEL simplifies the problem by decoupling the target hyperspherical energy from the alignment of positive examples while preserving the same theoretical guarantees. Going one step further, we show the same results hold for another relevant CL family, namely kernel contrastive learning (KCL), with the additional advantage of the expected loss being independent of batch size, thus identifying the minimisers in the non-asymptotic regime. Empirical results demonstrate improved downstream performance and robustness across combinations of different batch sizes and hyperparameters and reduced dimensionality collapse, on several computer vision datasets.
3DFaceGAN: Adversarial Nets for 3D Face Representation, Generation, and Translation
May 09, 2019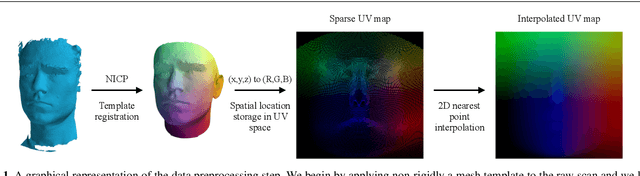


Over the past few years, Generative Adversarial Networks (GANs) have garnered increased interest among researchers in Computer Vision, with applications including, but not limited to, image generation, translation, imputation, and super-resolution. Nevertheless, no GAN-based method has been proposed in the literature that can successfully represent, generate or translate 3D facial shapes (meshes). This can be primarily attributed to two facts, namely that (a) publicly available 3D face databases are scarce as well as limited in terms of sample size and variability (e.g., few subjects, little diversity in race and gender), and (b) mesh convolutions for deep networks present several challenges that are not entirely tackled in the literature, leading to operator approximations and model instability, often failing to preserve high-frequency components of the distribution. As a result, linear methods such as Principal Component Analysis (PCA) have been mainly utilized towards 3D shape analysis, despite being unable to capture non-linearities and high frequency details of the 3D face - such as eyelid and lip variations. In this work, we present 3DFaceGAN, the first GAN tailored towards modeling the distribution of 3D facial surfaces, while retaining the high frequency details of 3D face shapes. We conduct an extensive series of both qualitative and quantitative experiments, where the merits of 3DFaceGAN are clearly demonstrated against other, state-of-the-art methods in tasks such as 3D shape representation, generation, and translation.
Multi-Attribute Robust Component Analysis for Facial UV Maps
Dec 15, 2017



Recently, due to the collection of large scale 3D face models, as well as the advent of deep learning, a significant progress has been made in the field of 3D face alignment "in-the-wild". That is, many methods have been proposed that establish sparse or dense 3D correspondences between a 2D facial image and a 3D face model. The utilization of 3D face alignment introduces new challenges and research directions, especially on the analysis of facial texture images. In particular, texture does not suffer any more from warping effects (that occurred when 2D face alignment methods were used). Nevertheless, since facial images are commonly captured in arbitrary recording conditions, a considerable amount of missing information and gross outliers is observed (e.g., due to self-occlusion, or subjects wearing eye-glasses). Given that many annotated databases have been developed for face analysis tasks, it is evident that component analysis techniques need to be developed in order to alleviate issues arising from the aforementioned challenges. In this paper, we propose a novel component analysis technique that is suitable for facial UV maps containing a considerable amount of missing information and outliers, while additionally, incorporates knowledge from various attributes (such as age and identity). We evaluate the proposed Multi-Attribute Robust Component Analysis (MA-RCA) on problems such as UV completion and age progression, where the proposed method outperforms compared techniques. Finally, we demonstrate that MA-RCA method is powerful enough to provide weak annotations for training deep learning systems for various applications, such as illumination transfer.