 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Space Disentanglement via Activation Steering for Interpretable Attribute Control in Symbolic Music Generation
May 29, 2026Transformer-based architectures have significantly advanced the generation of complex symbolic sequences, yet a significant gap remains in achieving fine-grained, interpretable control over discrete signal attributes. This paper investigates the mechanistic interpretability of the Multitrack Music Transformer (MMT) and proposes a framework for deterministic attribute modulation without retraining to bridge this gap via inference-time activation steering. Utilizing the Difference-in-Means (DiffMean) methodology, we isolate latent directions for signal attributes, specifically Pitch and Duration, within the residual stream. We validate the Linear Representation Hypothesis in this domain, achieving high correlation between steering magnitude and attribute shift. To address the inherent feature entanglement in multi-attribute steering, we introduce a Dual Steering framework utilizing Gram-Schmidt Orthogonalization. Experimental results demonstrate that this geometric decoupling reduces conceptual interference and signal degradation compared to naive vector addition, enabling independent deterministic control even against strong autoregressive conditioning.
Neural Collapse by Design: Learning Class Prototypes on the Hypersphere
May 21, 2026Supervised classification has a theoretical optimum, Neural Collapse (NC), yet neither of its two dominant paradigms reaches it in practice. Cross entropy (CE) leaves radial degrees of freedom unconstrained and converges to a degenerate geometry, while supervised contrastive learning (SCL) drives features toward NC during pretraining but discards this structure in a post hoc linear probing phase. We show that both paradigms are different appearances of the same method that contrasts prototypes on the unit hypersphere, and that closing the gap requires fixing each at its point of failure. From the CE side, we propose NTCE and NONL, two normalized losses that import contrastive optimization's missing ingredients into classifier learning: a large effective negative set and decoupled alignment and uniformity terms. From the SCL side, we prove that SCL's objective already optimizes throughout training for a principled classifier whose weights are the class mean embeddings, making linear probing both redundant and harmful. Empirically, on four benchmarks including ImageNet-1K, NTCE and NONL surpass CE accuracy, closely approximate NC ($\geq 95\%$), and match CE's converged NC on 4/5 metrics in under $7.5\%$ of its iterations, while SCL with fixed prototypes matches linear probing without the hours-long classifier training phase. The learned geometry yields $+5.5\%$ mean relative improvement in transfer learning, up to $+8.7\%$ under severe class imbalance, and improved robustness to corruptions on ImageNet-C. Our work recasts supervised learning as prototype learning on the hypersphere, with NC reached by design.
REGLUE Your Latents with Global and Local Semantics for Entangled Diffusion
Dec 18, 2025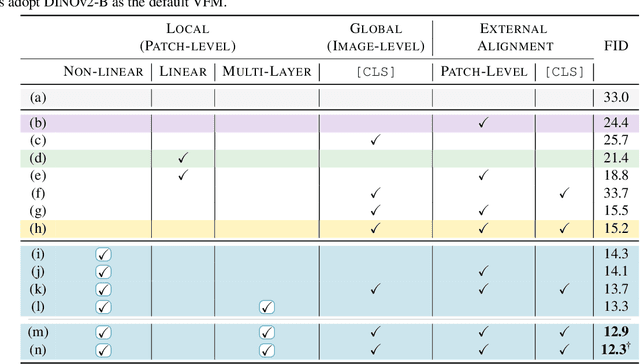

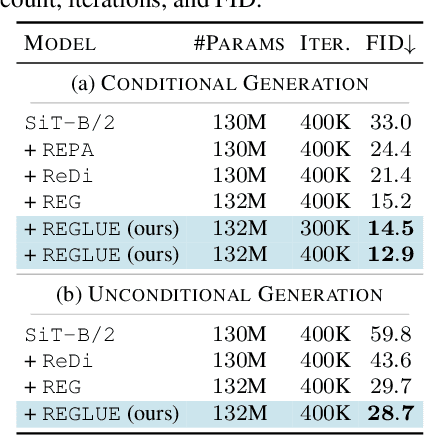
Latent diffusion models (LDMs) achieve state-of-the-art image synthesis, yet their reconstruction-style denoising objective provides only indirect semantic supervision: high-level semantics emerge slowly, requiring longer training and limiting sample quality. Recent works inject semantics from Vision Foundation Models (VFMs) either externally via representation alignment or internally by jointly modeling only a narrow slice of VFM features inside the diffusion process, under-utilizing the rich, nonlinear, multi-layer spatial semantics available. We introduce REGLUE (Representation Entanglement with Global-Local Unified Encoding), a unified latent diffusion framework that jointly models (i) VAE image latents, (ii) compact local (patch-level) VFM semantics, and (iii) a global (image-level) [CLS] token within a single SiT backbone. A lightweight convolutional semantic compressor nonlinearly aggregates multi-layer VFM features into a low-dimensional, spatially structured representation, which is entangled with the VAE latents in the diffusion process. An external alignment loss further regularizes internal representations toward frozen VFM targets. On ImageNet 256x256, REGLUE consistently improves FID and accelerates convergence over SiT-B/2 and SiT-XL/2 baselines, as well as over REPA, ReDi, and REG. Extensive experiments show that (a) spatial VFM semantics are crucial, (b) non-linear compression is key to unlocking their full benefit, and (c) global tokens and external alignment act as complementary, lightweight enhancements within our global-local-latent joint modeling framework. The code is available at https://github.com/giorgospets/reglue .
A Principled Framework for Multi-View Contrastive Learning
Jul 09, 2025Contrastive Learning (CL), a leading paradigm in Self-Supervised Learning (SSL), typically relies on pairs of data views generated through augmentation. While multiple augmentations per instance (more than two) improve generalization in supervised learning, current CL methods handle additional views suboptimally by simply aggregating different pairwise objectives. This approach suffers from four critical limitations: (L1) it utilizes multiple optimization terms per data point resulting to conflicting objectives, (L2) it fails to model all interactions across views and data points, (L3) it inherits fundamental limitations (e.g. alignment-uniformity coupling) from pairwise CL losses, and (L4) it prevents fully realizing the benefits of increased view multiplicity observed in supervised settings. We address these limitations through two novel loss functions: MV-InfoNCE, which extends InfoNCE to incorporate all possible view interactions simultaneously in one term per data point, and MV-DHEL, which decouples alignment from uniformity across views while scaling interaction complexity with view multiplicity. Both approaches are theoretically grounded - we prove they asymptotically optimize for alignment of all views and uniformity, providing principled extensions to multi-view contrastive learning. Our empirical results on ImageNet1K and three other datasets demonstrate that our methods consistently outperform existing multi-view approaches and effectively scale with increasing view multiplicity. We also apply our objectives to multimodal data and show that, in contrast to other contrastive objectives, they can scale beyond just two modalities. Most significantly, ablation studies reveal that MV-DHEL with five or more views effectively mitigates dimensionality collapse by fully utilizing the embedding space, thereby delivering multi-view benefits observed in supervised learning.
Contrastive and Transfer Learning for Effective Audio Fingerprinting through a Real-World Evaluation Protocol
Jul 08, 2025Recent advances in song identification leverage deep neural networks to learn compact audio fingerprints directly from raw waveforms. While these methods perform well under controlled conditions, their accuracy drops significantly in real-world scenarios where the audio is captured via mobile devices in noisy environments. In this paper, we introduce a novel evaluation protocol designed to better reflect such real-world conditions. We generate three recordings of the same audio, each with increasing levels of noise, captured using a mobile device's microphone. Our results reveal a substantial performance drop for two state-of-the-art CNN-based models under this protocol, compared to previously reported benchmarks. Additionally, we highlight the critical role of the augmentation pipeline during training with contrastive loss. By introduction low pass and high pass filters in the augmentation pipeline we significantly increase the performance of both systems in our proposed evaluation. Furthermore, we develop a transformer-based model with a tailored projection module and demonstrate that transferring knowledge from a semantically relevant domain yields a more robust solution. The transformer architecture outperforms CNN-based models across all noise levels, and query durations. In low noise conditions it achieves 47.99% for 1-sec queries, and 97% for 10-sec queries in finding the correct song, surpassing by 14%, and by 18.5% the second-best performing model, respectively, Under heavy noise levels, we achieve a detection rate 56.5% for 15-second query duration. All experiments are conducted on public large-scale dataset of over 100K songs, with queries matched against a database of 56 million vectors.
* International Journal of Music Science, Technology and Art, 15 pages, 7 figures
Greek2MathTex: A Greek Speech-to-Text Framework for LaTeX Equations Generation
Dec 11, 2024In the vast majority of the academic and scientific domains, LaTeX has established itself as the de facto standard for typesetting complex mathematical equations and formulae. However, LaTeX's complex syntax and code-like appearance present accessibility barriers for individuals with disabilities, as well as those unfamiliar with coding conventions. In this paper, we present a novel solution to this challenge through the development of a novel speech-to-LaTeX equations system specifically designed for the Greek language. We propose an end-to-end system that harnesses the power of Automatic Speech Recognition (ASR) and Natural Language Processing (NLP) techniques to enable users to verbally dictate mathematical expressions and equations in natural language, which are subsequently converted into LaTeX format. We present the architecture and design principles of our system, highlighting key components such as the ASR engine, the LLM-based prompt-driven equations generation mechanism, as well as the application of a custom evaluation metric employed throughout the development process. We have made our system open source and available at https://github.com/magcil/greek-speech-to-math.
Bridging Mini-Batch and Asymptotic Analysis in Contrastive Learning: From InfoNCE to Kernel-Based Losses
May 28, 2024



What do different contrastive learning (CL) losses actually optimize for? Although multiple CL methods have demonstrated remarkable representation learning capabilities, the differences in their inner workings remain largely opaque. In this work, we analyse several CL families and prove that, under certain conditions, they admit the same minimisers when optimizing either their batch-level objectives or their expectations asymptotically. In both cases, an intimate connection with the hyperspherical energy minimisation (HEM) problem resurfaces. Drawing inspiration from this, we introduce a novel CL objective, coined Decoupled Hyperspherical Energy Loss (DHEL). DHEL simplifies the problem by decoupling the target hyperspherical energy from the alignment of positive examples while preserving the same theoretical guarantees. Going one step further, we show the same results hold for another relevant CL family, namely kernel contrastive learning (KCL), with the additional advantage of the expected loss being independent of batch size, thus identifying the minimisers in the non-asymptotic regime. Empirical results demonstrate improved downstream performance and robustness across combinations of different batch sizes and hyperparameters and reduced dimensionality collapse, on several computer vision datasets.
Designing and Evaluating Speech Emotion Recognition Systems: A reality check case study with IEMOCAP
Apr 03, 2023


There is an imminent need for guidelines and standard test sets to allow direct and fair comparisons of speech emotion recognition (SER). While resources, such as the Interactive Emotional Dyadic Motion Capture (IEMOCAP) database, have emerged as widely-adopted reference corpora for researchers to develop and test models for SER, published work reveals a wide range of assumptions and variety in its use that challenge reproducibility and generalization. Based on a critical review of the latest advances in SER using IEMOCAP as the use case, our work aims at two contributions: First, using an analysis of the recent literature, including assumptions made and metrics used therein, we provide a set of SER evaluation guidelines. Second, using recent publications with open-sourced implementations, we focus on reproducibility assessment in SER.
A Dataset for Greek Traditional and Folk Music: Lyra
Nov 21, 2022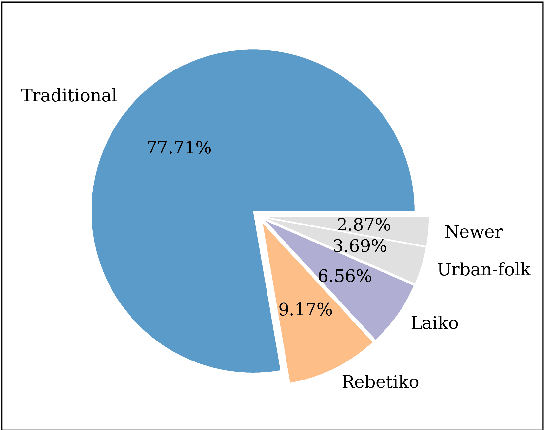
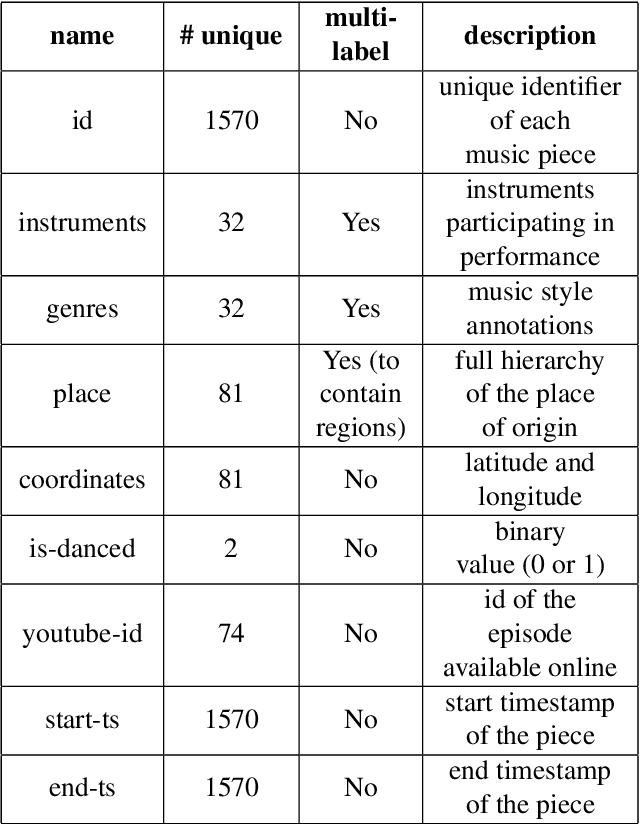
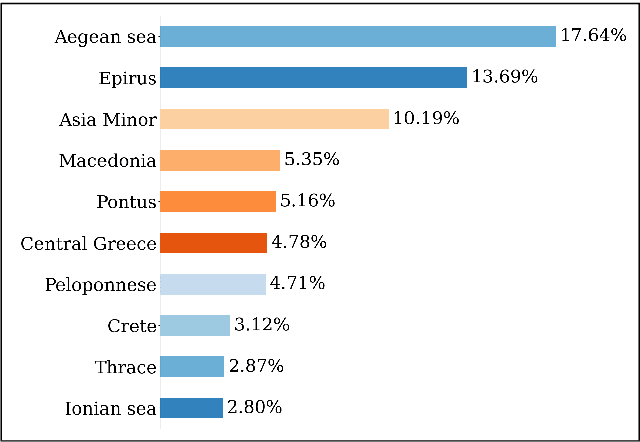
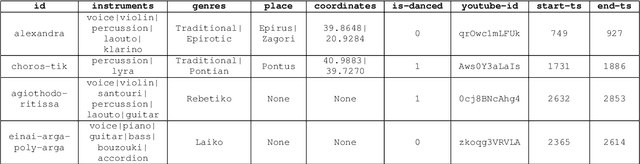
Studying under-represented music traditions under the MIR scope is crucial, not only for developing novel analysis tools, but also for unveiling musical functions that might prove useful in studying world musics. This paper presents a dataset for Greek Traditional and Folk music that includes 1570 pieces, summing in around 80 hours of data. The dataset incorporates YouTube timestamped links for retrieving audio and video, along with rich metadata information with regards to instrumentation, geography and genre, among others. The content has been collected from a Greek documentary series that is available online, where academics present music traditions of Greece with live music and dance performance during the show, along with discussions about social, cultural and musicological aspects of the presented music. Therefore, this procedure has resulted in a significant wealth of descriptions regarding a variety of aspects, such as musical genre, places of origin and musical instruments. In addition, the audio recordings were performed under strict production-level specifications, in terms of recording equipment, leading to very clean and homogeneous audio content. In this work, apart from presenting the dataset in detail, we propose a baseline deep-learning classification approach to recognize the involved musicological attributes. The dataset, the baseline classification methods and the models are provided in public repositories. Future directions for further refining the dataset are also discussed.
A Dataset for Speech Emotion Recognition in Greek Theatrical Plays
Mar 27, 2022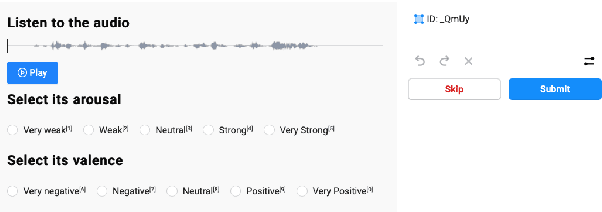
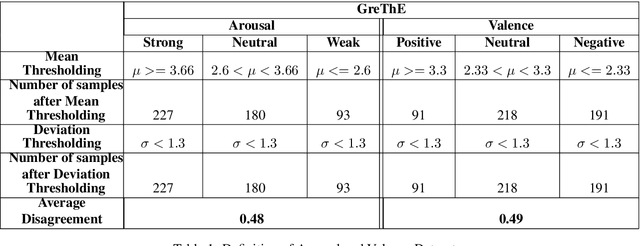
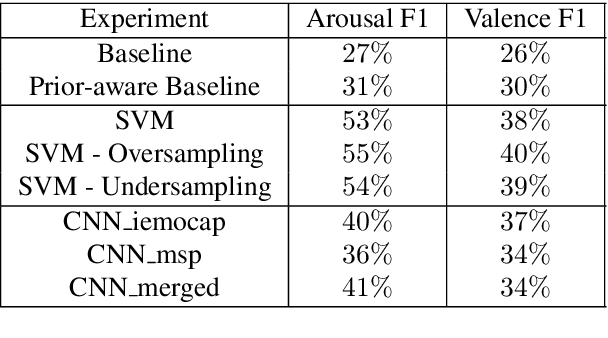
Machine learning methodologies can be adopted in cultural applications and propose new ways to distribute or even present the cultural content to the public. For instance, speech analytics can be adopted to automatically generate subtitles in theatrical plays, in order to (among other purposes) help people with hearing loss. Apart from a typical speech-to-text transcription with Automatic Speech Recognition (ASR), Speech Emotion Recognition (SER) can be used to automatically predict the underlying emotional content of speech dialogues in theatrical plays, and thus to provide a deeper understanding how the actors utter their lines. However, real-world datasets from theatrical plays are not available in the literature. In this work we present GreThE, the Greek Theatrical Emotion dataset, a new publicly available data collection for speech emotion recognition in Greek theatrical plays. The dataset contains utterances from various actors and plays, along with respective valence and arousal annotations. Towards this end, multiple annotators have been asked to provide their input for each speech recording and inter-annotator agreement is taken into account in the final ground truth generation. In addition, we discuss the results of some indicative experiments that have been conducted with machine and deep learning frameworks, using the dataset, along with some widely used databases in the field of speech emotion recognition.