 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Diffusion Language Models with Frequency-Informed Training
Sep 05, 2025We present a masked diffusion language modeling framework for data-efficient training for the BabyLM 2025 Challenge. Our approach applies diffusion training objectives to language modeling under strict data constraints, incorporating frequency-informed masking that prioritizes learning from rare tokens while maintaining theoretical validity. We explore multiple noise scheduling strategies, including two-mode approaches, and investigate different noise weighting schemes within the NELBO objective. We evaluate our method on the BabyLM benchmark suite, measuring linguistic competence, world knowledge, and human-likeness. Results show performance competitive to hybrid autoregressive-masked baselines, demonstrating that diffusion-based training offers a viable alternative for data-restricted language learning.
Auto-Compressing Networks
Jun 11, 2025Deep neural networks with short residual connections have demonstrated remarkable success across domains, but increasing depth often introduces computational redundancy without corresponding improvements in representation quality. In this work, we introduce Auto-Compressing Networks (ACNs), an architectural variant where additive long feedforward connections from each layer to the output replace traditional short residual connections. ACNs showcase a unique property we coin as "auto-compression", the ability of a network to organically compress information during training with gradient descent, through architectural design alone. Through auto-compression, information is dynamically "pushed" into early layers during training, enhancing their representational quality and revealing potential redundancy in deeper ones. We theoretically show that this property emerges from layer-wise training patterns present in ACNs, where layers are dynamically utilized during training based on task requirements. We also find that ACNs exhibit enhanced noise robustness compared to residual networks, superior performance in low-data settings, improved transfer learning capabilities, and mitigate catastrophic forgetting suggesting that they learn representations that generalize better despite using fewer parameters. Our results demonstrate up to 18% reduction in catastrophic forgetting and 30-80% architectural compression while maintaining accuracy across vision transformers, MLP-mixers, and BERT architectures. Furthermore, we demonstrate that coupling ACNs with traditional pruning techniques, enables significantly better sparsity-performance trade-offs compared to conventional architectures. These findings establish ACNs as a practical approach to developing efficient neural architectures that automatically adapt their computational footprint to task complexity, while learning robust representations.
MEDUSA: A Multimodal Deep Fusion Multi-Stage Training Framework for Speech Emotion Recognition in Naturalistic Conditions
Jun 11, 2025SER is a challenging task due to the subjective nature of human emotions and their uneven representation under naturalistic conditions. We propose MEDUSA, a multimodal framework with a four-stage training pipeline, which effectively handles class imbalance and emotion ambiguity. The first two stages train an ensemble of classifiers that utilize DeepSER, a novel extension of a deep cross-modal transformer fusion mechanism from pretrained self-supervised acoustic and linguistic representations. Manifold MixUp is employed for further regularization. The last two stages optimize a trainable meta-classifier that combines the ensemble predictions. Our training approach incorporates human annotation scores as soft targets, coupled with balanced data sampling and multitask learning. MEDUSA ranked 1st in Task 1: Categorical Emotion Recognition in the Interspeech 2025: Speech Emotion Recognition in Naturalistic Conditions Challenge.
MSDA: Combining Pseudo-labeling and Self-Supervision for Unsupervised Domain Adaptation in ASR
May 30, 2025In this work, we investigate the Meta PL unsupervised domain adaptation framework for Automatic Speech Recognition (ASR). We introduce a Multi-Stage Domain Adaptation pipeline (MSDA), a sample-efficient, two-stage adaptation approach that integrates self-supervised learning with semi-supervised techniques. MSDA is designed to enhance the robustness and generalization of ASR models, making them more adaptable to diverse conditions. It is particularly effective for low-resource languages like Greek and in weakly supervised scenarios where labeled data is scarce or noisy. Through extensive experiments, we demonstrate that Meta PL can be applied effectively to ASR tasks, achieving state-of-the-art results, significantly outperforming state-of-the-art methods, and providing more robust solutions for unsupervised domain adaptation in ASR. Our ablations highlight the necessity of utilizing a cascading approach when combining self-supervision with self-training.
DeepMLF: Multimodal language model with learnable tokens for deep fusion in sentiment analysis
Apr 15, 2025While multimodal fusion has been extensively studied in Multimodal Sentiment Analysis (MSA), the role of fusion depth and multimodal capacity allocation remains underexplored. In this work, we position fusion depth, scalability, and dedicated multimodal capacity as primary factors for effective fusion. We introduce DeepMLF, a novel multimodal language model (LM) with learnable tokens tailored toward deep fusion. DeepMLF leverages an audiovisual encoder and a pretrained decoder LM augmented with multimodal information across its layers. We append learnable tokens to the LM that: 1) capture modality interactions in a controlled fashion and 2) preserve independent information flow for each modality. These fusion tokens gather linguistic information via causal self-attention in LM Blocks and integrate with audiovisual information through cross-attention MM Blocks. Serving as dedicated multimodal capacity, this design enables progressive fusion across multiple layers, providing depth in the fusion process. Our training recipe combines modality-specific losses and language modelling loss, with the decoder LM tasked to predict ground truth polarity. Across three MSA benchmarks with varying dataset characteristics, DeepMLF achieves state-of-the-art performance. Our results confirm that deeper fusion leads to better performance, with optimal fusion depths (5-7) exceeding those of existing approaches. Additionally, our analysis on the number of fusion tokens reveals that small token sets ($\sim$20) achieve optimal performance. We examine the importance of representation learning order (fusion curriculum) through audiovisual encoder initialization experiments. Our ablation studies demonstrate the superiority of the proposed fusion design and gating while providing a holistic examination of DeepMLF's scalability to LLMs, and the impact of each training objective and embedding regularization.
Aggregation Artifacts in Subjective Tasks Collapse Large Language Models' Posteriors
Oct 17, 2024



In-context Learning (ICL) has become the primary method for performing natural language tasks with Large Language Models (LLMs). The knowledge acquired during pre-training is crucial for this few-shot capability, providing the model with task priors. However, recent studies have shown that ICL predominantly relies on retrieving task priors rather than "learning" to perform tasks. This limitation is particularly evident in complex subjective domains such as emotion and morality, where priors significantly influence posterior predictions. In this work, we examine whether this is the result of the aggregation used in corresponding datasets, where trying to combine low-agreement, disparate annotations might lead to annotation artifacts that create detrimental noise in the prompt. Moreover, we evaluate the posterior bias towards certain annotators by grounding our study in appropriate, quantitative measures of LLM priors. Our results indicate that aggregation is a confounding factor in the modeling of subjective tasks, and advocate focusing on modeling individuals instead. However, aggregation does not explain the entire gap between ICL and the state of the art, meaning other factors in such tasks also account for the observed phenomena. Finally, by rigorously studying annotator-level labels, we find that it is possible for minority annotators to both better align with LLMs and have their perspectives further amplified.
BloomWise: Enhancing Problem-Solving capabilities of Large Language Models using Bloom's-Taxonomy-Inspired Prompts
Oct 05, 2024


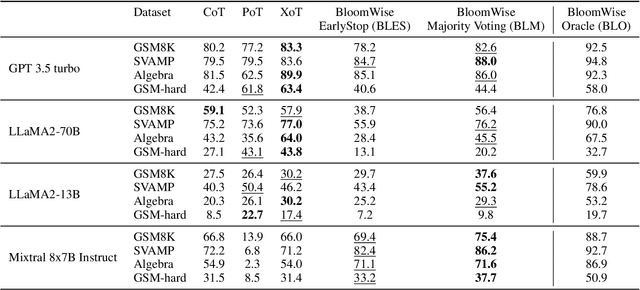
Despite the continuous progress of Large Language Models (LLMs) across various tasks, their performance on mathematical problems and reasoning tasks remains limited. This limitation can be attributed, among other factors, to the inherent difficulty of these problems and the fact that solutions often consist of multiple steps, potentially of varying nature, making it challenging for a single prompting technique to execute all required steps. To address this, we introduce BloomWise, a new prompting technique, inspired by Bloom's Taxonomy, aiming to improve LLMs' performance in solving such problems by encouraging them to approach the problem starting from simple, i.e., remembering, and progressing to higher cognitive skills, i.e., analyzing, until the correct solution is reached. The decision regarding the need to employ more sophisticated cognitive skills is based on self-evaluation performed by the LLM. Thus, we encourage the LLM to deploy the appropriate cognitive processes. In extensive experiments across 4 popular math reasoning datasets, we have demonstrated the effectiveness of our proposed approach. We also present extensive ablations, analyzing the strengths of each module within our system.
LC-Protonets: Multi-label Few-shot learning for world music audio tagging
Sep 17, 2024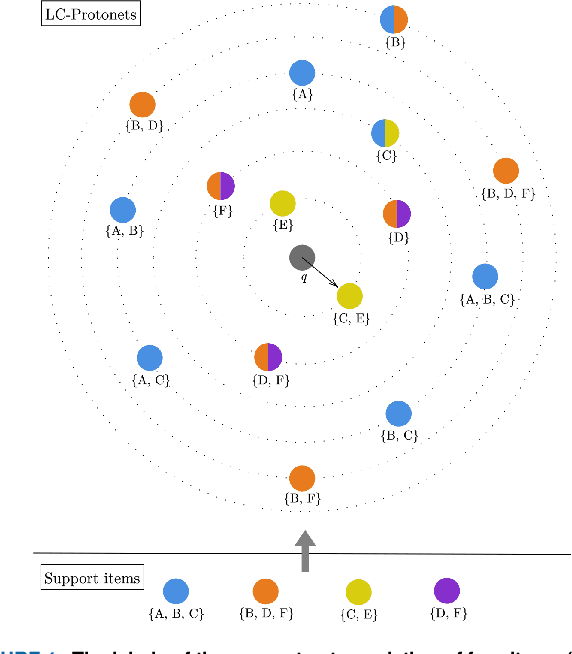
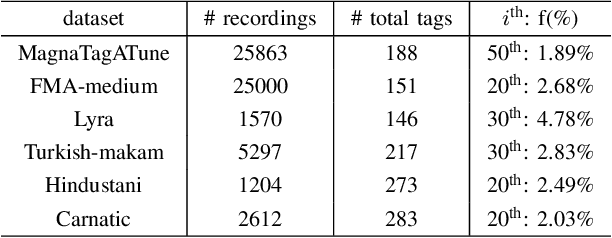
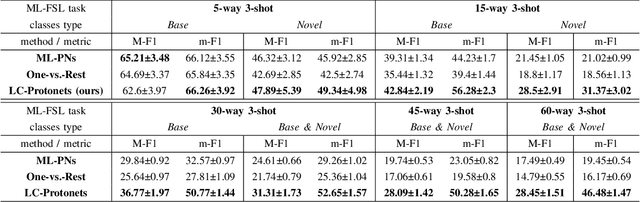
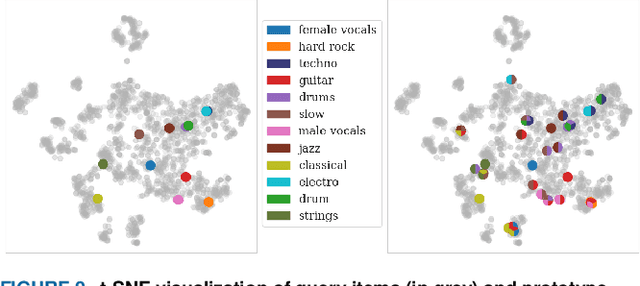
We introduce Label-Combination Prototypical Networks (LC-Protonets) to address the problem of multi-label few-shot classification, where a model must generalize to new classes based on only a few available examples. Extending Prototypical Networks, LC-Protonets generate one prototype per label combination, derived from the power set of labels present in the limited training items, rather than one prototype per label. Our method is applied to automatic audio tagging across diverse music datasets, covering various cultures and including both modern and traditional music, and is evaluated against existing approaches in the literature. The results demonstrate a significant performance improvement in almost all domains and training setups when using LC-Protonets for multi-label classification. In addition to training a few-shot learning model from scratch, we explore the use of a pre-trained model, obtained via supervised learning, to embed items in the feature space. Fine-tuning improves the generalization ability of all methods, yet LC-Protonets achieve high-level performance even without fine-tuning, in contrast to the comparative approaches. We finally analyze the scalability of the proposed method, providing detailed quantitative metrics from our experiments. The implementation and experimental setup are made publicly available, offering a benchmark for future research.
Enhancing Fast Feed Forward Networks with Load Balancing and a Master Leaf Node
May 27, 2024



Fast feedforward networks (FFFs) are a class of neural networks that exploit the observation that different regions of the input space activate distinct subsets of neurons in wide networks. FFFs partition the input space into separate sections using a differentiable binary tree of neurons and during inference descend the binary tree in order to improve computational efficiency. Inspired by Mixture of Experts (MoE) research, we propose the incorporation of load balancing and Master Leaf techniques into the FFF architecture to improve performance and simplify the training process. We reproduce experiments found in literature and present results on FFF models enhanced using these techniques. The proposed architecture and training recipe achieves up to 16.3% and 3% absolute classification accuracy increase in training and test accuracy, respectively, compared to the original FFF architecture. Additionally, we observe a smaller variance in the results compared to those reported in prior research. These findings demonstrate the potential of integrating MoE-inspired techniques into FFFs for developing more accurate and efficient models.
The Strong Pull of Prior Knowledge in Large Language Models and Its Impact on Emotion Recognition
Mar 25, 2024In-context Learning (ICL) has emerged as a powerful paradigm for performing natural language tasks with Large Language Models (LLM) without updating the models' parameters, in contrast to the traditional gradient-based finetuning. The promise of ICL is that the LLM can adapt to perform the present task at a competitive or state-of-the-art level at a fraction of the cost. The ability of LLMs to perform tasks in this few-shot manner relies on their background knowledge of the task (or task priors). However, recent work has found that, unlike traditional learning, LLMs are unable to fully integrate information from demonstrations that contrast task priors. This can lead to performance saturation at suboptimal levels, especially for subjective tasks such as emotion recognition, where the mapping from text to emotions can differ widely due to variability in human annotations. In this work, we design experiments and propose measurements to explicitly quantify the consistency of proxies of LLM priors and their pull on the posteriors. We show that LLMs have strong yet inconsistent priors in emotion recognition that ossify their predictions. We also find that the larger the model, the stronger these effects become. Our results suggest that caution is needed when using ICL with larger LLMs for affect-centered tasks outside their pre-training domain and when interpreting ICL results.