 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLC-Protonets: Multi-label Few-shot learning for world music audio tagging
Sep 17, 2024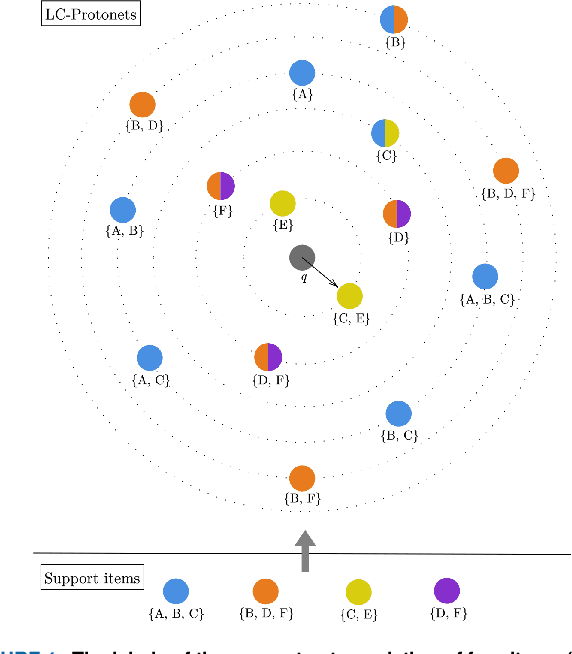
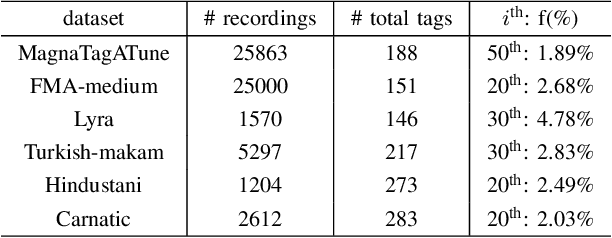
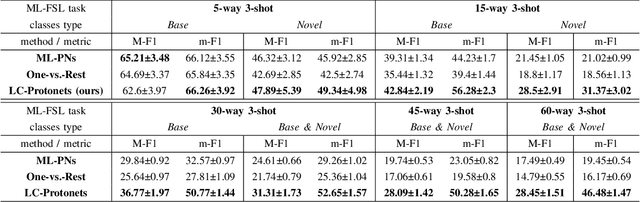
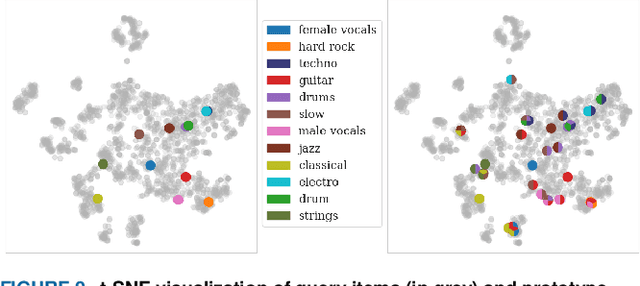
We introduce Label-Combination Prototypical Networks (LC-Protonets) to address the problem of multi-label few-shot classification, where a model must generalize to new classes based on only a few available examples. Extending Prototypical Networks, LC-Protonets generate one prototype per label combination, derived from the power set of labels present in the limited training items, rather than one prototype per label. Our method is applied to automatic audio tagging across diverse music datasets, covering various cultures and including both modern and traditional music, and is evaluated against existing approaches in the literature. The results demonstrate a significant performance improvement in almost all domains and training setups when using LC-Protonets for multi-label classification. In addition to training a few-shot learning model from scratch, we explore the use of a pre-trained model, obtained via supervised learning, to embed items in the feature space. Fine-tuning improves the generalization ability of all methods, yet LC-Protonets achieve high-level performance even without fine-tuning, in contrast to the comparative approaches. We finally analyze the scalability of the proposed method, providing detailed quantitative metrics from our experiments. The implementation and experimental setup are made publicly available, offering a benchmark for future research.
Enhancing Fast Feed Forward Networks with Load Balancing and a Master Leaf Node
May 27, 2024



Fast feedforward networks (FFFs) are a class of neural networks that exploit the observation that different regions of the input space activate distinct subsets of neurons in wide networks. FFFs partition the input space into separate sections using a differentiable binary tree of neurons and during inference descend the binary tree in order to improve computational efficiency. Inspired by Mixture of Experts (MoE) research, we propose the incorporation of load balancing and Master Leaf techniques into the FFF architecture to improve performance and simplify the training process. We reproduce experiments found in literature and present results on FFF models enhanced using these techniques. The proposed architecture and training recipe achieves up to 16.3% and 3% absolute classification accuracy increase in training and test accuracy, respectively, compared to the original FFF architecture. Additionally, we observe a smaller variance in the results compared to those reported in prior research. These findings demonstrate the potential of integrating MoE-inspired techniques into FFFs for developing more accurate and efficient models.
From West to East: Who can understand the music of the others better?
Jul 19, 2023



Recent developments in MIR have led to several benchmark deep learning models whose embeddings can be used for a variety of downstream tasks. At the same time, the vast majority of these models have been trained on Western pop/rock music and related styles. This leads to research questions on whether these models can be used to learn representations for different music cultures and styles, or whether we can build similar music audio embedding models trained on data from different cultures or styles. To that end, we leverage transfer learning methods to derive insights about the similarities between the different music cultures to which the data belongs to. We use two Western music datasets, two traditional/folk datasets coming from eastern Mediterranean cultures, and two datasets belonging to Indian art music. Three deep audio embedding models are trained and transferred across domains, including two CNN-based and a Transformer-based architecture, to perform auto-tagging for each target domain dataset. Experimental results show that competitive performance is achieved in all domains via transfer learning, while the best source dataset varies for each music culture. The implementation and the trained models are both provided in a public repository.
Self-Attention Based Generative Adversarial Networks For Unsupervised Video Summarization
Jul 16, 2023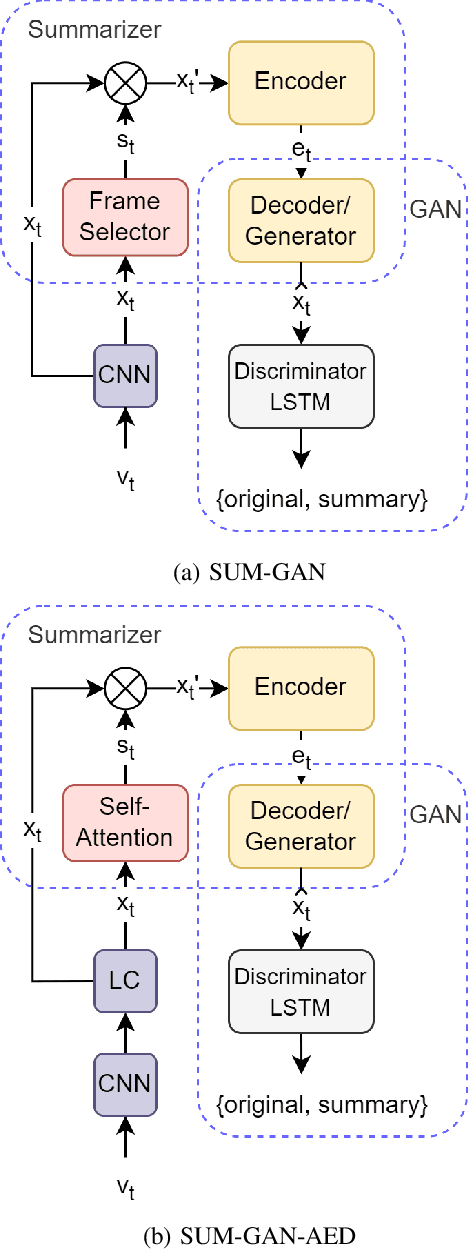


In this paper, we study the problem of producing a comprehensive video summary following an unsupervised approach that relies on adversarial learning. We build on a popular method where a Generative Adversarial Network (GAN) is trained to create representative summaries, indistinguishable from the originals. The introduction of the attention mechanism into the architecture for the selection, encoding and decoding of video frames, shows the efficacy of self-attention and transformer in modeling temporal relationships for video summarization. We propose the SUM-GAN-AED model that uses a self-attention mechanism for frame selection, combined with LSTMs for encoding and decoding. We evaluate the performance of the SUM-GAN-AED model on the SumMe, TVSum and COGNIMUSE datasets. Experimental results indicate that using a self-attention mechanism as the frame selection mechanism outperforms the state-of-the-art on SumMe and leads to comparable to state-of-the-art performance on TVSum and COGNIMUSE.
A Dataset for Greek Traditional and Folk Music: Lyra
Nov 21, 2022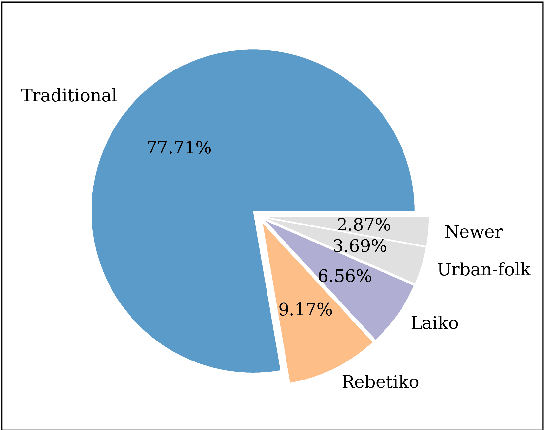
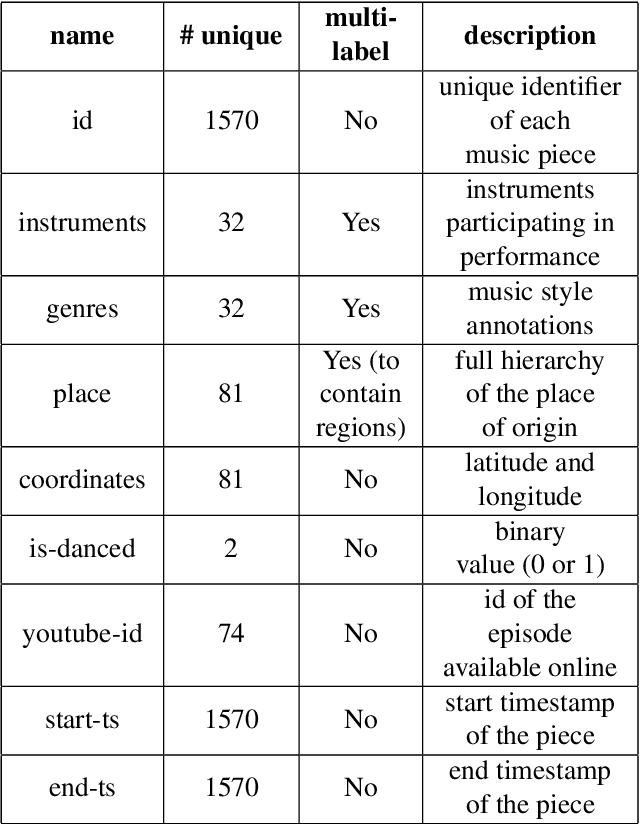
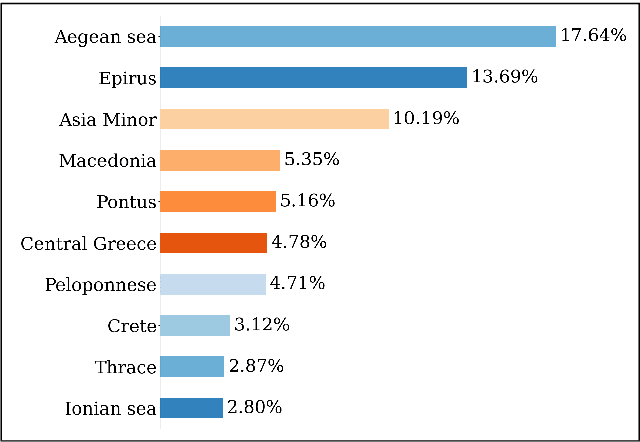
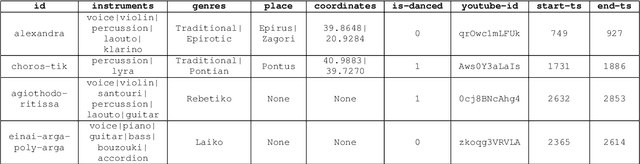
Studying under-represented music traditions under the MIR scope is crucial, not only for developing novel analysis tools, but also for unveiling musical functions that might prove useful in studying world musics. This paper presents a dataset for Greek Traditional and Folk music that includes 1570 pieces, summing in around 80 hours of data. The dataset incorporates YouTube timestamped links for retrieving audio and video, along with rich metadata information with regards to instrumentation, geography and genre, among others. The content has been collected from a Greek documentary series that is available online, where academics present music traditions of Greece with live music and dance performance during the show, along with discussions about social, cultural and musicological aspects of the presented music. Therefore, this procedure has resulted in a significant wealth of descriptions regarding a variety of aspects, such as musical genre, places of origin and musical instruments. In addition, the audio recordings were performed under strict production-level specifications, in terms of recording equipment, leading to very clean and homogeneous audio content. In this work, apart from presenting the dataset in detail, we propose a baseline deep-learning classification approach to recognize the involved musicological attributes. The dataset, the baseline classification methods and the models are provided in public repositories. Future directions for further refining the dataset are also discussed.