 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePay (Cross) Attention to the Melody: Curriculum Masking for Single-Encoder Melodic Harmonization
Jan 22, 2026Melodic harmonization, the task of generating harmonic accompaniments for a given melody, remains a central challenge in computational music generation. Recent single encoder transformer approaches have framed harmonization as a masked sequence modeling problem, but existing training curricula inspired by discrete diffusion often result in weak (cross) attention between melody and harmony. This leads to limited exploitation of melodic cues, particularly in out-of-domain contexts. In this work, we introduce a training curriculum, FF (full-to-full), which keeps all harmony tokens masked for several training steps before progressively unmasking entire sequences during training to strengthen melody-harmony interactions. We systematically evaluate this approach against prior curricula across multiple experimental axes, including temporal quantization (quarter vs. sixteenth note), bar-level vs. time-signature conditioning, melody representation (full range vs. pitch class), and inference-time unmasking strategies. Models are trained on the HookTheory dataset and evaluated both in-domain and on a curated collection of jazz standards, using a comprehensive set of metrics that assess chord progression structure, harmony-melody alignment, and rhythmic coherence. Results demonstrate that the proposed FF curriculum consistently outperforms baselines in nearly all metrics, with particularly strong gains in out-of-domain evaluations where harmonic adaptability to novel melodic queues is crucial. We further find that quarter-note quantization, intertwining of bar tokens, and pitch-class melody representations are advantageous in the FF setting. Our findings highlight the importance of training curricula in enabling effective melody conditioning and suggest that full-to-full unmasking offers a robust strategy for single encoder harmonization.
Exposing Hidden Biases in Text-to-Image Models via Automated Prompt Search
Dec 09, 2025Text-to-image (TTI) diffusion models have achieved remarkable visual quality, yet they have been repeatedly shown to exhibit social biases across sensitive attributes such as gender, race and age. To mitigate these biases, existing approaches frequently depend on curated prompt datasets - either manually constructed or generated with large language models (LLMs) - as part of their training and/or evaluation procedures. Beside the curation cost, this also risks overlooking unanticipated, less obvious prompts that trigger biased generation, even in models that have undergone debiasing. In this work, we introduce Bias-Guided Prompt Search (BGPS), a framework that automatically generates prompts that aim to maximize the presence of biases in the resulting images. BGPS comprises two components: (1) an LLM instructed to produce attribute-neutral prompts and (2) attribute classifiers acting on the TTI's internal representations that steer the decoding process of the LLM toward regions of the prompt space that amplify the image attributes of interest. We conduct extensive experiments on Stable Diffusion 1.5 and a state-of-the-art debiased model and discover an array of subtle and previously undocumented biases that severely deteriorate fairness metrics. Crucially, the discovered prompts are interpretable, i.e they may be entered by a typical user, quantitatively improving the perplexity metric compared to a prominent hard prompt optimization counterpart. Our findings uncover TTI vulnerabilities, while BGPS expands the bias search space and can act as a new evaluation tool for bias mitigation.
Incorporating Structure and Chord Constraints in Symbolic Transformer-based Melodic Harmonization
Dec 08, 2025Transformer architectures offer significant advantages regarding the generation of symbolic music; their capabilities for incorporating user preferences toward what they generate is being studied under many aspects. This paper studies the inclusion of predefined chord constraints in melodic harmonization, i.e., where a desired chord at a specific location is provided along with the melody as inputs and the autoregressive transformer model needs to incorporate the chord in the harmonization that it generates. The peculiarities of involving such constraints is discussed and an algorithm is proposed for tackling this task. This algorithm is called B* and it combines aspects of beam search and A* along with backtracking to force pretrained transformers to satisfy the chord constraints, at the correct onset position within the correct bar. The algorithm is brute-force and has exponential complexity in the worst case; however, this paper is a first attempt to highlight the difficulties of the problem and proposes an algorithm that offers many possibilities for improvements since it accommodates the involvement of heuristics.
VOX-KRIKRI: Unifying Speech and Language through Continuous Fusion
Sep 19, 2025We present a multimodal fusion framework that bridges pre-trained decoder-based large language models (LLM) and acoustic encoder-decoder architectures such as Whisper, with the aim of building speech-enabled LLMs. Instead of directly using audio embeddings, we explore an intermediate audio-conditioned text space as a more effective mechanism for alignment. Our method operates fully in continuous text representation spaces, fusing Whisper's hidden decoder states with those of an LLM through cross-modal attention, and supports both offline and streaming modes. We introduce \textit{VoxKrikri}, the first Greek speech LLM, and show through analysis that our approach effectively aligns representations across modalities. These results highlight continuous space fusion as a promising path for multilingual and low-resource speech LLMs, while achieving state-of-the-art results for Automatic Speech Recognition in Greek, providing an average $\sim20\%$ relative improvement across benchmarks.
MEDUSA: A Multimodal Deep Fusion Multi-Stage Training Framework for Speech Emotion Recognition in Naturalistic Conditions
Jun 11, 2025SER is a challenging task due to the subjective nature of human emotions and their uneven representation under naturalistic conditions. We propose MEDUSA, a multimodal framework with a four-stage training pipeline, which effectively handles class imbalance and emotion ambiguity. The first two stages train an ensemble of classifiers that utilize DeepSER, a novel extension of a deep cross-modal transformer fusion mechanism from pretrained self-supervised acoustic and linguistic representations. Manifold MixUp is employed for further regularization. The last two stages optimize a trainable meta-classifier that combines the ensemble predictions. Our training approach incorporates human annotation scores as soft targets, coupled with balanced data sampling and multitask learning. MEDUSA ranked 1st in Task 1: Categorical Emotion Recognition in the Interspeech 2025: Speech Emotion Recognition in Naturalistic Conditions Challenge.
Krikri: Advancing Open Large Language Models for Greek
May 19, 2025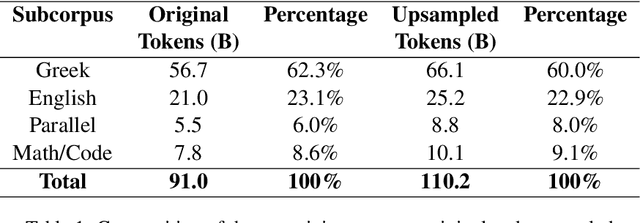
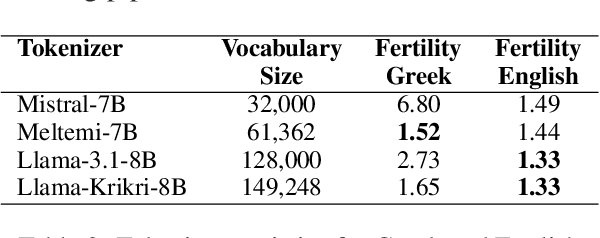
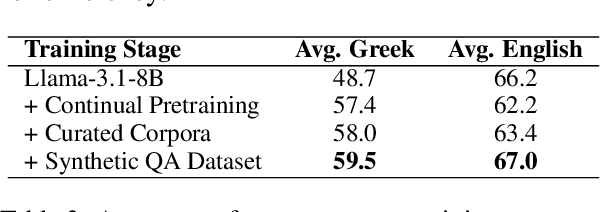

We introduce Llama-Krikri-8B, a cutting-edge Large Language Model tailored for the Greek language, built on Meta's Llama 3.1-8B. Llama-Krikri-8B has been extensively trained on high-quality Greek data to ensure superior adaptation to linguistic nuances. With 8 billion parameters, it offers advanced capabilities while maintaining efficient computational performance. Llama-Krikri-8B supports both Modern Greek and English, and is also equipped to handle polytonic text and Ancient Greek. The chat version of Llama-Krikri-8B features a multi-stage post-training pipeline, utilizing both human and synthetic instruction and preference data, by applying techniques such as MAGPIE. In addition, for evaluation, we propose three novel public benchmarks for Greek. Our evaluation on existing as well as the proposed benchmarks shows notable improvements over comparable Greek and multilingual LLMs in both natural language understanding and generation as well as code generation.
DeepMLF: Multimodal language model with learnable tokens for deep fusion in sentiment analysis
Apr 15, 2025While multimodal fusion has been extensively studied in Multimodal Sentiment Analysis (MSA), the role of fusion depth and multimodal capacity allocation remains underexplored. In this work, we position fusion depth, scalability, and dedicated multimodal capacity as primary factors for effective fusion. We introduce DeepMLF, a novel multimodal language model (LM) with learnable tokens tailored toward deep fusion. DeepMLF leverages an audiovisual encoder and a pretrained decoder LM augmented with multimodal information across its layers. We append learnable tokens to the LM that: 1) capture modality interactions in a controlled fashion and 2) preserve independent information flow for each modality. These fusion tokens gather linguistic information via causal self-attention in LM Blocks and integrate with audiovisual information through cross-attention MM Blocks. Serving as dedicated multimodal capacity, this design enables progressive fusion across multiple layers, providing depth in the fusion process. Our training recipe combines modality-specific losses and language modelling loss, with the decoder LM tasked to predict ground truth polarity. Across three MSA benchmarks with varying dataset characteristics, DeepMLF achieves state-of-the-art performance. Our results confirm that deeper fusion leads to better performance, with optimal fusion depths (5-7) exceeding those of existing approaches. Additionally, our analysis on the number of fusion tokens reveals that small token sets ($\sim$20) achieve optimal performance. We examine the importance of representation learning order (fusion curriculum) through audiovisual encoder initialization experiments. Our ablation studies demonstrate the superiority of the proposed fusion design and gating while providing a holistic examination of DeepMLF's scalability to LLMs, and the impact of each training objective and embedding regularization.
Meltemi: The first open Large Language Model for Greek
Jul 30, 2024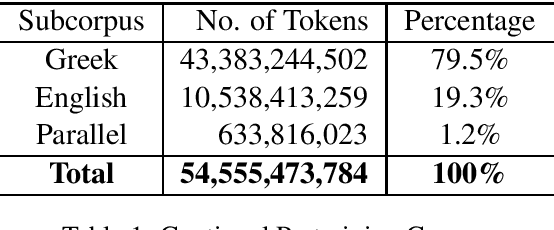
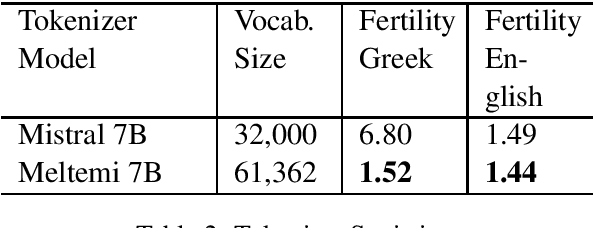
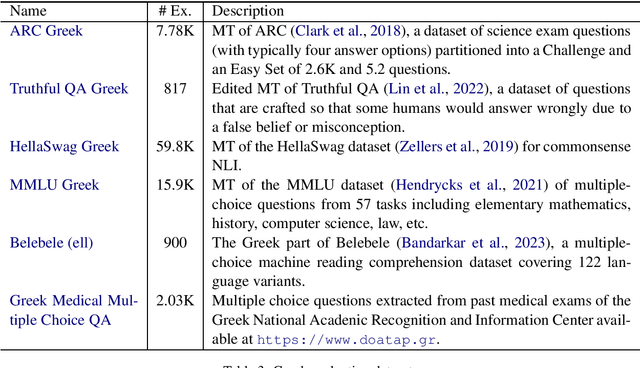
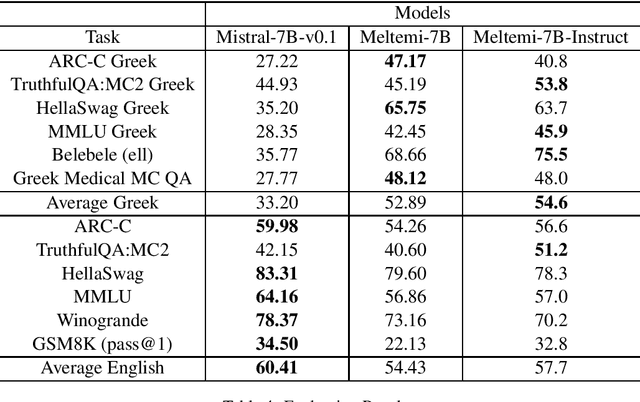
We describe the development and capabilities of Meltemi 7B, the first open Large Language Model for the Greek language. Meltemi 7B has 7 billion parameters and is trained on a 40 billion token Greek corpus. For the development of Meltemi 7B, we adapt Mistral, by continuous pretraining on the Greek Corpus. Meltemi 7B contains up-to-date information up to September 2023. Furthermore, we have translated and curated a Greek instruction corpus, which has been used for the instruction-tuning of a chat model, named Meltemi 7B Instruct. Special care has been given to the alignment and the removal of toxic content for the Meltemi 7B Instruct. The developed models are evaluated on a broad set of collected evaluation corpora, and examples of prompts and responses are presented. Both Meltemi 7B and Meltemi 7B Instruct are available at https://huggingface.co/ilsp under the Apache 2.0 license.
The Greek podcast corpus: Competitive speech models for low-resourced languages with weakly supervised data
Jun 21, 2024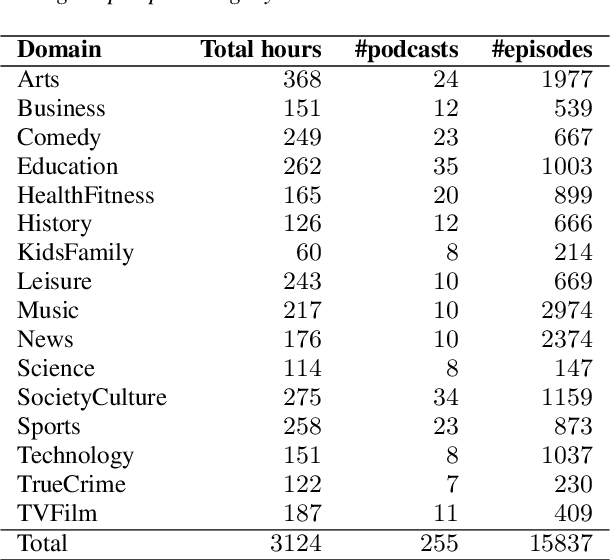
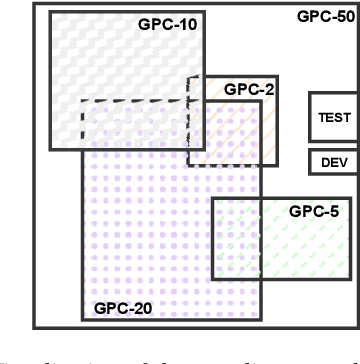
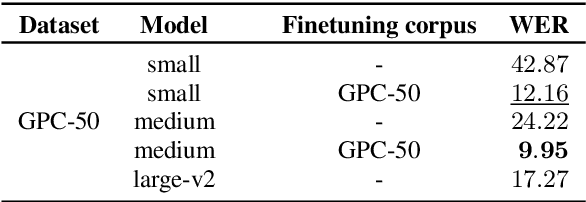
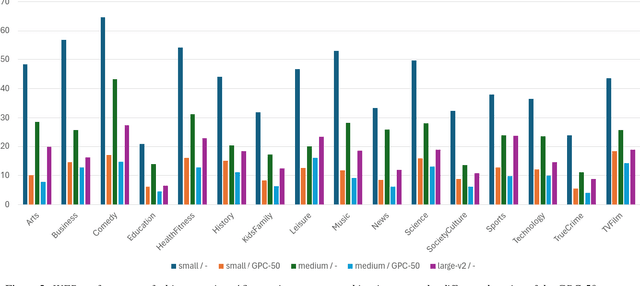
The development of speech technologies for languages with limited digital representation poses significant challenges, primarily due to the scarcity of available data. This issue is exacerbated in the era of large, data-intensive models. Recent research has underscored the potential of leveraging weak supervision to augment the pool of available data. In this study, we compile an 800-hour corpus of Modern Greek from podcasts and employ Whisper large-v3 to generate silver transcriptions. This corpus is utilized to fine-tune our models, aiming to assess the efficacy of this approach in enhancing ASR performance. Our analysis spans 16 distinct podcast domains, alongside evaluations on established datasets for Modern Greek. The findings indicate consistent WER improvements, correlating with increases in both data volume and model size. Our study confirms that assembling large, weakly supervised corpora serves as a cost-effective strategy for advancing speech technologies in under-resourced languages.
Weakly-supervised Automated Audio Captioning via text only training
Sep 21, 2023
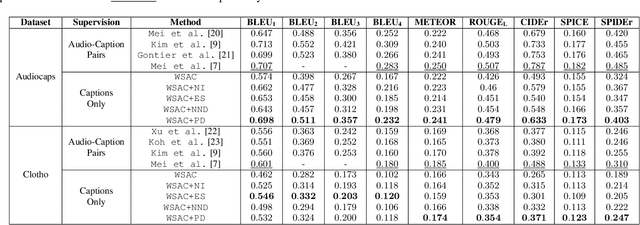
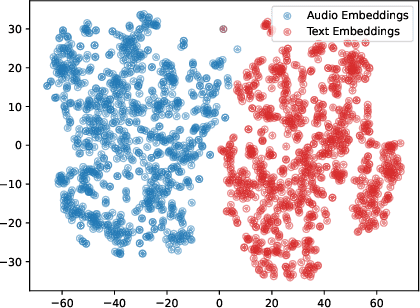

In recent years, datasets of paired audio and captions have enabled remarkable success in automatically generating descriptions for audio clips, namely Automated Audio Captioning (AAC). However, it is labor-intensive and time-consuming to collect a sufficient number of paired audio and captions. Motivated by the recent advances in Contrastive Language-Audio Pretraining (CLAP), we propose a weakly-supervised approach to train an AAC model assuming only text data and a pre-trained CLAP model, alleviating the need for paired target data. Our approach leverages the similarity between audio and text embeddings in CLAP. During training, we learn to reconstruct the text from the CLAP text embedding, and during inference, we decode using the audio embeddings. To mitigate the modality gap between the audio and text embeddings we employ strategies to bridge the gap during training and inference stages. We evaluate our proposed method on Clotho and AudioCaps datasets demonstrating its ability to achieve a relative performance of up to ~$83\%$ compared to fully supervised approaches trained with paired target data.