 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKrikri: Advancing Open Large Language Models for Greek
May 19, 2025
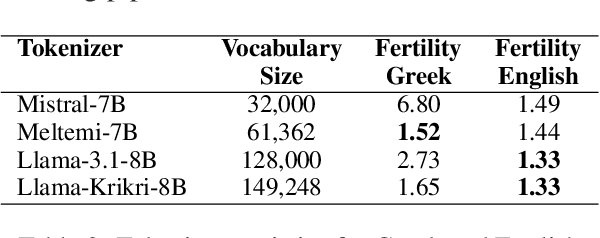
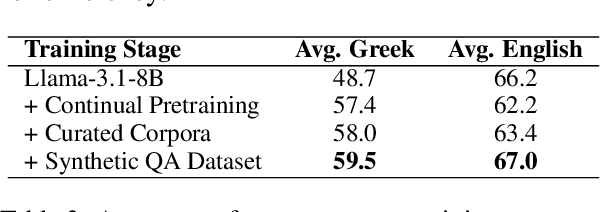

We introduce Llama-Krikri-8B, a cutting-edge Large Language Model tailored for the Greek language, built on Meta's Llama 3.1-8B. Llama-Krikri-8B has been extensively trained on high-quality Greek data to ensure superior adaptation to linguistic nuances. With 8 billion parameters, it offers advanced capabilities while maintaining efficient computational performance. Llama-Krikri-8B supports both Modern Greek and English, and is also equipped to handle polytonic text and Ancient Greek. The chat version of Llama-Krikri-8B features a multi-stage post-training pipeline, utilizing both human and synthetic instruction and preference data, by applying techniques such as MAGPIE. In addition, for evaluation, we propose three novel public benchmarks for Greek. Our evaluation on existing as well as the proposed benchmarks shows notable improvements over comparable Greek and multilingual LLMs in both natural language understanding and generation as well as code generation.
Meltemi: The first open Large Language Model for Greek
Jul 30, 2024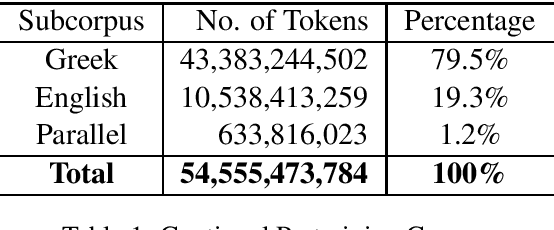
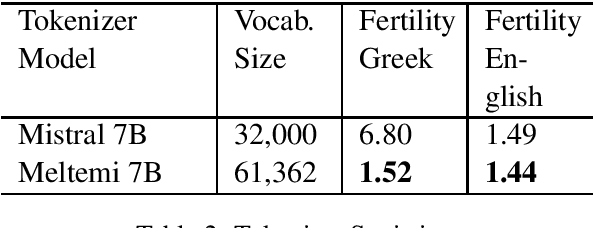
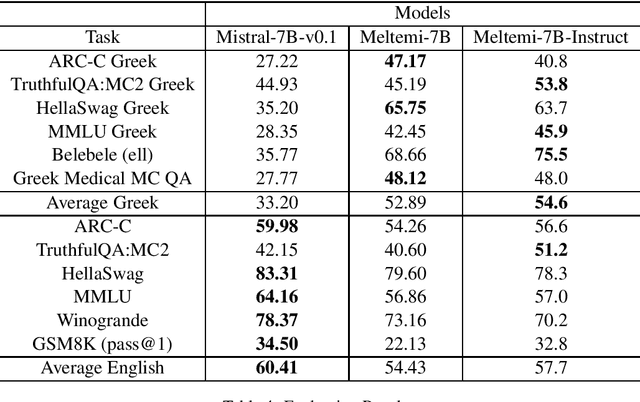
We describe the development and capabilities of Meltemi 7B, the first open Large Language Model for the Greek language. Meltemi 7B has 7 billion parameters and is trained on a 40 billion token Greek corpus. For the development of Meltemi 7B, we adapt Mistral, by continuous pretraining on the Greek Corpus. Meltemi 7B contains up-to-date information up to September 2023. Furthermore, we have translated and curated a Greek instruction corpus, which has been used for the instruction-tuning of a chat model, named Meltemi 7B Instruct. Special care has been given to the alignment and the removal of toxic content for the Meltemi 7B Instruct. The developed models are evaluated on a broad set of collected evaluation corpora, and examples of prompts and responses are presented. Both Meltemi 7B and Meltemi 7B Instruct are available at https://huggingface.co/ilsp under the Apache 2.0 license.
Findings of the Covid-19 MLIA Machine Translation Task
Nov 14, 2022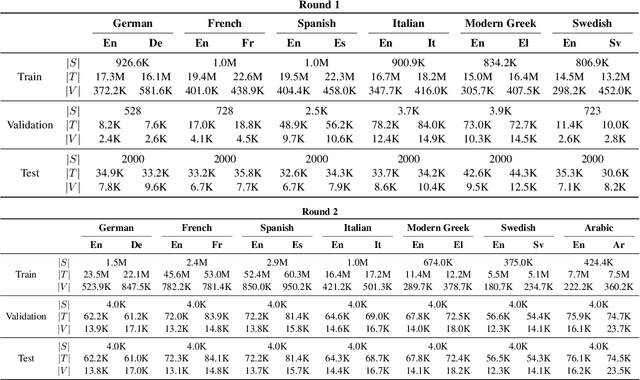
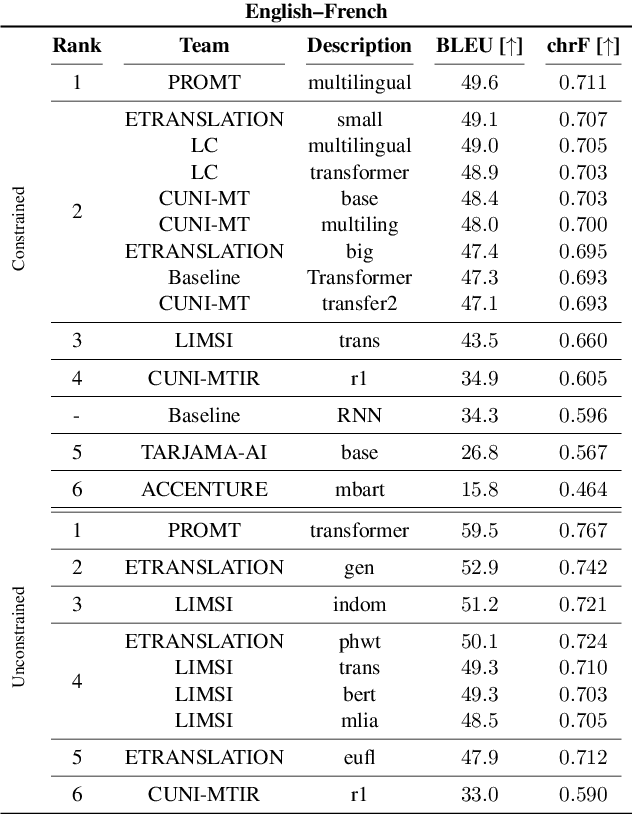
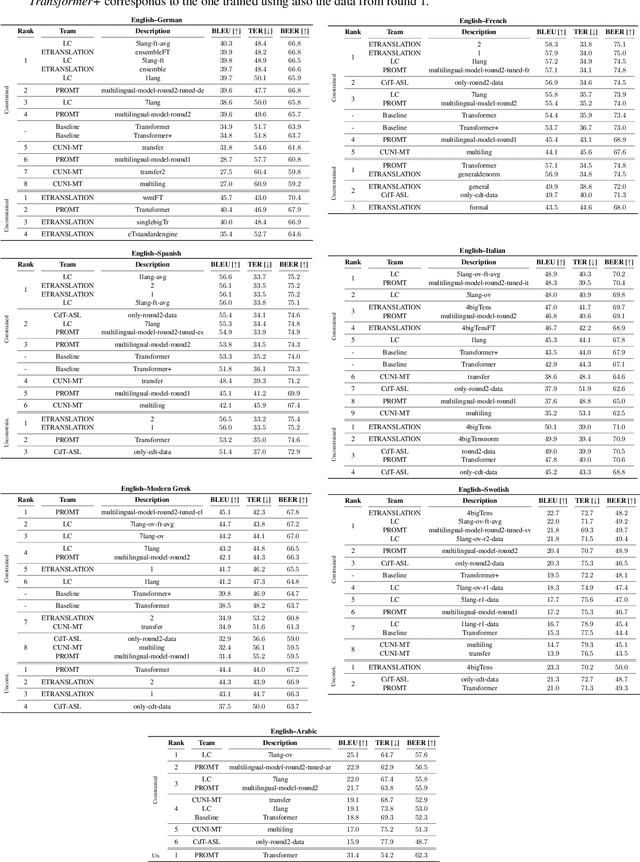
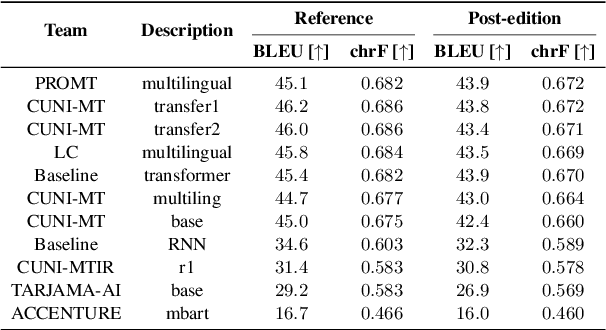
This work presents the results of the machine translation (MT) task from the Covid-19 MLIA @ Eval initiative, a community effort to improve the generation of MT systems focused on the current Covid-19 crisis. Nine teams took part in this event, which was divided in two rounds and involved seven different language pairs. Two different scenarios were considered: one in which only the provided data was allowed, and a second one in which the use of external resources was allowed. Overall, best approaches were based on multilingual models and transfer learning, with an emphasis on the importance of applying a cleaning process to the training data.