 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeltemi: The first open Large Language Model for Greek
Paper and Code
Jul 30, 2024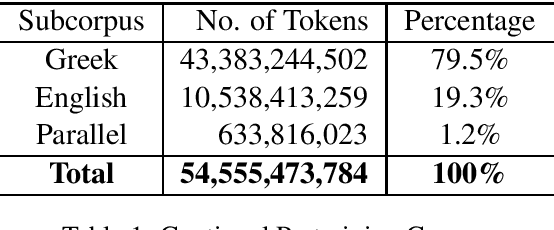
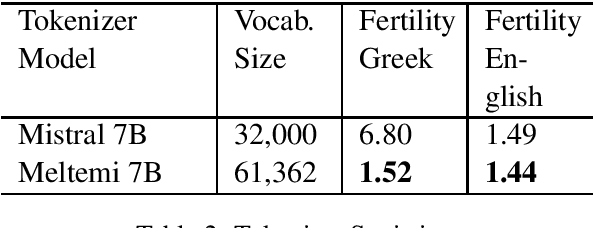
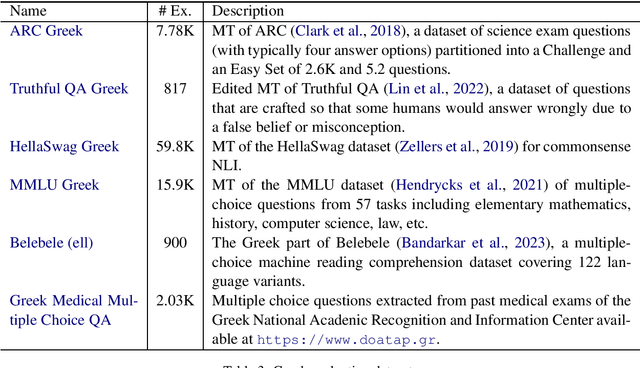
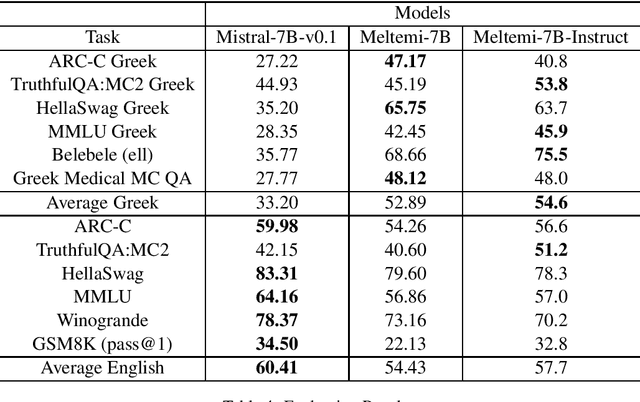
We describe the development and capabilities of Meltemi 7B, the first open Large Language Model for the Greek language. Meltemi 7B has 7 billion parameters and is trained on a 40 billion token Greek corpus. For the development of Meltemi 7B, we adapt Mistral, by continuous pretraining on the Greek Corpus. Meltemi 7B contains up-to-date information up to September 2023. Furthermore, we have translated and curated a Greek instruction corpus, which has been used for the instruction-tuning of a chat model, named Meltemi 7B Instruct. Special care has been given to the alignment and the removal of toxic content for the Meltemi 7B Instruct. The developed models are evaluated on a broad set of collected evaluation corpora, and examples of prompts and responses are presented. Both Meltemi 7B and Meltemi 7B Instruct are available at https://huggingface.co/ilsp under the Apache 2.0 license.