 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Evaluation of Machine Translation Systems on Images with Text
May 28, 2026This work presents a comparative evaluation of machine translation systems applied to images containing textual information, a task that lies at the intersection of computer vision and natural language processing. The study compares three main paradigms: modular pipelines that separate text detection, recognition, and translation; multi-modal large language models (MLLMs) capable of processing both image and text jointly; and an end-to-end model, Translatotron-V, which directly generates translated images. The modular systems employ state-of-the-art OCR (docTR) combined with multilingual LLMs such as Llama and EuroLLM, while the evaluated MLLMs include different configurations of Gemini 2.5. Experiments were conducted on parallel multilingual datasets covering multiple language pairs, with evaluation based on BLEU, chrF, and TER metrics. The results show that modular pipelines outperform the end-to-end approach, while MLLMs achieve the best overall performance, demonstrating superior flexibility and contextual understanding. These findings underscore the effectiveness of multi-modal reasoning for image-to-text translation and provide a solid foundation for future research on integrating visual understanding and language generation in multilingual settings.
DEEP: Docker-based Execution and Evaluation Platform
Feb 23, 2026Comparative evaluation of several systems is a recurrent task in researching. It is a key step before deciding which system to use for our work, or, once our research has been conducted, to demonstrate the potential of the resulting model. Furthermore, it is the main task of competitive, public challenges evaluation. Our proposed software (DEEP) automates both the execution and scoring of machine translation and optical character recognition models. Furthermore, it is easily extensible to other tasks. DEEP is prepared to receive dockerized systems, run them (extracting information at that same time), and assess hypothesis against some references. With this approach, evaluators can achieve a better understanding of the performance of each model. Moreover, the software uses a clustering algorithm based on a statistical analysis of the significance of the results yielded by each model, according to the evaluation metrics. As a result, evaluators are able to identify clusters of performance among the swarm of proposals and have a better understanding of the significance of their differences. Additionally, we offer a visualization web-app to ensure that the results can be adequately understood and interpreted. Finally, we present an exemplary case of use of DEEP.
Segment-Based Interactive Machine Translation for Pre-trained Models
Jul 09, 2024Pre-trained large language models (LLM) are starting to be widely used in many applications. In this work, we explore the use of these models in interactive machine translation (IMT) environments. In particular, we have chosen mBART (multilingual Bidirectional and Auto-Regressive Transformer) and mT5 (multilingual Text-to-Text Transfer Transformer) as the LLMs to perform our experiments. The system generates perfect translations interactively using the feedback provided by the user at each iteration. The Neural Machine Translation (NMT) model generates a preliminary hypothesis with the feedback, and the user validates new correct segments and performs a word correction--repeating the process until the sentence is correctly translated. We compared the performance of mBART, mT5, and a state-of-the-art (SoTA) machine translation model on a benchmark dataset regarding user effort, Word Stroke Ratio (WSR), Key Stroke Ratio (KSR), and Mouse Action Ratio (MAR). The experimental results indicate that mBART performed comparably with SoTA models, suggesting that it is a viable option for this field of IMT. The implications of this finding extend to the development of new machine translation models for interactive environments, as it indicates that some novel pre-trained models exhibit SoTA performance in this domain, highlighting the potential benefits of adapting these models to specific needs.
AutoNMT: A Framework to Streamline the Research of Seq2Seq Models
Feb 09, 2023



We present AutoNMT, a framework to streamline the research of seq-to-seq models by automating the data pipeline (i.e., file management, data preprocessing, and exploratory analysis), automating experimentation in a toolkit-agnostic manner, which allows users to use either their own models or existing seq-to-seq toolkits such as Fairseq or OpenNMT, and finally, automating the report generation (plots and summaries). Furthermore, this library comes with its own seq-to-seq toolkit so that users can easily customize it for non-standard tasks.
Findings of the Covid-19 MLIA Machine Translation Task
Nov 14, 2022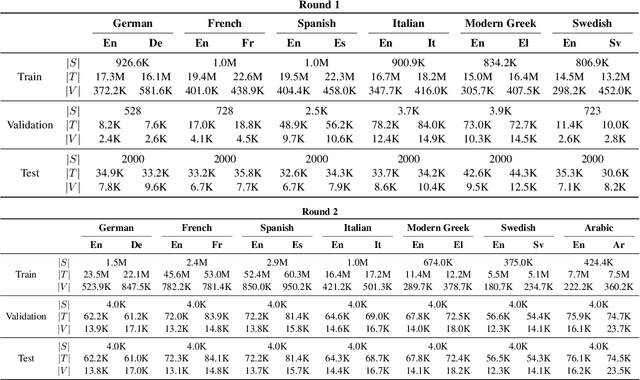
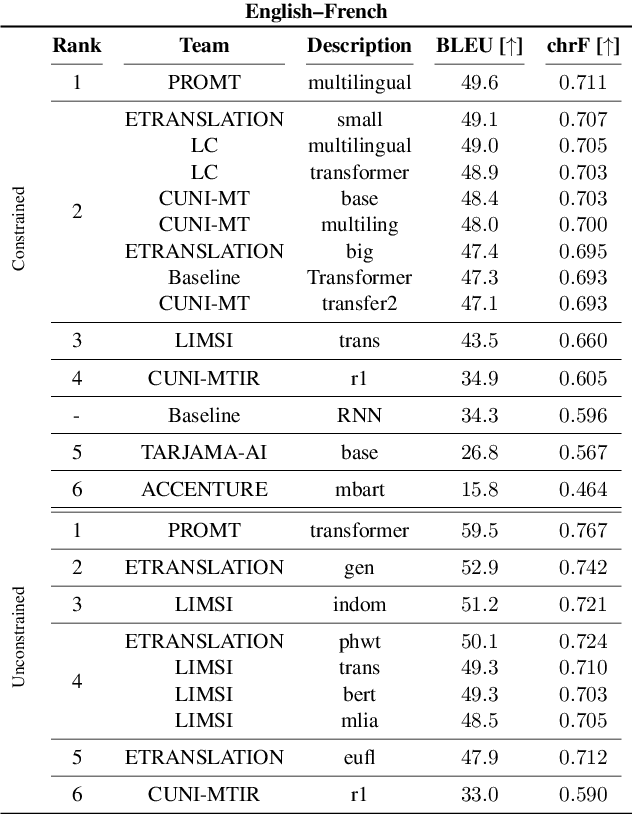
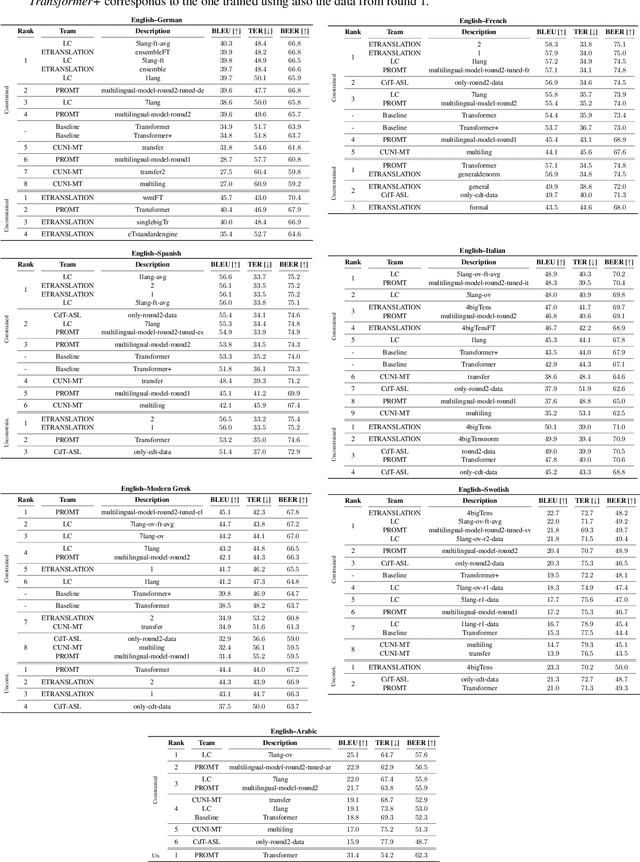
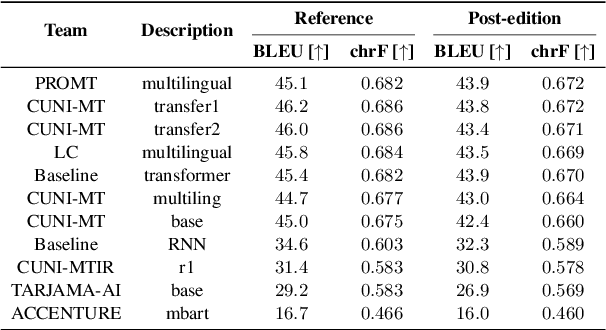
This work presents the results of the machine translation (MT) task from the Covid-19 MLIA @ Eval initiative, a community effort to improve the generation of MT systems focused on the current Covid-19 crisis. Nine teams took part in this event, which was divided in two rounds and involved seven different language pairs. Two different scenarios were considered: one in which only the provided data was allowed, and a second one in which the use of external resources was allowed. Overall, best approaches were based on multilingual models and transfer learning, with an emphasis on the importance of applying a cleaning process to the training data.
Two Demonstrations of the Machine Translation Applications to Historical Documents
Feb 02, 2021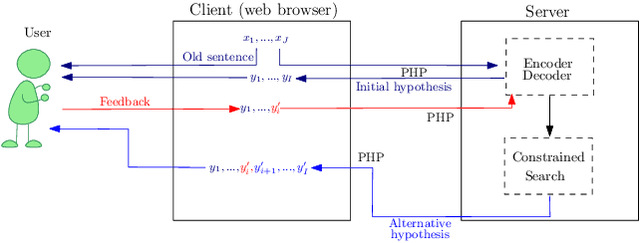
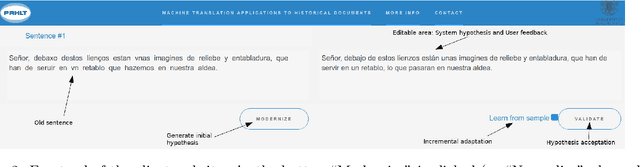
We present our demonstration of two machine translation applications to historical documents. The first task consists in generating a new version of a historical document, written in the modern version of its original language. The second application is limited to a document's orthography. It adapts the document's spelling to modern standards in order to achieve an orthography consistency and accounting for the lack of spelling conventions. We followed an interactive, adaptive framework that allows the user to introduce corrections to the system's hypothesis. The system reacts to these corrections by generating a new hypothesis that takes them into account. Once the user is satisfied with the system's hypothesis and validates it, the system adapts its model following an online learning strategy. This system is implemented following a client-server architecture. We developed a website which communicates with the neural models. All code is open-source and publicly available. The demonstration is hosted at http://demosmt.prhlt.upv.es/mthd/.
An Interactive Machine Translation Framework for Modernizing Historical Documents
Oct 08, 2019
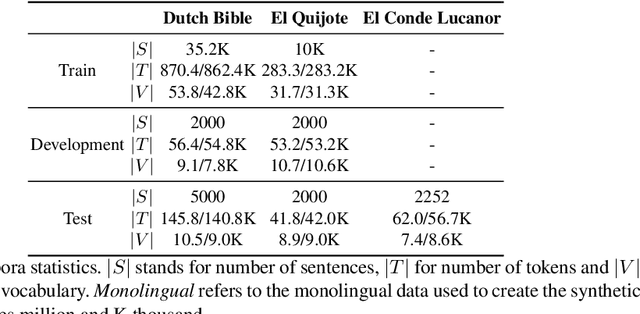

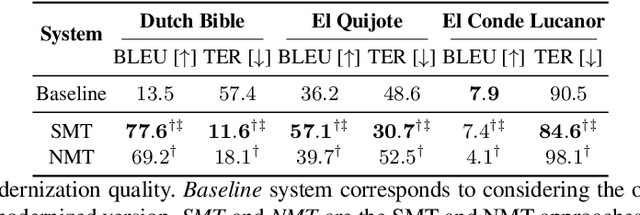
Due to the nature of human language, historical documents are hard to comprehend by contemporary people. This limits their accessibility to scholars specialized in the time period in which the documents were written. Modernization aims at breaking this language barrier by generating a new version of a historical document, written in the modern version of the document's original language. However, while it is able to increase the document's comprehension, modernization is still far from producing an error-free version. In this work, we propose a collaborative framework in which a scholar can work together with the machine to generate the new version. We tested our approach on a simulated environment, achieving significant reductions of the human effort needed to produce the modernized version of the document.
Modernizing Historical Documents: a User Study
Jul 01, 2019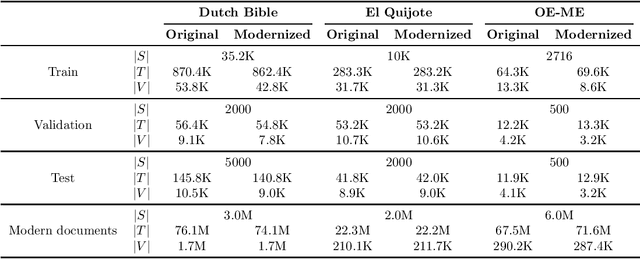



Accessibility to historical documents is mostly limited to scholars. This is due to the language barrier inherent in human language and the linguistic properties of these documents. Given a historical document, modernization aims to generate a new version of it, written in the modern version of the document's language. Its goal is to tackle the language barrier, decreasing the comprehension difficulty and making historical documents accessible to a broader audience. In this work, we proposed a new neural machine translation approach that profits from modern documents to enrich its systems. We tested this approach with both automatic and human evaluation, and conducted a user study. Results showed that modernization is successfully reaching its goal, although it still has room for improvement.
Demonstration of a Neural Machine Translation System with Online Learning for Translators
Jun 21, 2019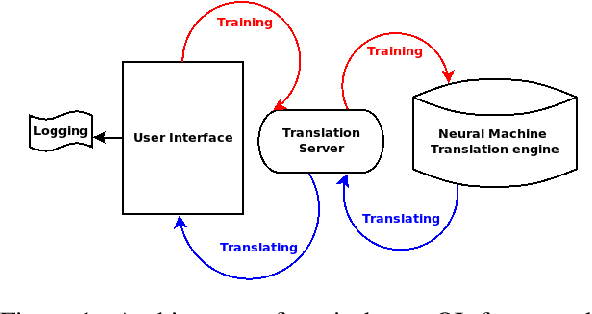
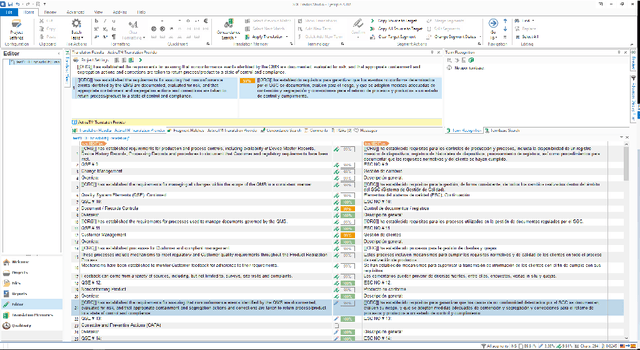
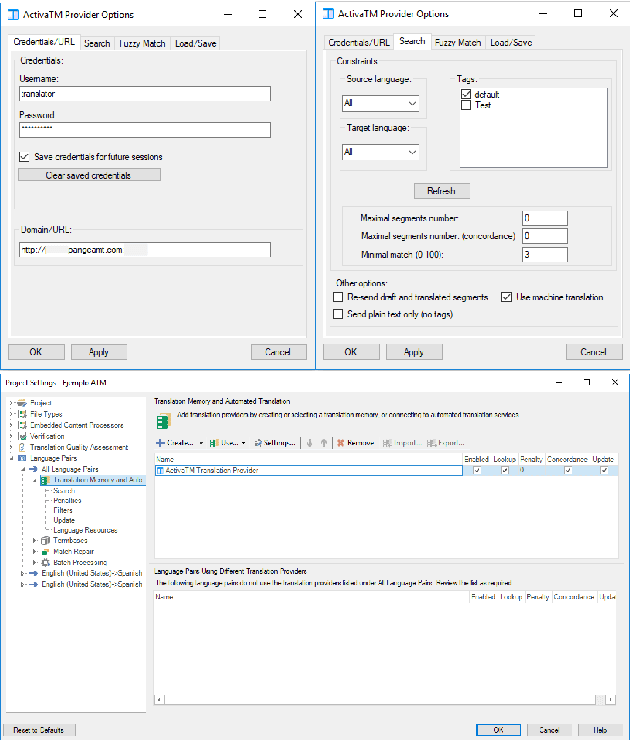

We introduce a demonstration of our system, which implements online learning for neural machine translation in a production environment. These techniques allow the system to continuously learn from the corrections provided by the translators. We implemented an end-to-end platform integrating our machine translation servers to one of the most common user interfaces for professional translators: SDL Trados Studio. Our objective was to save post-editing effort as the machine is continuously learning from human choices and adapting the models to a specific domain or user style.
Incremental Adaptation of NMT for Professional Post-editors: A User Study
Jun 21, 2019
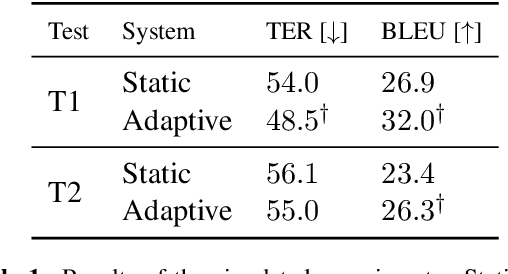

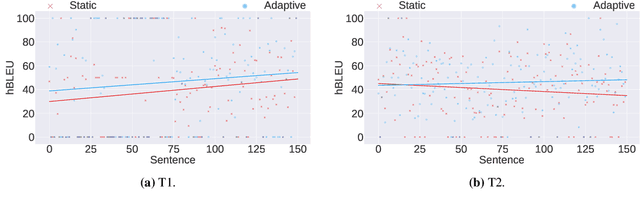
A common use of machine translation in the industry is providing initial translation hypotheses, which are later supervised and post-edited by a human expert. During this revision process, new bilingual data are continuously generated. Machine translation systems can benefit from these new data, incrementally updating the underlying models under an online learning paradigm. We conducted a user study on this scenario, for a neural machine translation system. The experimentation was carried out by professional translators, with a vast experience in machine translation post-editing. The results showed a reduction in the required amount of human effort needed when post-editing the outputs of the system, improvements in the translation quality and a positive perception of the adaptive system by the users.