 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemonstration of a Neural Machine Translation System with Online Learning for Translators
Jun 21, 2019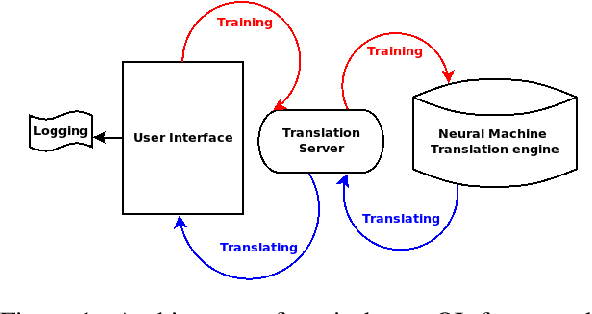

We introduce a demonstration of our system, which implements online learning for neural machine translation in a production environment. These techniques allow the system to continuously learn from the corrections provided by the translators. We implemented an end-to-end platform integrating our machine translation servers to one of the most common user interfaces for professional translators: SDL Trados Studio. Our objective was to save post-editing effort as the machine is continuously learning from human choices and adapting the models to a specific domain or user style.
Incremental Adaptation of NMT for Professional Post-editors: A User Study
Jun 21, 2019
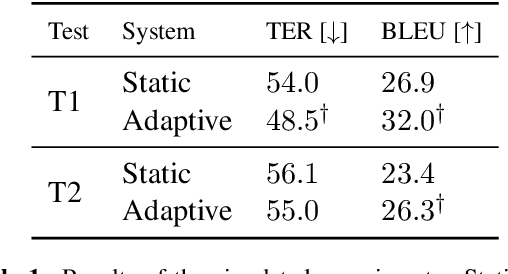

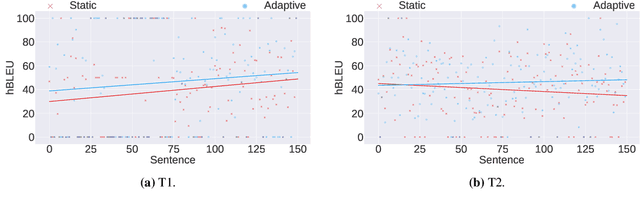
A common use of machine translation in the industry is providing initial translation hypotheses, which are later supervised and post-edited by a human expert. During this revision process, new bilingual data are continuously generated. Machine translation systems can benefit from these new data, incrementally updating the underlying models under an online learning paradigm. We conducted a user study on this scenario, for a neural machine translation system. The experimentation was carried out by professional translators, with a vast experience in machine translation post-editing. The results showed a reduction in the required amount of human effort needed when post-editing the outputs of the system, improvements in the translation quality and a positive perception of the adaptive system by the users.
Interactive-predictive neural multimodal systems
May 30, 2019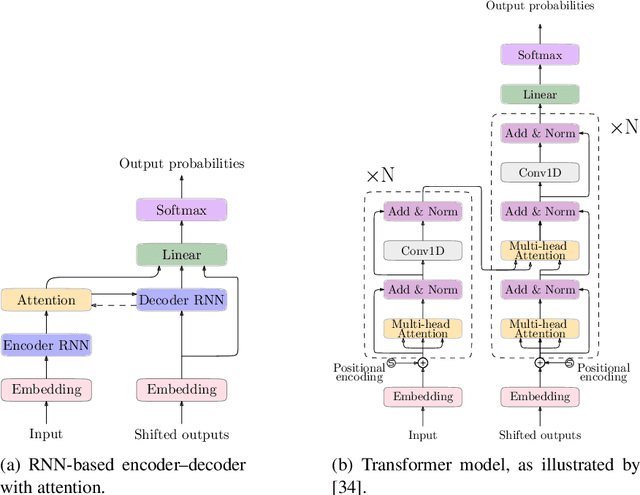
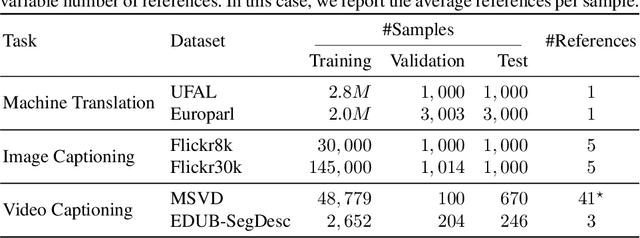
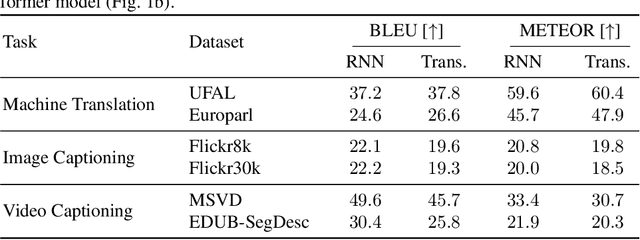

Despite the advances achieved by neural models in sequence to sequence learning, exploited in a variety of tasks, they still make errors. In many use cases, these are corrected by a human expert in a posterior revision process. The interactive-predictive framework aims to minimize the human effort spent on this process by considering partial corrections for iteratively refining the hypothesis. In this work, we generalize the interactive-predictive approach, typically applied in to machine translation field, to tackle other multimodal problems namely, image and video captioning. We study the application of this framework to multimodal neural sequence to sequence models. We show that, following this framework, we approximately halve the effort spent for correcting the outputs generated by the automatic systems. Moreover, we deploy our systems in a publicly accessible demonstration, that allows to better understand the behavior of the interactive-predictive framework.
A Neural, Interactive-predictive System for Multimodal Sequence to Sequence Tasks
May 30, 2019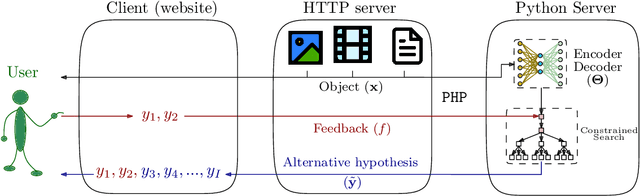
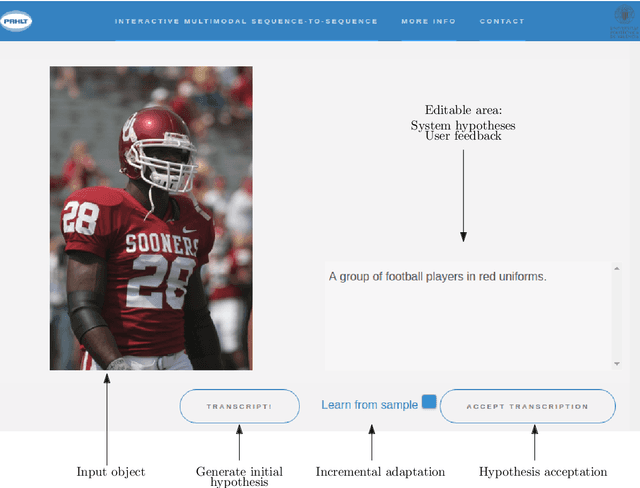

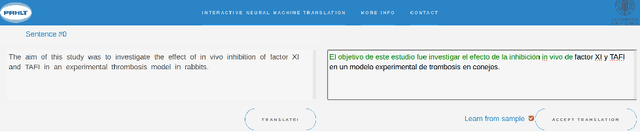
We present a demonstration of a neural interactive-predictive system for tackling multimodal sequence to sequence tasks. The system generates text predictions to different sequence to sequence tasks: machine translation, image and video captioning. These predictions are revised by a human agent, who introduces corrections in the form of characters. The system reacts to each correction, providing alternative hypotheses, compelling with the feedback provided by the user. The final objective is to reduce the human effort required during this correction process. This system is implemented following a client-server architecture. For accessing the system, we developed a website, which communicates with the neural model, hosted in a local server. From this website, the different tasks can be tackled following the interactive-predictive framework. We open-source all the code developed for building this system. The demonstration in hosted in http://casmacat.prhlt.upv.es/interactive-seq2seq.
Active Learning for Interactive Neural Machine Translation of Data Streams
Oct 25, 2018
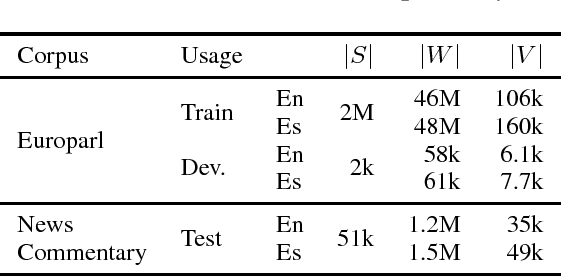
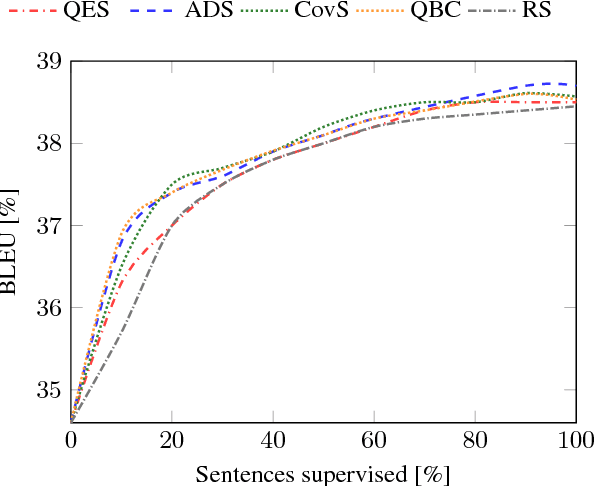
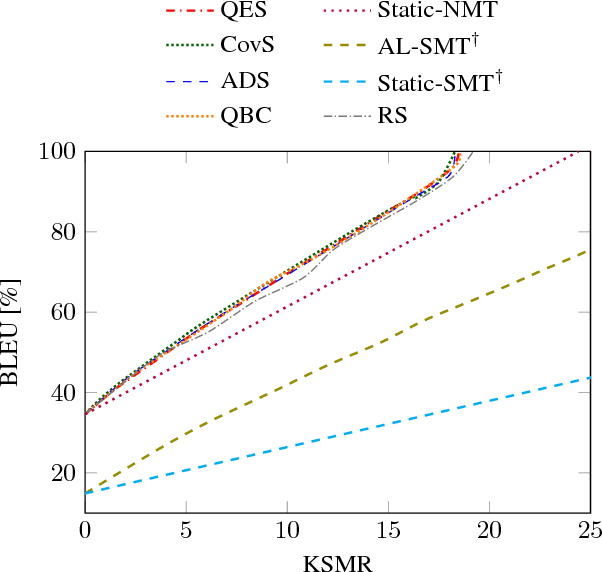
We study the application of active learning techniques to the translation of unbounded data streams via interactive neural machine translation. The main idea is to select, from an unbounded stream of source sentences, those worth to be supervised by a human agent. The user will interactively translate those samples. Once validated, these data is useful for adapting the neural machine translation model. We propose two novel methods for selecting the samples to be validated. We exploit the information from the attention mechanism of a neural machine translation system. Our experiments show that the inclusion of active learning techniques into this pipeline allows to reduce the effort required during the process, while increasing the quality of the translation system. Moreover, it enables to balance the human effort required for achieving a certain translation quality. Moreover, our neural system outperforms classical approaches by a large margin.
NMT-Keras: a Very Flexible Toolkit with a Focus on Interactive NMT and Online Learning
Aug 16, 2018
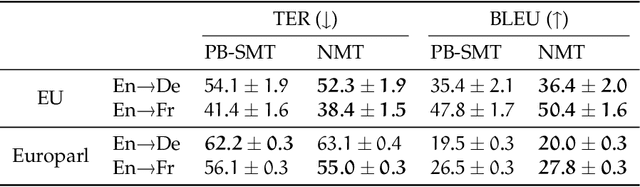
We present NMT-Keras, a flexible toolkit for training deep learning models, which puts a particular emphasis on the development of advanced applications of neural machine translation systems, such as interactive-predictive translation protocols and long-term adaptation of the translation system via continuous learning. NMT-Keras is based on an extended version of the popular Keras library, and it runs on Theano and Tensorflow. State-of-the-art neural machine translation models are deployed and used following the high-level framework provided by Keras. Given its high modularity and flexibility, it also has been extended to tackle different problems, such as image and video captioning, sentence classification and visual question answering.
Online Learning for Effort Reduction in Interactive Neural Machine Translation
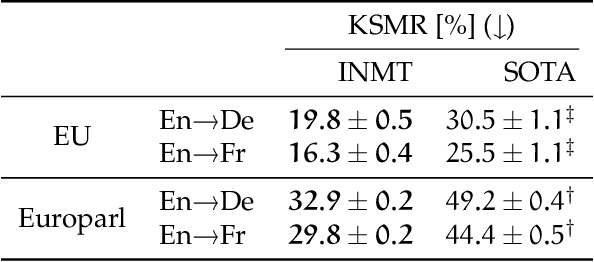
Feb 10, 2018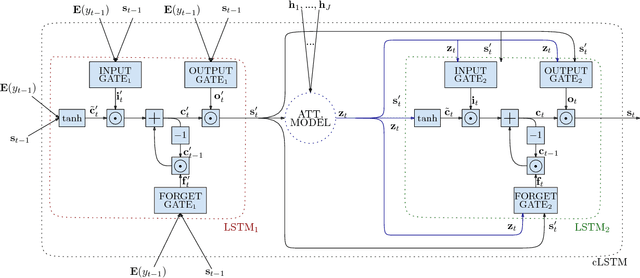
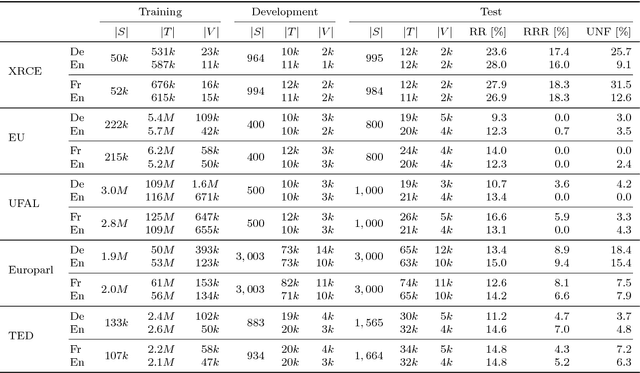
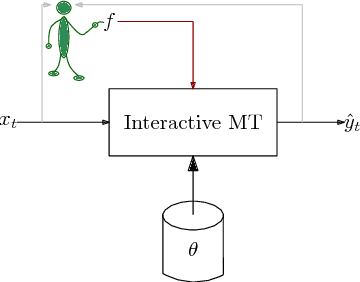
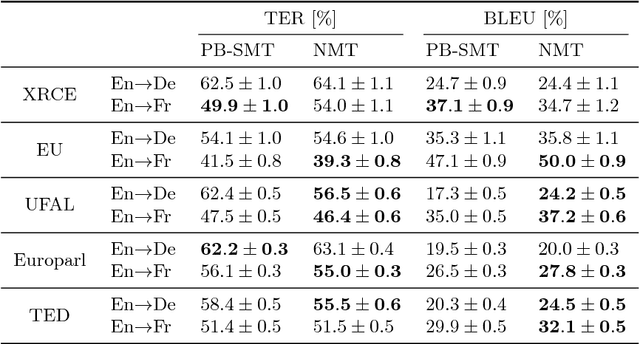
Neural machine translation systems require large amounts of training data and resources. Even with this, the quality of the translations may be insufficient for some users or domains. In such cases, the output of the system must be revised by a human agent. This can be done in a post-editing stage or following an interactive machine translation protocol. We explore the incremental update of neural machine translation systems during the post-editing or interactive translation processes. Such modifications aim to incorporate the new knowledge, from the edited sentences, into the translation system. Updates to the model are performed on-the-fly, as sentences are corrected, via online learning techniques. In addition, we implement a novel interactive, adaptive system, able to react to single-character interactions. This system greatly reduces the human effort required for obtaining high-quality translations. In order to stress our proposals, we conduct exhaustive experiments varying the amount and type of data available for training. Results show that online learning effectively achieves the objective of reducing the human effort required during the post-editing or the interactive machine translation stages. Moreover, these adaptive systems also perform well in scenarios with scarce resources. We show that a neural machine translation system can be rapidly adapted to a specific domain, exclusively by means of online learning techniques.
Egocentric Video Description based on Temporally-Linked Sequences
Nov 09, 2017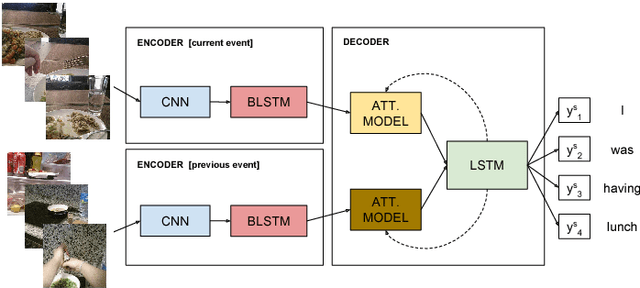

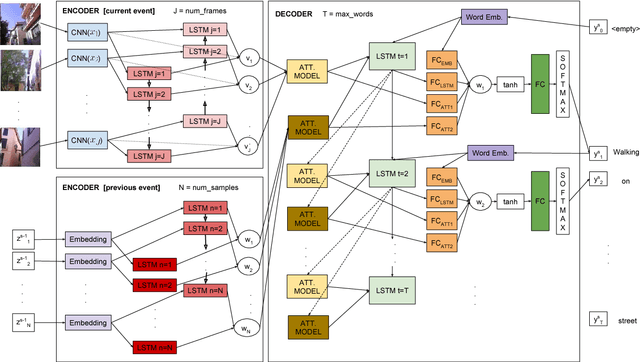

Egocentric vision consists in acquiring images along the day from a first person point-of-view using wearable cameras. The automatic analysis of this information allows to discover daily patterns for improving the quality of life of the user. A natural topic that arises in egocentric vision is storytelling, that is, how to understand and tell the story relying behind the pictures. In this paper, we tackle storytelling as an egocentric sequences description problem. We propose a novel methodology that exploits information from temporally neighboring events, matching precisely the nature of egocentric sequences. Furthermore, we present a new method for multimodal data fusion consisting on a multi-input attention recurrent network. We also publish the first dataset for egocentric image sequences description, consisting of 1,339 events with 3,991 descriptions, from 55 days acquired by 11 people. Furthermore, we prove that our proposal outperforms classical attentional encoder-decoder methods for video description.
Online Learning for Neural Machine Translation Post-editing
Jun 10, 2017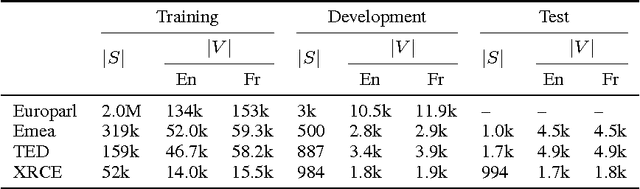
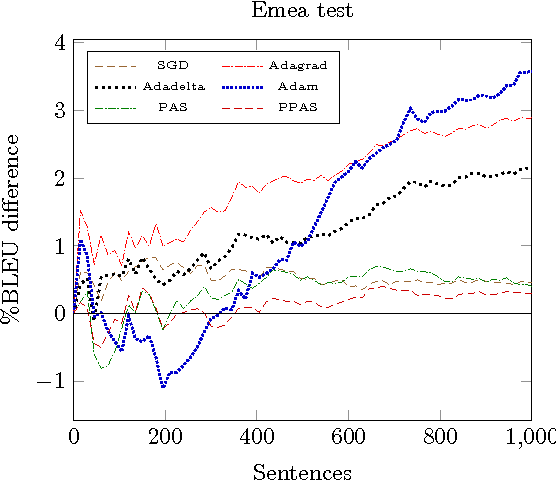

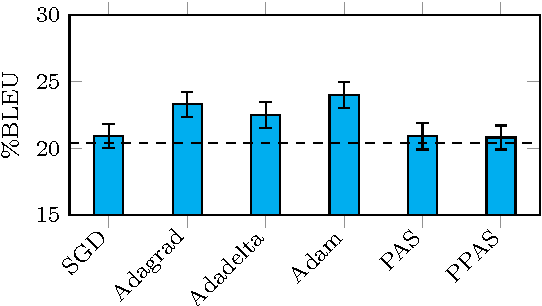
Neural machine translation has meant a revolution of the field. Nevertheless, post-editing the outputs of the system is mandatory for tasks requiring high translation quality. Post-editing offers a unique opportunity for improving neural machine translation systems, using online learning techniques and treating the post-edited translations as new, fresh training data. We review classical learning methods and propose a new optimization algorithm. We thoroughly compare online learning algorithms in a post-editing scenario. Results show significant improvements in translation quality and effort reduction.
Neural Networks Classifier for Data Selection in Statistical Machine Translation
Dec 21, 2016
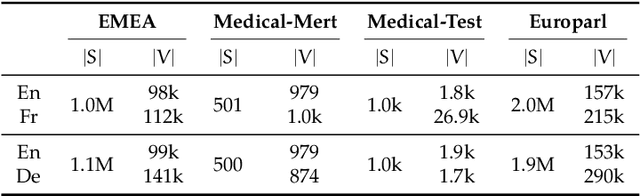
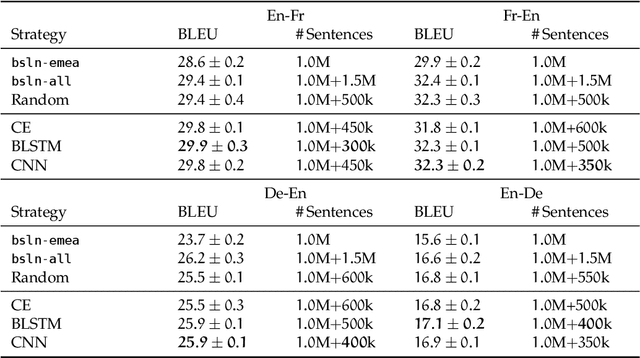
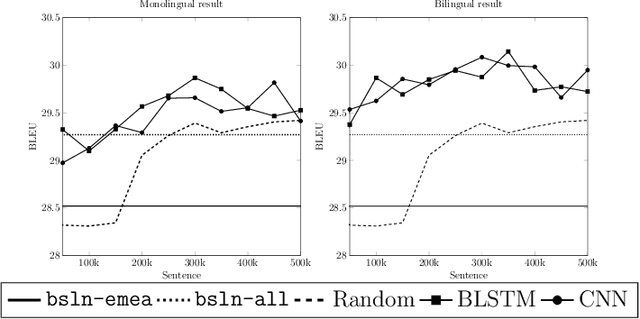
We address the data selection problem in statistical machine translation (SMT) as a classification task. The new data selection method is based on a neural network classifier. We present a new method description and empirical results proving that our data selection method provides better translation quality, compared to a state-of-the-art method (i.e., Cross entropy). Moreover, the empirical results reported are coherent across different language pairs.