 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELFIS: Expert Learning for Fine-grained Image Recognition Using Subsets
Mar 16, 2023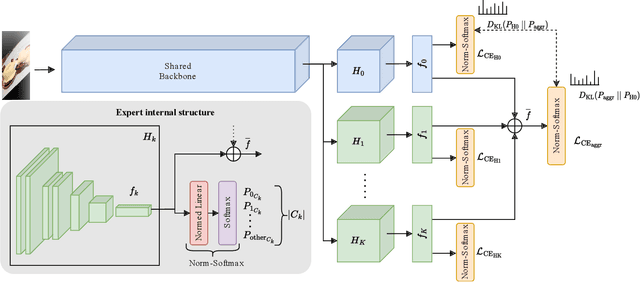
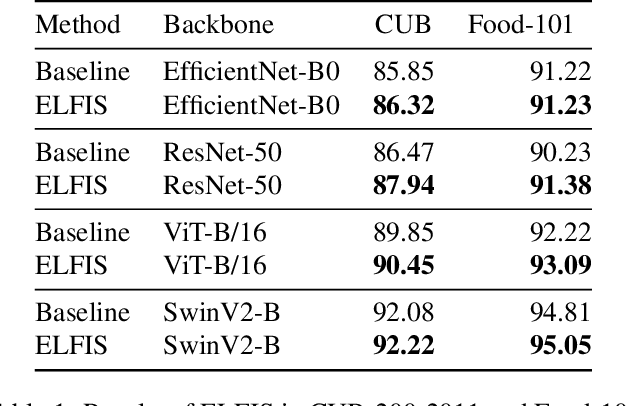
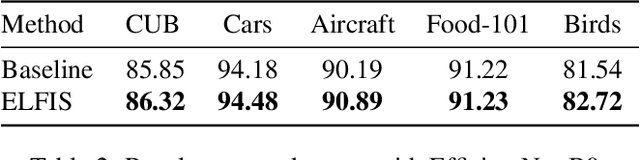

Fine-Grained Visual Recognition (FGVR) tackles the problem of distinguishing highly similar categories. One of the main approaches to FGVR, namely subset learning, tries to leverage information from existing class taxonomies to improve the performance of deep neural networks. However, these methods rely on the existence of handcrafted hierarchies that are not necessarily optimal for the models. In this paper, we propose ELFIS, an expert learning framework for FGVR that clusters categories of the dataset into meta-categories using both dataset-inherent lexical and model-specific information. A set of neural networks-based experts are trained focusing on the meta-categories and are integrated into a multi-task framework. Extensive experimentation shows improvements in the SoTA FGVR benchmarks of up to +1.3% of accuracy using both CNNs and transformer-based networks. Overall, the obtained results evidence that ELFIS can be applied on top of any classification model, enabling the obtention of SoTA results. The source code will be made public soon.
Grab, Pay and Eat: Semantic Food Detection for Smart Restaurants
Nov 14, 2017
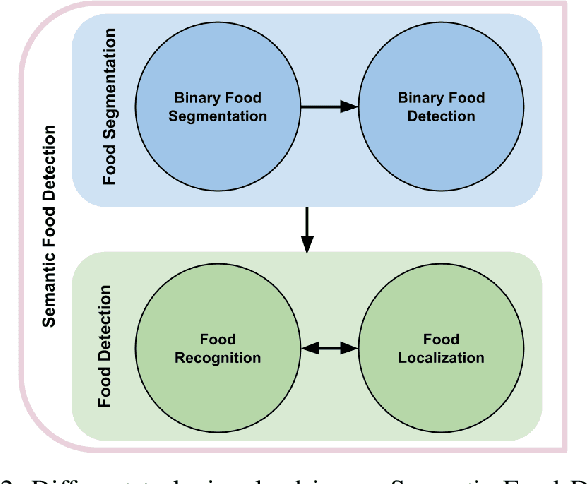
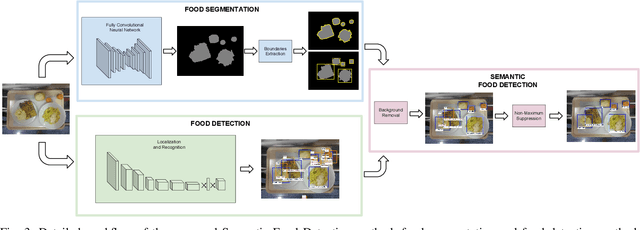

The increase in awareness of people towards their nutritional habits has drawn considerable attention to the field of automatic food analysis. Focusing on self-service restaurants environment, automatic food analysis is not only useful for extracting nutritional information from foods selected by customers, it is also of high interest to speed up the service solving the bottleneck produced at the cashiers in times of high demand. In this paper, we address the problem of automatic food tray analysis in canteens and restaurants environment, which consists in predicting multiple foods placed on a tray image. We propose a new approach for food analysis based on convolutional neural networks, we name Semantic Food Detection, which integrates in the same framework food localization, recognition and segmentation. We demonstrate that our method improves the state of the art food detection by a considerable margin on the public dataset UNIMIB2016 achieving about 90% in terms of F-measure, and thus provides a significant technological advance towards the automatic billing in restaurant environments.
Egocentric Video Description based on Temporally-Linked Sequences
Nov 09, 2017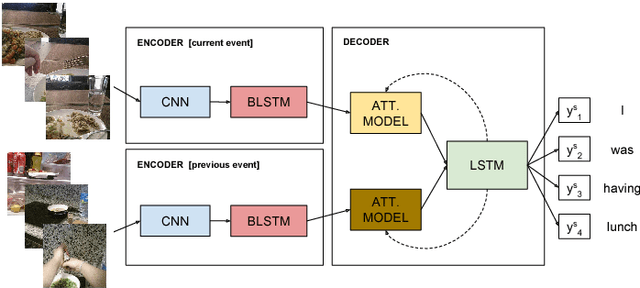

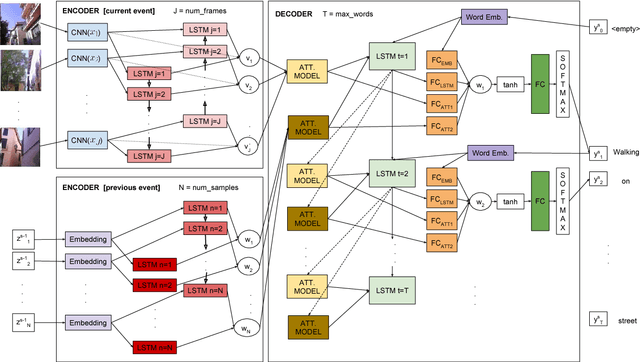

Egocentric vision consists in acquiring images along the day from a first person point-of-view using wearable cameras. The automatic analysis of this information allows to discover daily patterns for improving the quality of life of the user. A natural topic that arises in egocentric vision is storytelling, that is, how to understand and tell the story relying behind the pictures. In this paper, we tackle storytelling as an egocentric sequences description problem. We propose a novel methodology that exploits information from temporally neighboring events, matching precisely the nature of egocentric sequences. Furthermore, we present a new method for multimodal data fusion consisting on a multi-input attention recurrent network. We also publish the first dataset for egocentric image sequences description, consisting of 1,339 events with 3,991 descriptions, from 55 days acquired by 11 people. Furthermore, we prove that our proposal outperforms classical attentional encoder-decoder methods for video description.
Food Recognition using Fusion of Classifiers based on CNNs
Sep 14, 2017
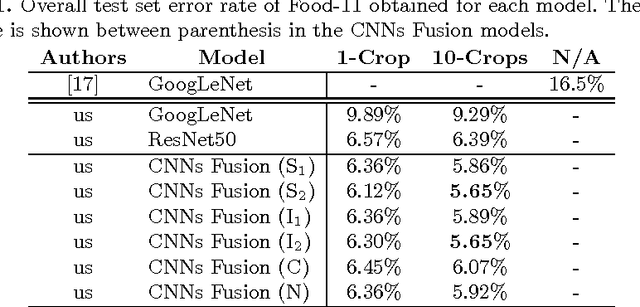
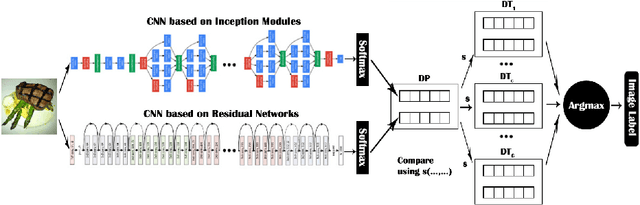

With the arrival of convolutional neural networks, the complex problem of food recognition has experienced an important improvement in recent years. The best results have been obtained using methods based on very deep convolutional neural networks, which show that the deeper the model,the better the classification accuracy will be obtain. However, very deep neural networks may suffer from the overfitting problem. In this paper, we propose a combination of multiple classifiers based on different convolutional models that complement each other and thus, achieve an improvement in performance. The evaluation of our approach is done on two public datasets: Food-101 as a dataset with a wide variety of fine-grained dishes, and Food-11 as a dataset of high-level food categories, where our approach outperforms the independent CNN models.
Exploring Food Detection using CNNs
Sep 14, 2017



One of the most common critical factors directly related to the cause of a chronic disease is unhealthy diet consumption. In this sense, building an automatic system for food analysis could allow a better understanding of the nutritional information with respect to the food eaten and thus it could help in taking corrective actions in order to consume a better diet. The Computer Vision community has focused its efforts on several areas involved in the visual food analysis such as: food detection, food recognition, food localization, portion estimation, among others. For food detection, the best results evidenced in the state of the art were obtained using Convolutional Neural Network. However, the results of all these different approaches were gotten on different datasets and therefore are not directly comparable. This article proposes an overview of the last advances on food detection and an optimal model based on GoogLeNet Convolutional Neural Network method, principal component analysis, and a support vector machine that outperforms the state of the art on two public food/non-food datasets.
Semantic Summarization of Egocentric Photo Stream Events
Aug 18, 2017
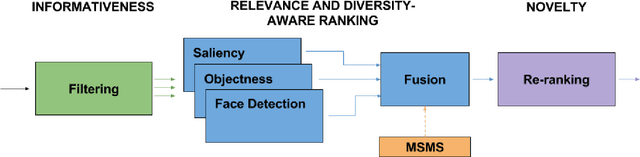


With the rapid increase of users of wearable cameras in recent years and of the amount of data they produce, there is a strong need for automatic retrieval and summarization techniques. This work addresses the problem of automatically summarizing egocentric photo streams captured through a wearable camera by taking an image retrieval perspective. After removing non-informative images by a new CNN-based filter, images are ranked by relevance to ensure semantic diversity and finally re-ranked by a novelty criterion to reduce redundancy. To assess the results, a new evaluation metric is proposed which takes into account the non-uniqueness of the solution. Experimental results applied on a database of 7,110 images from 6 different subjects and evaluated by experts gave 95.74% of experts satisfaction and a Mean Opinion Score of 4.57 out of 5.0. Source code is available at https://github.com/imatge-upc/egocentric-2017-lta
Serious Games Application for Memory Training Using Egocentric Images
Jul 27, 2017



Mild cognitive impairment is the early stage of several neurodegenerative diseases, such as Alzheimer's. In this work, we address the use of lifelogging as a tool to obtain pictures from a patient's daily life from an egocentric point of view. We propose to use them in combination with serious games as a way to provide a non-pharmacological treatment to improve their quality of life. To do so, we introduce a novel computer vision technique that classifies rich and non rich egocentric images and uses them in serious games. We present results over a dataset composed by 10,997 images, recorded by 7 different users, achieving 79% of F1-score. Our model presents the first method used for automatic egocentric images selection applicable to serious games.
Food Ingredients Recognition through Multi-label Learning
Jul 27, 2017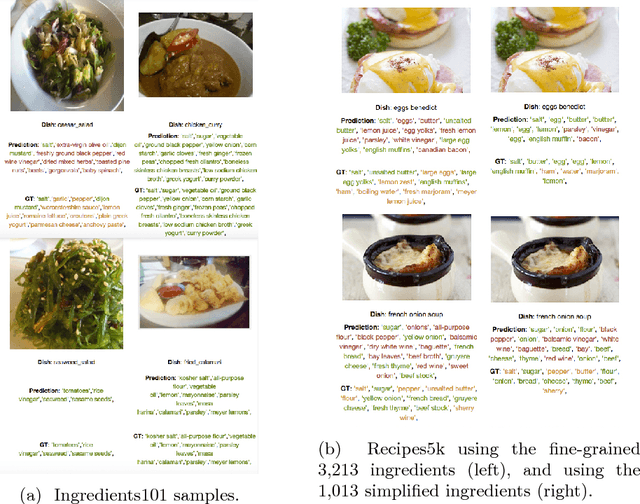
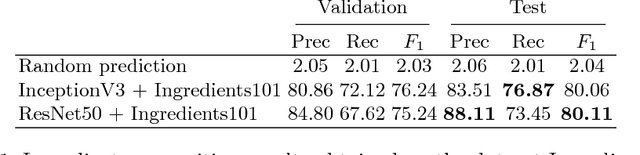
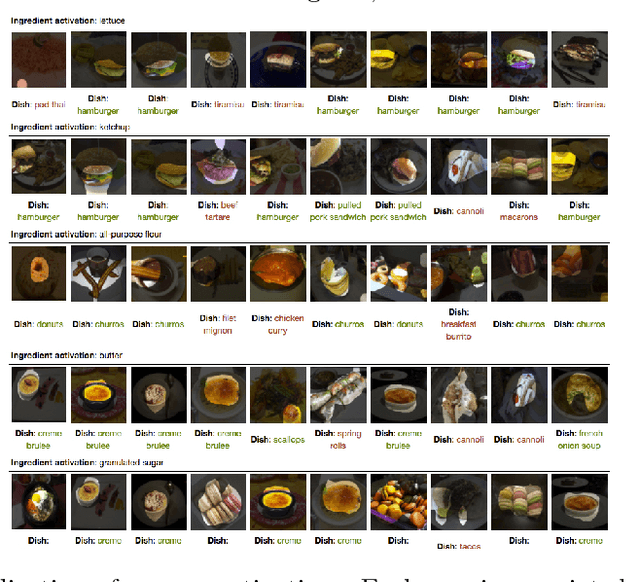
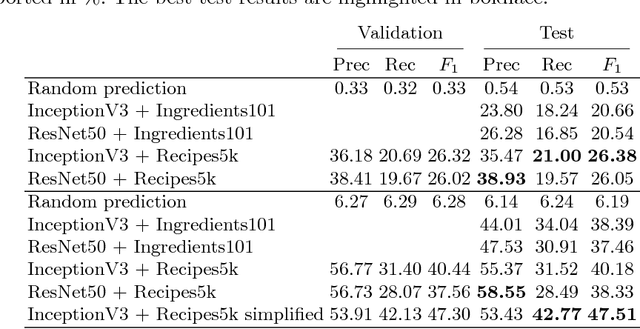
Automatically constructing a food diary that tracks the ingredients consumed can help people follow a healthy diet. We tackle the problem of food ingredients recognition as a multi-label learning problem. We propose a method for adapting a highly performing state of the art CNN in order to act as a multi-label predictor for learning recipes in terms of their list of ingredients. We prove that our model is able to, given a picture, predict its list of ingredients, even if the recipe corresponding to the picture has never been seen by the model. We make public two new datasets suitable for this purpose. Furthermore, we prove that a model trained with a high variability of recipes and ingredients is able to generalize better on new data, and visualize how it specializes each of its neurons to different ingredients.
R-Clustering for Egocentric Video Segmentation
Apr 10, 2017



In this paper, we present a new method for egocentric video temporal segmentation based on integrating a statistical mean change detector and agglomerative clustering(AC) within an energy-minimization framework. Given the tendency of most AC methods to oversegment video sequences when clustering their frames, we combine the clustering with a concept drift detection technique (ADWIN) that has rigorous guarantee of performances. ADWIN serves as a statistical upper bound for the clustering-based video segmentation. We integrate both techniques in an energy-minimization framework that serves to disambiguate the decision of both techniques and to complete the segmentation taking into account the temporal continuity of video frames descriptors. We present experiments over egocentric sets of more than 13.000 images acquired with different wearable cameras, showing that our method outperforms state-of-the-art clustering methods.
Simultaneous Food Localization and Recognition
Jan 19, 2017
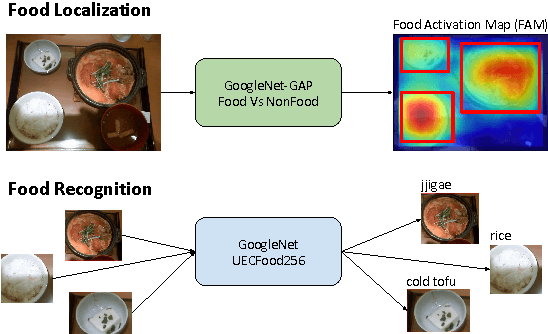
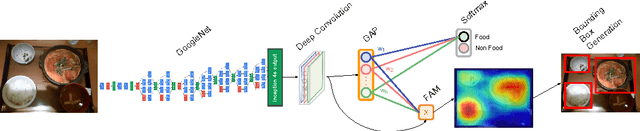
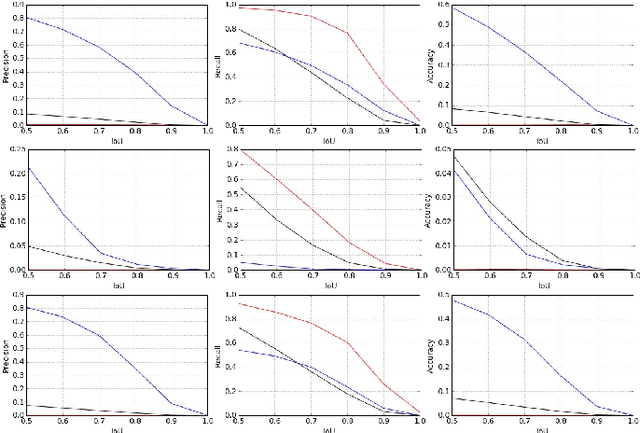
The development of automatic nutrition diaries, which would allow to keep track objectively of everything we eat, could enable a whole new world of possibilities for people concerned about their nutrition patterns. With this purpose, in this paper we propose the first method for simultaneous food localization and recognition. Our method is based on two main steps, which consist in, first, produce a food activation map on the input image (i.e. heat map of probabilities) for generating bounding boxes proposals and, second, recognize each of the food types or food-related objects present in each bounding box. We demonstrate that our proposal, compared to the most similar problem nowadays - object localization, is able to obtain high precision and reasonable recall levels with only a few bounding boxes. Furthermore, we show that it is applicable to both conventional and egocentric images.