 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConjuring Positive Pairs for Efficient Unification of Representation Learning and Image Synthesis
Mar 20, 2025While representation learning and generative modeling seek to understand visual data, unifying both domains remains unexplored. Recent Unified Self-Supervised Learning (SSL) methods have started to bridge the gap between both paradigms. However, they rely solely on semantic token reconstruction, which requires an external tokenizer during training -- introducing a significant overhead. In this work, we introduce Sorcen, a novel unified SSL framework, incorporating a synergic Contrastive-Reconstruction objective. Our Contrastive objective, "Echo Contrast", leverages the generative capabilities of Sorcen, eliminating the need for additional image crops or augmentations during training. Sorcen "generates" an echo sample in the semantic token space, forming the contrastive positive pair. Sorcen operates exclusively on precomputed tokens, eliminating the need for an online token transformation during training, thereby significantly reducing computational overhead. Extensive experiments on ImageNet-1k demonstrate that Sorcen outperforms the previous Unified SSL SoTA by 0.4%, 1.48 FID, 1.76%, and 1.53% on linear probing, unconditional image generation, few-shot learning, and transfer learning, respectively, while being 60.8% more efficient. Additionally, Sorcen surpasses previous single-crop MIM SoTA in linear probing and achieves SoTA performance in unconditional image generation, highlighting significant improvements and breakthroughs in Unified SSL models.
Precision at Scale: Domain-Specific Datasets On-Demand
Jul 03, 2024



In the realm of self-supervised learning (SSL), conventional wisdom has gravitated towards the utility of massive, general domain datasets for pretraining robust backbones. In this paper, we challenge this idea by exploring if it is possible to bridge the scale between general-domain datasets and (traditionally smaller) domain-specific datasets to reduce the current performance gap. More specifically, we propose Precision at Scale (PaS), a novel method for the autonomous creation of domain-specific datasets on-demand. The modularity of the PaS pipeline enables leveraging state-of-the-art foundational and generative models to create a collection of images of any given size belonging to any given domain with minimal human intervention. Extensive analysis in two complex domains, proves the superiority of PaS datasets over existing traditional domain-specific datasets in terms of diversity, scale, and effectiveness in training visual transformers and convolutional neural networks. Most notably, we prove that automatically generated domain-specific datasets lead to better pretraining than large-scale supervised datasets such as ImageNet-1k and ImageNet-21k. Concretely, models trained on domain-specific datasets constructed by PaS pipeline, beat ImageNet-1k pretrained backbones by at least 12% in all the considered domains and classification tasks and lead to better food domain performance than supervised ImageNet-21k pretrain while being 12 times smaller. Code repository: https://github.com/jesusmolrdv/Precision-at-Scale/
ELFIS: Expert Learning for Fine-grained Image Recognition Using Subsets
Mar 16, 2023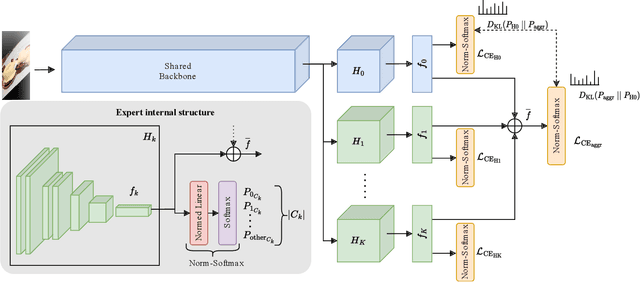
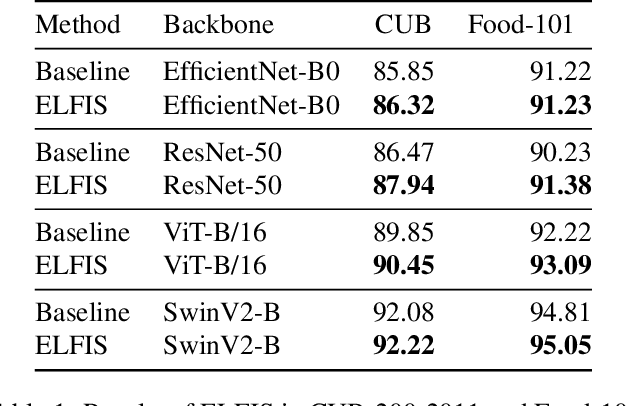
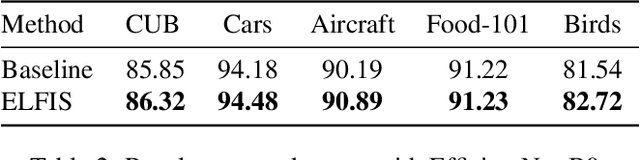

Fine-Grained Visual Recognition (FGVR) tackles the problem of distinguishing highly similar categories. One of the main approaches to FGVR, namely subset learning, tries to leverage information from existing class taxonomies to improve the performance of deep neural networks. However, these methods rely on the existence of handcrafted hierarchies that are not necessarily optimal for the models. In this paper, we propose ELFIS, an expert learning framework for FGVR that clusters categories of the dataset into meta-categories using both dataset-inherent lexical and model-specific information. A set of neural networks-based experts are trained focusing on the meta-categories and are integrated into a multi-task framework. Extensive experimentation shows improvements in the SoTA FGVR benchmarks of up to +1.3% of accuracy using both CNNs and transformer-based networks. Overall, the obtained results evidence that ELFIS can be applied on top of any classification model, enabling the obtention of SoTA results. The source code will be made public soon.
All4One: Symbiotic Neighbour Contrastive Learning via Self-Attention and Redundancy Reduction
Mar 16, 2023Nearest neighbour based methods have proved to be one of the most successful self-supervised learning (SSL) approaches due to their high generalization capabilities. However, their computational efficiency decreases when more than one neighbour is used. In this paper, we propose a novel contrastive SSL approach, which we call All4One, that reduces the distance between neighbour representations using ''centroids'' created through a self-attention mechanism. We use a Centroid Contrasting objective along with single Neighbour Contrasting and Feature Contrasting objectives. Centroids help in learning contextual information from multiple neighbours whereas the neighbour contrast enables learning representations directly from the neighbours and the feature contrast allows learning representations unique to the features. This combination enables All4One to outperform popular instance discrimination approaches by more than 1% on linear classification evaluation for popular benchmark datasets and obtains state-of-the-art (SoTA) results. Finally, we show that All4One is robust towards embedding dimensionalities and augmentations, surpassing NNCLR and Barlow Twins by more than 5% on low dimensionality and weak augmentation settings. The source code would be made available soon.