 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConjuring Positive Pairs for Efficient Unification of Representation Learning and Image Synthesis
Mar 20, 2025While representation learning and generative modeling seek to understand visual data, unifying both domains remains unexplored. Recent Unified Self-Supervised Learning (SSL) methods have started to bridge the gap between both paradigms. However, they rely solely on semantic token reconstruction, which requires an external tokenizer during training -- introducing a significant overhead. In this work, we introduce Sorcen, a novel unified SSL framework, incorporating a synergic Contrastive-Reconstruction objective. Our Contrastive objective, "Echo Contrast", leverages the generative capabilities of Sorcen, eliminating the need for additional image crops or augmentations during training. Sorcen "generates" an echo sample in the semantic token space, forming the contrastive positive pair. Sorcen operates exclusively on precomputed tokens, eliminating the need for an online token transformation during training, thereby significantly reducing computational overhead. Extensive experiments on ImageNet-1k demonstrate that Sorcen outperforms the previous Unified SSL SoTA by 0.4%, 1.48 FID, 1.76%, and 1.53% on linear probing, unconditional image generation, few-shot learning, and transfer learning, respectively, while being 60.8% more efficient. Additionally, Sorcen surpasses previous single-crop MIM SoTA in linear probing and achieves SoTA performance in unconditional image generation, highlighting significant improvements and breakthroughs in Unified SSL models.
ELFIS: Expert Learning for Fine-grained Image Recognition Using Subsets
Mar 16, 2023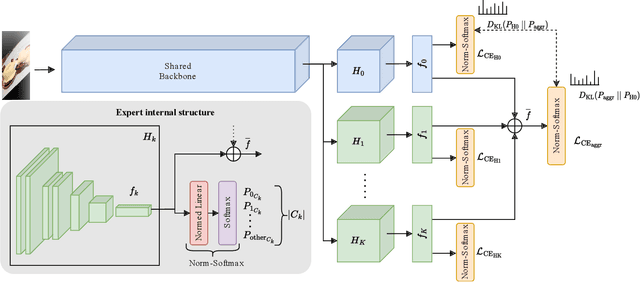
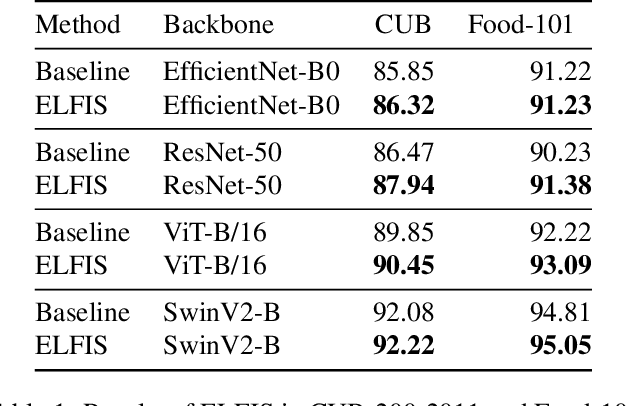
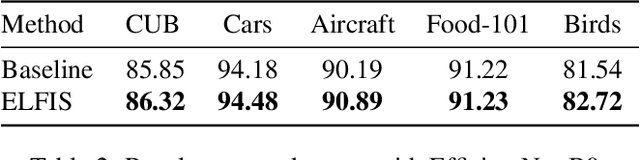

Fine-Grained Visual Recognition (FGVR) tackles the problem of distinguishing highly similar categories. One of the main approaches to FGVR, namely subset learning, tries to leverage information from existing class taxonomies to improve the performance of deep neural networks. However, these methods rely on the existence of handcrafted hierarchies that are not necessarily optimal for the models. In this paper, we propose ELFIS, an expert learning framework for FGVR that clusters categories of the dataset into meta-categories using both dataset-inherent lexical and model-specific information. A set of neural networks-based experts are trained focusing on the meta-categories and are integrated into a multi-task framework. Extensive experimentation shows improvements in the SoTA FGVR benchmarks of up to +1.3% of accuracy using both CNNs and transformer-based networks. Overall, the obtained results evidence that ELFIS can be applied on top of any classification model, enabling the obtention of SoTA results. The source code will be made public soon.
Deep learning approach to left ventricular non-compaction measurement
Nov 30, 2020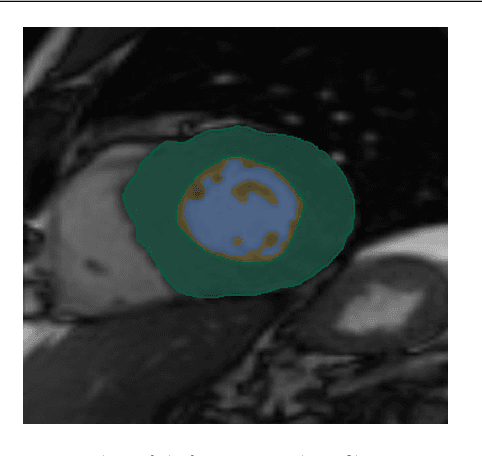
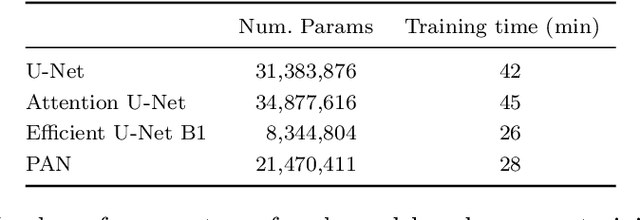


Left ventricular non-compaction (LVNC) is a rare cardiomyopathy characterized by abnormal trabeculations in the left ventricle cavity. Although traditional computer vision approaches exist for LVNC diagnosis, deep learning-based tools could not be found in the literature. In this paper, a first approach using convolutional neural networks (CNNs) is presented. Four CNNs are trained to automatically segment the compacted and trabecular areas of the left ventricle for a population of patients diagnosed with Hypertrophic cardiomyopathy. Inference results confirm that deep learning-based approaches can achieve excellent results in the diagnosis and measurement of LVNC. The two best CNNs (U-Net and Efficient U-Net B1) perform image segmentation in less than 0.2 s on a CPU and in less than 0.01 s on a GPU. Additionally, a subjective evaluation of the output images with the identified zones is performed by expert cardiologists, with a perfect visual agreement for all the slices, outperforming already existing automatic tools.