 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperFast: Instant Classification for Tabular Data
Feb 22, 2024



Training deep learning models and performing hyperparameter tuning can be computationally demanding and time-consuming. Meanwhile, traditional machine learning methods like gradient-boosting algorithms remain the preferred choice for most tabular data applications, while neural network alternatives require extensive hyperparameter tuning or work only in toy datasets under limited settings. In this paper, we introduce HyperFast, a meta-trained hypernetwork designed for instant classification of tabular data in a single forward pass. HyperFast generates a task-specific neural network tailored to an unseen dataset that can be directly used for classification inference, removing the need for training a model. We report extensive experiments with OpenML and genomic data, comparing HyperFast to competing tabular data neural networks, traditional ML methods, AutoML systems, and boosting machines. HyperFast shows highly competitive results, while being significantly faster. Additionally, our approach demonstrates robust adaptability across a variety of classification tasks with little to no fine-tuning, positioning HyperFast as a strong solution for numerous applications and rapid model deployment. HyperFast introduces a promising paradigm for fast classification, with the potential to substantially decrease the computational burden of deep learning. Our code, which offers a scikit-learn-like interface, along with the trained HyperFast model, can be found at https://github.com/AI-sandbox/HyperFast.
Sign Language Translation from Instructional Videos
Apr 14, 2023



The advances in automatic sign language translation (SLT) to spoken languages have been mostly benchmarked with datasets of limited size and restricted domains. Our work advances the state of the art by providing the first baseline results on How2Sign, a large and broad dataset. We train a Transformer over I3D video features, using the reduced BLEU as a reference metric for validation, instead of the widely used BLEU score. We report a result of 8.03 on the BLEU score, and publish the first open-source implementation of its kind to promote further advances.
Tackling Low-Resourced Sign Language Translation: UPC at WMT-SLT 22
Dec 02, 2022This paper describes the system developed at the Universitat Polit\`ecnica de Catalunya for the Workshop on Machine Translation 2022 Sign Language Translation Task, in particular, for the sign-to-text direction. We use a Transformer model implemented with the Fairseq modeling toolkit. We have experimented with the vocabulary size, data augmentation techniques and pretraining the model with the PHOENIX-14T dataset. Our system obtains 0.50 BLEU score for the test set, improving the organizers' baseline by 0.38 BLEU. We remark the poor results for both the baseline and our system, and thus, the unreliability of our findings.
Model Zoos: A Dataset of Diverse Populations of Neural Network Models
Sep 29, 2022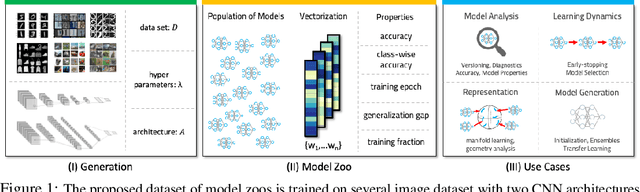
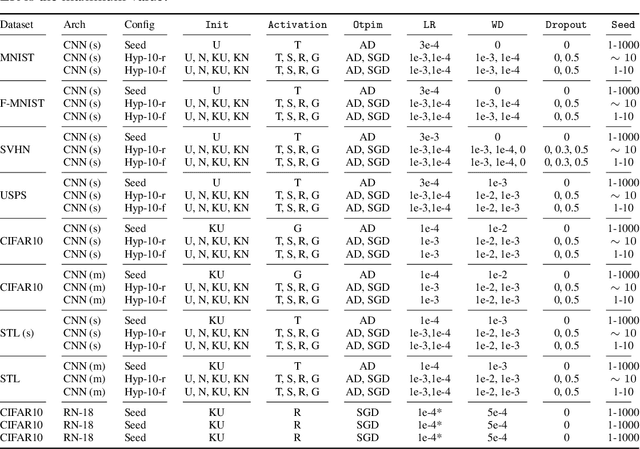
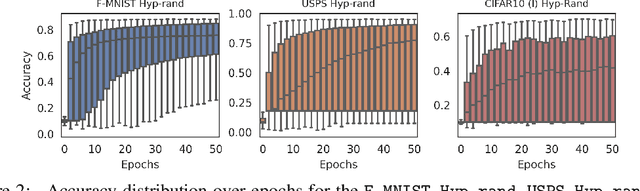
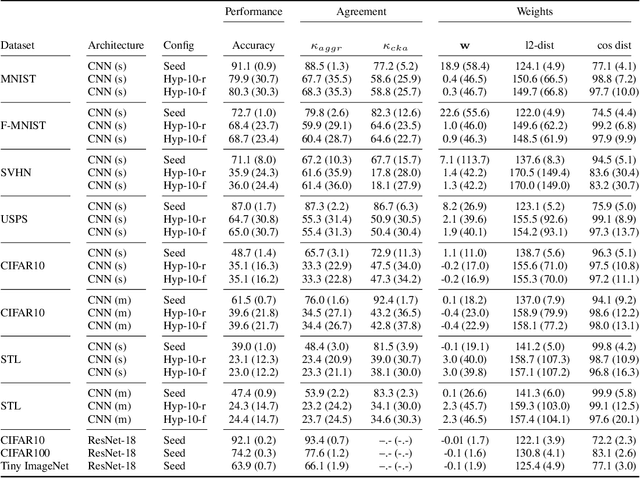
In the last years, neural networks (NN) have evolved from laboratory environments to the state-of-the-art for many real-world problems. It was shown that NN models (i.e., their weights and biases) evolve on unique trajectories in weight space during training. Following, a population of such neural network models (referred to as model zoo) would form structures in weight space. We think that the geometry, curvature and smoothness of these structures contain information about the state of training and can reveal latent properties of individual models. With such model zoos, one could investigate novel approaches for (i) model analysis, (ii) discover unknown learning dynamics, (iii) learn rich representations of such populations, or (iv) exploit the model zoos for generative modelling of NN weights and biases. Unfortunately, the lack of standardized model zoos and available benchmarks significantly increases the friction for further research about populations of NNs. With this work, we publish a novel dataset of model zoos containing systematically generated and diverse populations of NN models for further research. In total the proposed model zoo dataset is based on eight image datasets, consists of 27 model zoos trained with varying hyperparameter combinations and includes 50'360 unique NN models as well as their sparsified twins, resulting in over 3'844'360 collected model states. Additionally, to the model zoo data we provide an in-depth analysis of the zoos and provide benchmarks for multiple downstream tasks. The dataset can be found at www.modelzoos.cc.
Hyper-Representations as Generative Models: Sampling Unseen Neural Network Weights
Sep 29, 2022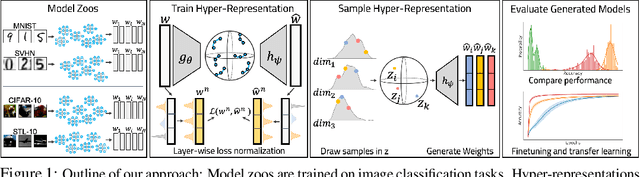
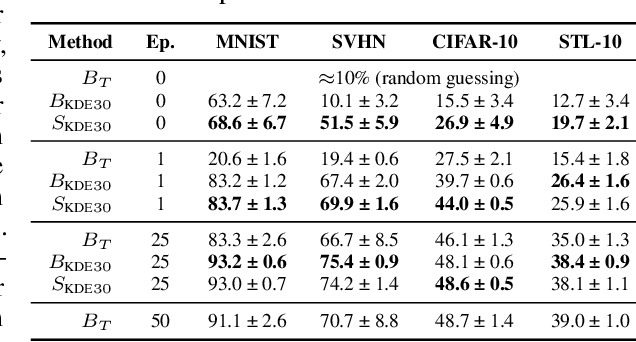
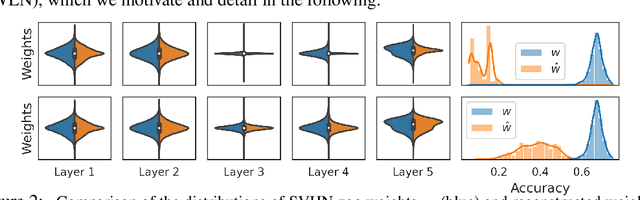
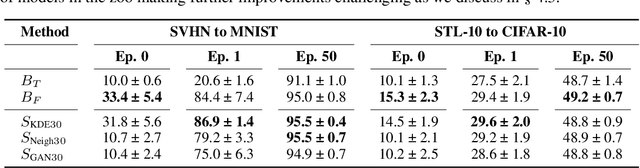
Learning representations of neural network weights given a model zoo is an emerging and challenging area with many potential applications from model inspection, to neural architecture search or knowledge distillation. Recently, an autoencoder trained on a model zoo was able to learn a hyper-representation, which captures intrinsic and extrinsic properties of the models in the zoo. In this work, we extend hyper-representations for generative use to sample new model weights. We propose layer-wise loss normalization which we demonstrate is key to generate high-performing models and several sampling methods based on the topology of hyper-representations. The models generated using our methods are diverse, performant and capable to outperform strong baselines as evaluated on several downstream tasks: initialization, ensemble sampling and transfer learning. Our results indicate the potential of knowledge aggregation from model zoos to new models via hyper-representations thereby paving the avenue for novel research directions.
Hyper-Representations for Pre-Training and Transfer Learning
Jul 22, 2022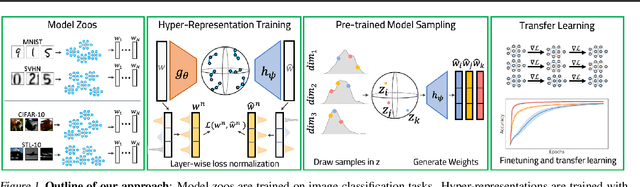
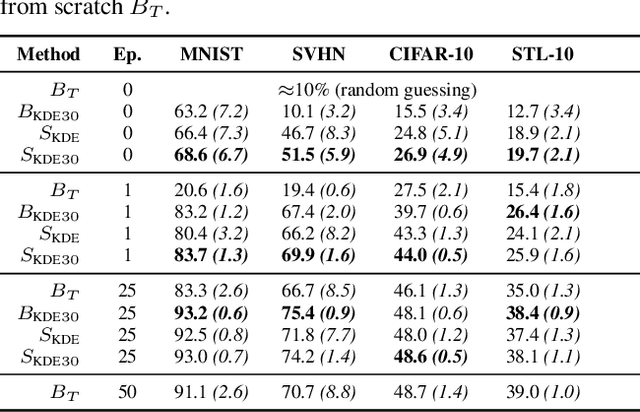
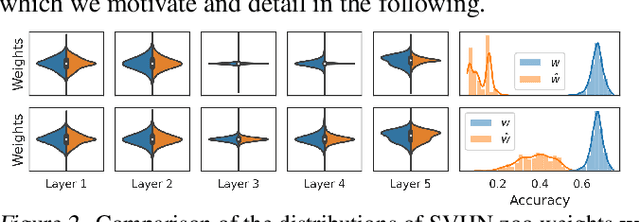
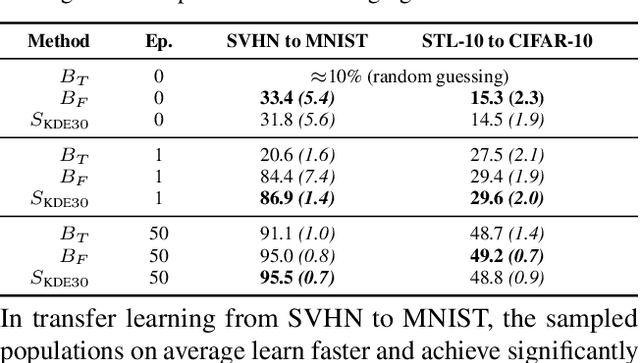
Learning representations of neural network weights given a model zoo is an emerging and challenging area with many potential applications from model inspection, to neural architecture search or knowledge distillation. Recently, an autoencoder trained on a model zoo was able to learn a hyper-representation, which captures intrinsic and extrinsic properties of the models in the zoo. In this work, we extend hyper-representations for generative use to sample new model weights as pre-training. We propose layer-wise loss normalization which we demonstrate is key to generate high-performing models and a sampling method based on the empirical density of hyper-representations. The models generated using our methods are diverse, performant and capable to outperform conventional baselines for transfer learning. Our results indicate the potential of knowledge aggregation from model zoos to new models via hyper-representations thereby paving the avenue for novel research directions.
Sign Language Video Retrieval with Free-Form Textual Queries
Jan 07, 2022

Systems that can efficiently search collections of sign language videos have been highlighted as a useful application of sign language technology. However, the problem of searching videos beyond individual keywords has received limited attention in the literature. To address this gap, in this work we introduce the task of sign language retrieval with free-form textual queries: given a written query (e.g., a sentence) and a large collection of sign language videos, the objective is to find the signing video in the collection that best matches the written query. We propose to tackle this task by learning cross-modal embeddings on the recently introduced large-scale How2Sign dataset of American Sign Language (ASL). We identify that a key bottleneck in the performance of the system is the quality of the sign video embedding which suffers from a scarcity of labeled training data. We, therefore, propose SPOT-ALIGN, a framework for interleaving iterative rounds of sign spotting and feature alignment to expand the scope and scale of available training data. We validate the effectiveness of SPOT-ALIGN for learning a robust sign video embedding through improvements in both sign recognition and the proposed video retrieval task.
Multiple Object Tracking with Mixture Density Networks for Trajectory Estimation
Jun 22, 2021
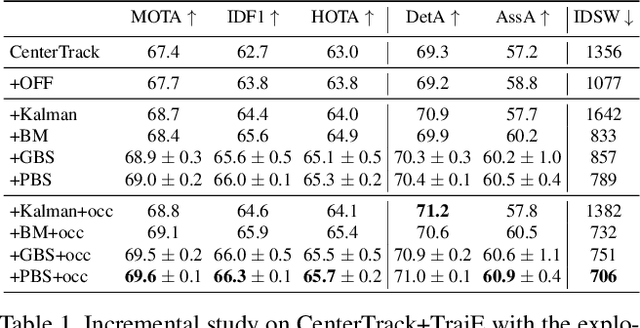

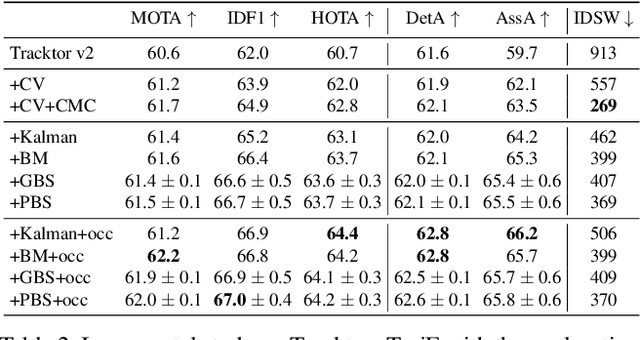
Multiple object tracking faces several challenges that may be alleviated with trajectory information. Knowing the posterior locations of an object helps disambiguating and solving situations such as occlusions, re-identification, and identity switching. In this work, we show that trajectory estimation can become a key factor for tracking, and present TrajE, a trajectory estimator based on recurrent mixture density networks, as a generic module that can be added to existing object trackers. To provide several trajectory hypotheses, our method uses beam search. Also, relying on the same estimated trajectory, we propose to reconstruct a track after an occlusion occurs. We integrate TrajE into two state of the art tracking algorithms, CenterTrack [63] and Tracktor [3]. Their respective performances in the MOTChallenge 2017 test set are boosted 6.3 and 0.3 points in MOTA score, and 1.8 and 3.1 in IDF1, setting a new state of the art for the CenterTrack+TrajE configuration
Curriculum Learning for Recurrent Video Object Segmentation
Aug 15, 2020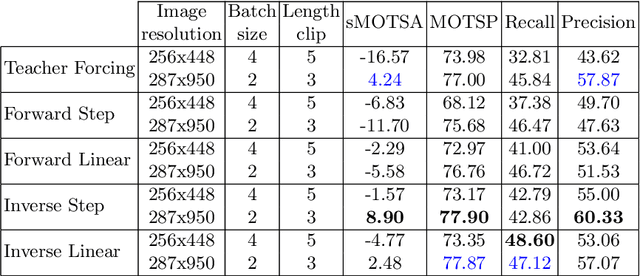

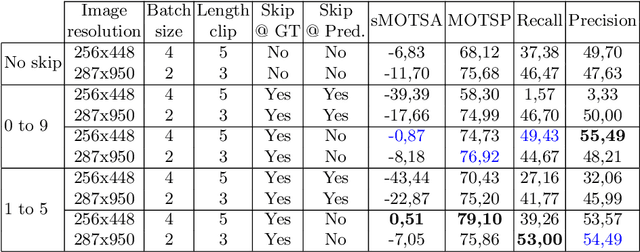
Video object segmentation can be understood as a sequence-to-sequence task that can benefit from the curriculum learning strategies for better and faster training of deep neural networks. This work explores different schedule sampling and frame skipping variations to significantly improve the performance of a recurrent architecture. Our results on the car class of the KITTI-MOTS challenge indicate that, surprisingly, an inverse schedule sampling is a better option than a classic forward one. Also, that a progressive skipping of frames during training is beneficial, but only when training with the ground truth masks instead of the predicted ones. Source code and trained models are available at http://imatge-upc.github.io/rvos-mots/.
Assessing Knee OA Severity with CNN attention-based end-to-end architectures
Aug 23, 2019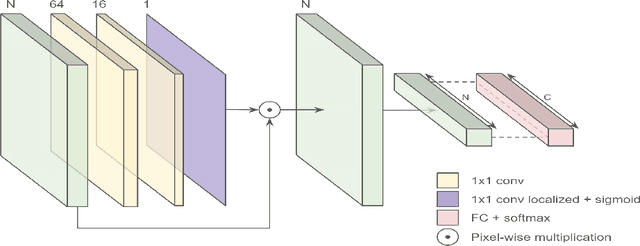
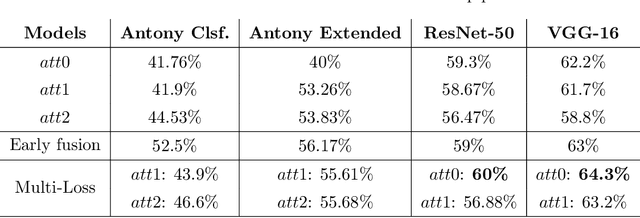
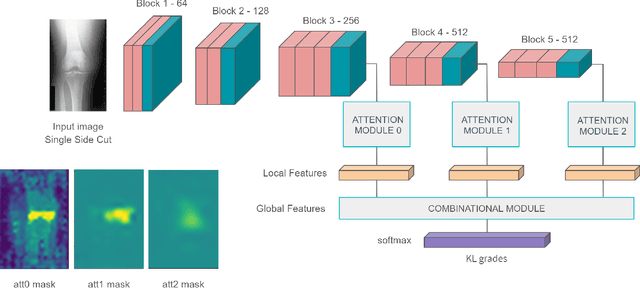

This work proposes a novel end-to-end convolutional neural network (CNN) architecture to automatically quantify the severity of knee osteoarthritis (OA) using X-Ray images, which incorporates trainable attention modules acting as unsupervised fine-grained detectors of the region of interest (ROI). The proposed attention modules can be applied at different levels and scales across any CNN pipeline helping the network to learn relevant attention patterns over the most informative parts of the image at different resolutions. We test the proposed attention mechanism on existing state-of-the-art CNN architectures as our base models, achieving promising results on the benchmark knee OA datasets from the osteoarthritis initiative (OAI) and multicenter osteoarthritis study (MOST). All code from our experiments will be publicly available on the github repository: https://github.com/marc-gorriz/KneeOA-CNNAttention
* Proceedings of the 2nd International Conference on Medical Imaging with Deep Learning