 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Language-Agnosticity in Function Vectors: A Case Study in Machine Translation
Apr 21, 2026Function vectors (FVs) are vector representations of tasks extracted from model activations during in-context learning. While prior work has shown that multilingual model representations can be language-agnostic, it remains unclear whether the same holds for function vectors. We study whether FVs exhibit language-agnosticity, using machine translation as a case study. Across three decoder-only multilingual LLMs, we find that translation FVs extracted from a single English$\rightarrow$Target direction transfer to other target languages, consistently improving the rank of correct translation tokens across multiple unseen languages. Ablation results show that removing the FV degrades translation across languages with limited impact on unrelated tasks. We further show that base-model FVs transfer to instruction-tuned variants and partially generalize from word-level to sentence-level translation.
Hearing to Translate: The Effectiveness of Speech Modality Integration into LLMs
Dec 24, 2025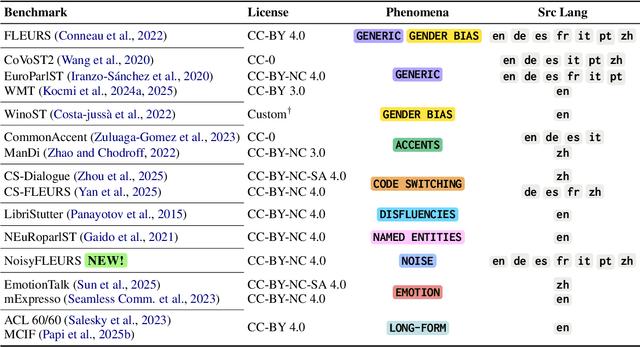
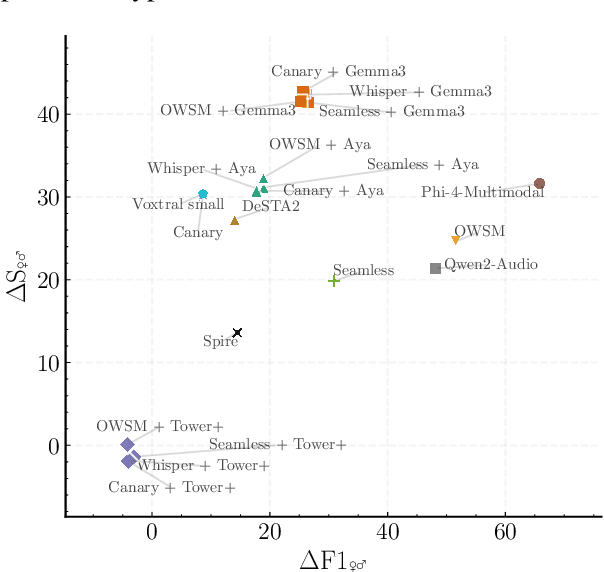
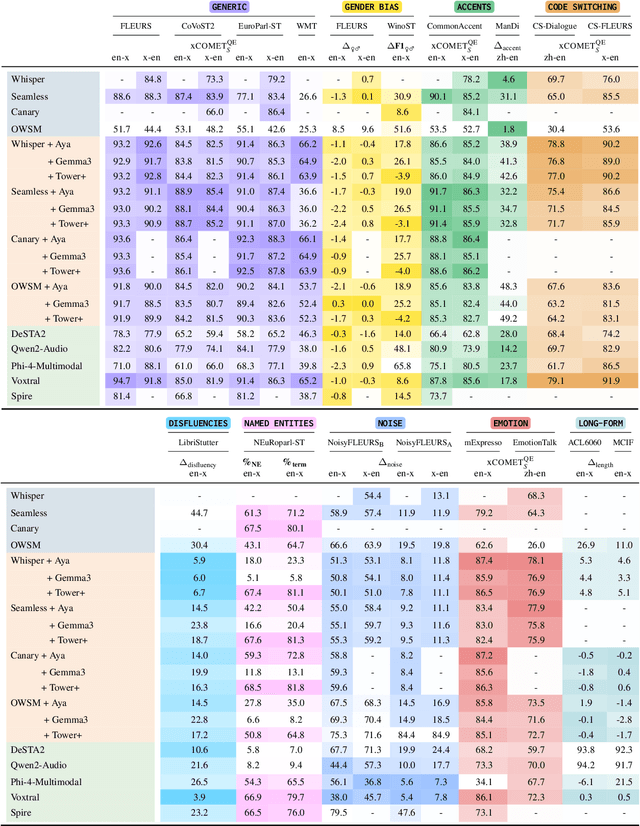
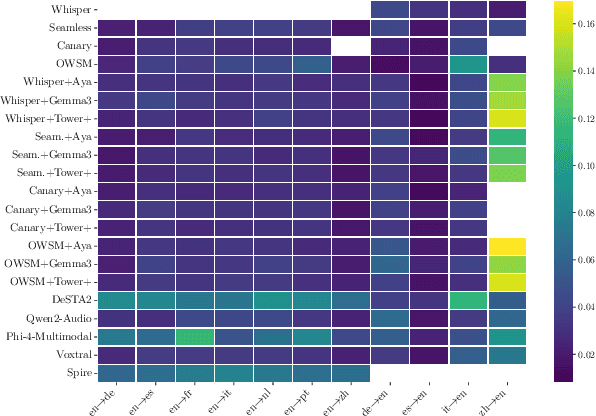
As Large Language Models (LLMs) expand beyond text, integrating speech as a native modality has given rise to SpeechLLMs, which aim to translate spoken language directly, thereby bypassing traditional transcription-based pipelines. Whether this integration improves speech-to-text translation quality over established cascaded architectures, however, remains an open question. We present Hearing to Translate, the first comprehensive test suite rigorously benchmarking 5 state-of-the-art SpeechLLMs against 16 strong direct and cascade systems that couple leading speech foundation models (SFM), with multilingual LLMs. Our analysis spans 16 benchmarks, 13 language pairs, and 9 challenging conditions, including disfluent, noisy, and long-form speech. Across this extensive evaluation, we find that cascaded systems remain the most reliable overall, while current SpeechLLMs only match cascades in selected settings and SFMs lag behind both, highlighting that integrating an LLM, either within the model or in a pipeline, is essential for high-quality speech translation.
Speech-to-Text Translation with Phoneme-Augmented CoT: Enhancing Cross-Lingual Transfer in Low-Resource Scenarios
May 30, 2025We propose a Speech-to-Text Translation (S2TT) approach that integrates phoneme representations into a Chain-of-Thought (CoT) framework to improve translation in low-resource and zero-resource settings. By introducing phoneme recognition as an intermediate step, we enhance cross-lingual transfer, enabling translation even for languages with no labeled speech data. Our system builds on a multilingual LLM, which we extend to process speech and phonemes. Training follows a curriculum learning strategy that progressively introduces more complex tasks. Experiments on multilingual S2TT benchmarks show that phoneme-augmented CoT improves translation quality in low-resource conditions and enables zero-resource translation, while slightly impacting high-resource performance. Despite this trade-off, our findings demonstrate that phoneme-based CoT is a promising step toward making S2TT more accessible across diverse languages.
Unveiling the Role of Pretraining in Direct Speech Translation
Sep 26, 2024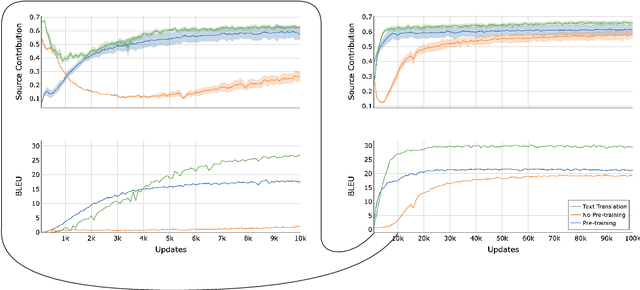
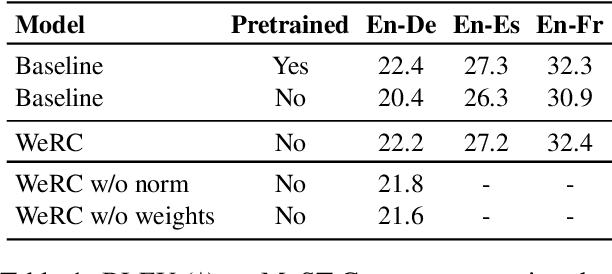
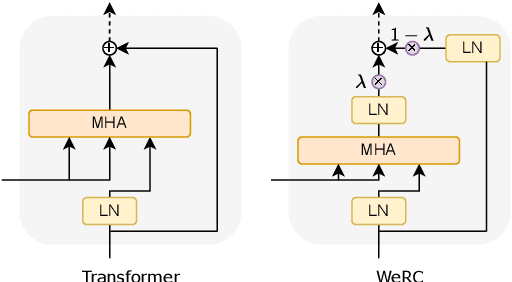
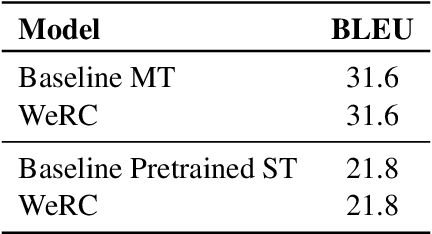
Direct speech-to-text translation systems encounter an important drawback in data scarcity. A common solution consists on pretraining the encoder on automatic speech recognition, hence losing efficiency in the training process. In this study, we compare the training dynamics of a system using a pretrained encoder, the conventional approach, and one trained from scratch. We observe that, throughout the training, the randomly initialized model struggles to incorporate information from the speech inputs for its predictions. Hence, we hypothesize that this issue stems from the difficulty of effectively training an encoder for direct speech translation. While a model trained from scratch needs to learn acoustic and semantic modeling simultaneously, a pretrained one can just focus on the latter. Based on these findings, we propose a subtle change in the decoder cross-attention to integrate source information from earlier steps in training. We show that with this change, the model trained from scratch can achieve comparable performance to the pretrained one, while reducing the training time.
Single-stage TTS with Masked Audio Token Modeling and Semantic Knowledge Distillation
Sep 17, 2024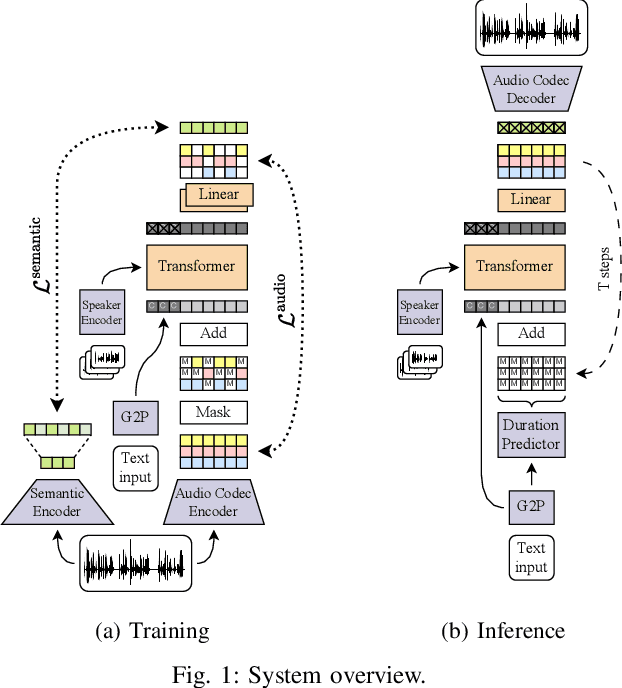
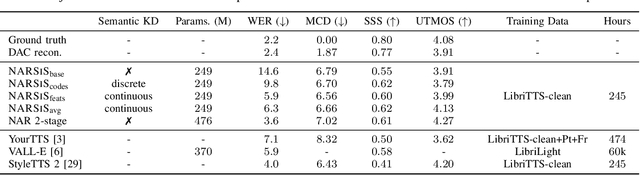
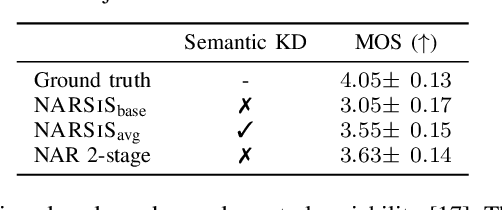
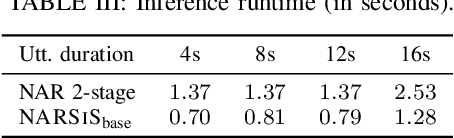
Audio token modeling has become a powerful framework for speech synthesis, with two-stage approaches employing semantic tokens remaining prevalent. In this paper, we aim to simplify this process by introducing a semantic knowledge distillation method that enables high-quality speech generation in a single stage. Our proposed model improves speech quality, intelligibility, and speaker similarity compared to a single-stage baseline. Although two-stage systems still lead in intelligibility, our model significantly narrows the gap while delivering comparable speech quality. These findings showcase the potential of single-stage models to achieve efficient, high-quality TTS with a more compact and streamlined architecture.
Pushing the Limits of Zero-shot End-to-End Speech Translation
Feb 16, 2024Data scarcity and the modality gap between the speech and text modalities are two major obstacles of end-to-end Speech Translation (ST) systems, thus hindering their performance. Prior work has attempted to mitigate these challenges by leveraging external MT data and optimizing distance metrics that bring closer the speech-text representations. However, achieving competitive results typically requires some ST data. For this reason, we introduce ZeroSwot, a method for zero-shot ST that bridges the modality gap without any paired ST data. Leveraging a novel CTC compression and Optimal Transport, we train a speech encoder using only ASR data, to align with the representation space of a massively multilingual MT model. The speech encoder seamlessly integrates with the MT model at inference, enabling direct translation from speech to text, across all languages supported by the MT model. Our experiments show that we can effectively close the modality gap without ST data, while our results on MuST-C and CoVoST demonstrate our method's superiority over not only previous zero-shot models, but also supervised ones, achieving state-of-the-art results.
SpeechAlign: a Framework for Speech Translation Alignment Evaluation
Sep 20, 2023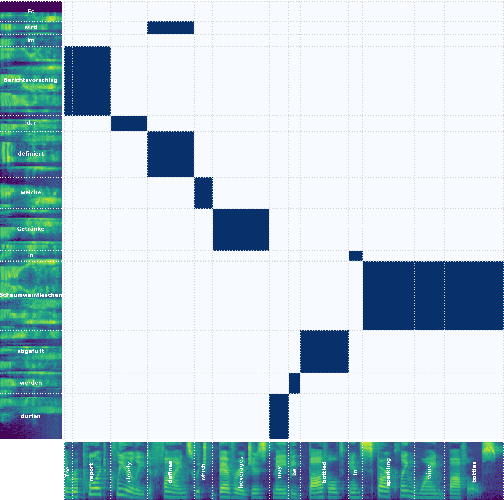

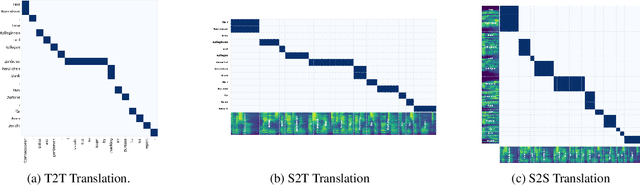
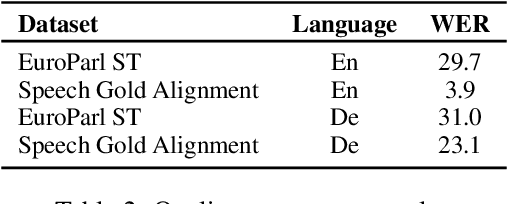
Speech-to-Speech and Speech-to-Text translation are currently dynamic areas of research. To contribute to these fields, we present SpeechAlign, a framework to evaluate the underexplored field of source-target alignment in speech models. Our framework has two core components. First, to tackle the absence of suitable evaluation datasets, we introduce the Speech Gold Alignment dataset, built upon a English-German text translation gold alignment dataset. Secondly, we introduce two novel metrics, Speech Alignment Error Rate (SAER) and Time-weighted Speech Alignment Error Rate (TW-SAER), to evaluate alignment quality in speech models. By publishing SpeechAlign we provide an accessible evaluation framework for model assessment, and we employ it to benchmark open-source Speech Translation models.
Speech Translation with Foundation Models and Optimal Transport: UPC at IWSLT23
Jun 02, 2023This paper describes the submission of the UPC Machine Translation group to the IWSLT 2023 Offline Speech Translation task. Our Speech Translation systems utilize foundation models for speech (wav2vec 2.0) and text (mBART50). We incorporate a Siamese pretraining step of the speech and text encoders with CTC and Optimal Transport, to adapt the speech representations to the space of the text model, thus maximizing transfer learning from MT. After this pretraining, we fine-tune our system end-to-end on ST, with Cross Entropy and Knowledge Distillation. Apart from the available ST corpora, we create synthetic data with SegAugment to better adapt our models to the custom segmentations of the IWSLT test sets. Our best single model obtains 31.2 BLEU points on MuST-C tst-COMMON, 29.8 points on IWLST.tst2020 and 33.4 points on the newly released IWSLT.ACLdev2023.
Explaining How Transformers Use Context to Build Predictions
May 21, 2023



Language Generation Models produce words based on the previous context. Although existing methods offer input attributions as explanations for a model's prediction, it is still unclear how prior words affect the model's decision throughout the layers. In this work, we leverage recent advances in explainability of the Transformer and present a procedure to analyze models for language generation. Using contrastive examples, we compare the alignment of our explanations with evidence of the linguistic phenomena, and show that our method consistently aligns better than gradient-based and perturbation-based baselines. Then, we investigate the role of MLPs inside the Transformer and show that they learn features that help the model predict words that are grammatically acceptable. Lastly, we apply our method to Neural Machine Translation models, and demonstrate that they generate human-like source-target alignments for building predictions.
Sign Language Translation from Instructional Videos
Apr 14, 2023



The advances in automatic sign language translation (SLT) to spoken languages have been mostly benchmarked with datasets of limited size and restricted domains. Our work advances the state of the art by providing the first baseline results on How2Sign, a large and broad dataset. We train a Transformer over I3D video features, using the reduced BLEU as a reference metric for validation, instead of the widely used BLEU score. We report a result of 8.03 on the BLEU score, and publish the first open-source implementation of its kind to promote further advances.