 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoom Impulse Response Generation Conditioned on Acoustic Parameters
Jul 16, 2025The generation of room impulse responses (RIRs) using deep neural networks has attracted growing research interest due to its applications in virtual and augmented reality, audio postproduction, and related fields. Most existing approaches condition generative models on physical descriptions of a room, such as its size, shape, and surface materials. However, this reliance on geometric information limits their usability in scenarios where the room layout is unknown or when perceptual realism (how a space sounds to a listener) is more important than strict physical accuracy. In this study, we propose an alternative strategy: conditioning RIR generation directly on a set of RIR acoustic parameters. These parameters include various measures of reverberation time and direct sound to reverberation ratio, both broadband and bandwise. By specifying how the space should sound instead of how it should look, our method enables more flexible and perceptually driven RIR generation. We explore both autoregressive and non-autoregressive generative models operating in the Descript Audio Codec domain, using either discrete token sequences or continuous embeddings. Specifically, we have selected four models to evaluate: an autoregressive transformer, the MaskGIT model, a flow matching model, and a classifier-based approach. Objective and subjective evaluations are performed to compare these methods with state-of-the-art alternatives. Results show that the proposed models match or outperform state-of-the-art alternatives, with the MaskGIT model achieving the best performance.
Single-stage TTS with Masked Audio Token Modeling and Semantic Knowledge Distillation
Sep 17, 2024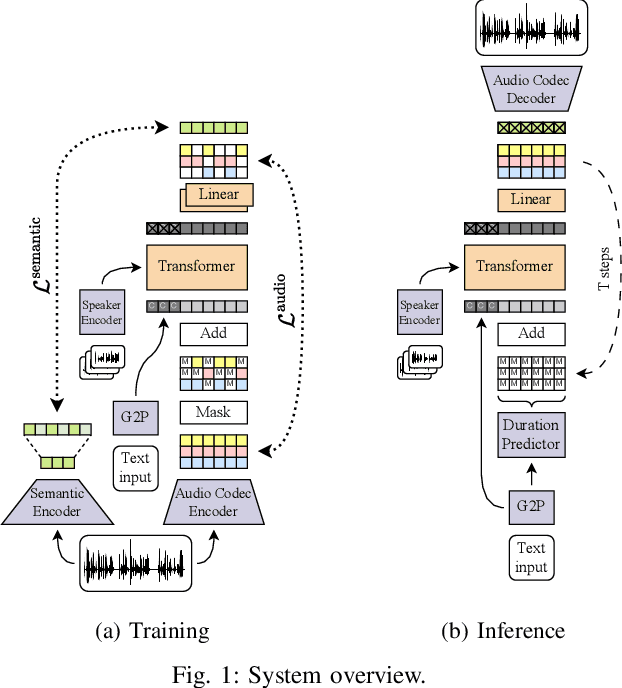
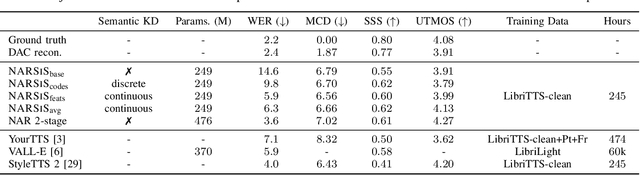
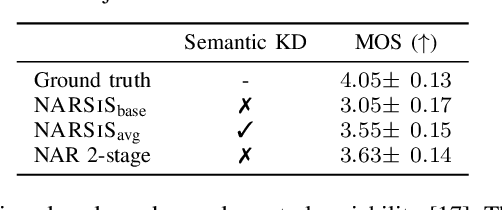
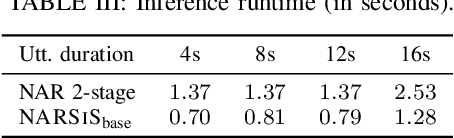
Audio token modeling has become a powerful framework for speech synthesis, with two-stage approaches employing semantic tokens remaining prevalent. In this paper, we aim to simplify this process by introducing a semantic knowledge distillation method that enables high-quality speech generation in a single stage. Our proposed model improves speech quality, intelligibility, and speaker similarity compared to a single-stage baseline. Although two-stage systems still lead in intelligibility, our model significantly narrows the gap while delivering comparable speech quality. These findings showcase the potential of single-stage models to achieve efficient, high-quality TTS with a more compact and streamlined architecture.
Masked Generative Video-to-Audio Transformers with Enhanced Synchronicity
Jul 15, 2024Video-to-audio (V2A) generation leverages visual-only video features to render plausible sounds that match the scene. Importantly, the generated sound onsets should match the visual actions that are aligned with them, otherwise unnatural synchronization artifacts arise. Recent works have explored the progression of conditioning sound generators on still images and then video features, focusing on quality and semantic matching while ignoring synchronization, or by sacrificing some amount of quality to focus on improving synchronization only. In this work, we propose a V2A generative model, named MaskVAT, that interconnects a full-band high-quality general audio codec with a sequence-to-sequence masked generative model. This combination allows modeling both high audio quality, semantic matching, and temporal synchronicity at the same time. Our results show that, by combining a high-quality codec with the proper pre-trained audio-visual features and a sequence-to-sequence parallel structure, we are able to yield highly synchronized results on one hand, whilst being competitive with the state of the art of non-codec generative audio models. Sample videos and generated audios are available at https://maskvat.github.io .
Sequential Contrastive Audio-Visual Learning
Jul 08, 2024



Contrastive learning has emerged as a powerful technique in audio-visual representation learning, leveraging the natural co-occurrence of audio and visual modalities in extensive web-scale video datasets to achieve significant advancements. However, conventional contrastive audio-visual learning methodologies often rely on aggregated representations derived through temporal aggregation, which neglects the intrinsic sequential nature of the data. This oversight raises concerns regarding the ability of standard approaches to capture and utilize fine-grained information within sequences, information that is vital for distinguishing between semantically similar yet distinct examples. In response to this limitation, we propose sequential contrastive audio-visual learning (SCAV), which contrasts examples based on their non-aggregated representation space using sequential distances. Retrieval experiments with the VGGSound and Music datasets demonstrate the effectiveness of SCAV, showing 2-3x relative improvements against traditional aggregation-based contrastive learning and other methods from the literature. We also show that models trained with SCAV exhibit a high degree of flexibility regarding the metric employed for retrieval, allowing them to operate on a spectrum of efficiency-accuracy trade-offs, potentially making them applicable in multiple scenarios, from small- to large-scale retrieval.
Full-band General Audio Synthesis with Score-based Diffusion
Oct 26, 2022Recent works have shown the capability of deep generative models to tackle general audio synthesis from a single label, producing a variety of impulsive, tonal, and environmental sounds. Such models operate on band-limited signals and, as a result of an autoregressive approach, they are typically conformed by pre-trained latent encoders and/or several cascaded modules. In this work, we propose a diffusion-based generative model for general audio synthesis, named DAG, which deals with full-band signals end-to-end in the waveform domain. Results show the superiority of DAG over existing label-conditioned generators in terms of both quality and diversity. More specifically, when compared to the state of the art, the band-limited and full-band versions of DAG achieve relative improvements that go up to 40 and 65%, respectively. We believe DAG is flexible enough to accommodate different conditioning schemas while providing good quality synthesis.