 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Attention Shapes Emotion: A Comparative Study of Attention Mechanisms for Speech Emotion Recognition
Mar 16, 2026Speech Emotion Recognition (SER) plays a key role in advancing human-computer interaction. Attention mechanisms have become the dominant approach for modeling emotional speech due to their ability to capture long-range dependencies and emphasize salient information. However, standard self-attention suffers from quadratic computational and memory complexity, limiting its scalability. In this work, we present a systematic benchmark of optimized attention mechanisms for SER, including RetNet, LightNet, GSA, FoX, and KDA. Experiments on both MSP-Podcast benchmark versions show that while standard self-attention achieves the strongest recognition performance across test sets, efficient attention variants dramatically improve scalability, reducing inference latency and memory usage by up to an order of magnitude. These results highlight a critical trade-off between accuracy and efficiency, providing practical insights for designing scalable SER systems.
Quantifying Cross-Lingual Transfer in Paralinguistic Speech Tasks
Mar 09, 2026Paralinguistic speech tasks are often considered relatively language-agnostic, as they rely on extralinguistic acoustic cues rather than lexical content. However, prior studies report performance degradation under cross-lingual conditions, indicating non-negligible language dependence. Still, these studies typically focus on isolated language pairs or task-specific settings, limiting comparability and preventing a systematic assessment of task-level language dependence. We introduce the Cross-Lingual Transfer Matrix (CLTM), a systematic method to quantify cross-lingual interactions between pairs of languages within a given task. We apply the CLTM to two paralinguistic tasks, gender identification and speaker verification, using a multilingual HuBERT-based encoder, to analyze how donor-language data affects target-language performance during fine-tuning. Our results reveal distinct transfer patterns across tasks and languages, reflecting systematic, language-dependent effects.
Bootstrapping Audiovisual Speech Recognition in Zero-AV-Resource Scenarios with Synthetic Visual Data
Mar 09, 2026Audiovisual speech recognition (AVSR) combines acoustic and visual cues to improve transcription robustness under challenging conditions but remains out of reach for most under-resourced languages due to the lack of labeled video corpora for training. We propose a zero-AV-resource AVSR framework that relies on synthetic visual streams generated by lip-syncing static facial images with real audio. We first evaluate synthetic visual augmentation on Spanish benchmarks, then apply it to Catalan, a language with no annotated audiovisual corpora. We synthesize over 700 hours of talking-head video and fine-tune a pre-trained AV-HuBERT model. On a manually annotated Catalan benchmark, our model achieves near state-of-the-art performance with much fewer parameters and training data, outperforms an identically trained audio-only baseline, and preserves multimodal advantages in noise. Scalable synthetic video thus offers a viable substitute for real recordings in zero-AV-resource AVSR.
Speech-to-Text Translation with Phoneme-Augmented CoT: Enhancing Cross-Lingual Transfer in Low-Resource Scenarios
May 30, 2025We propose a Speech-to-Text Translation (S2TT) approach that integrates phoneme representations into a Chain-of-Thought (CoT) framework to improve translation in low-resource and zero-resource settings. By introducing phoneme recognition as an intermediate step, we enhance cross-lingual transfer, enabling translation even for languages with no labeled speech data. Our system builds on a multilingual LLM, which we extend to process speech and phonemes. Training follows a curriculum learning strategy that progressively introduces more complex tasks. Experiments on multilingual S2TT benchmarks show that phoneme-augmented CoT improves translation quality in low-resource conditions and enables zero-resource translation, while slightly impacting high-resource performance. Despite this trade-off, our findings demonstrate that phoneme-based CoT is a promising step toward making S2TT more accessible across diverse languages.
Breaking Language Barriers in Visual Language Models via Multilingual Textual Regularization
Mar 28, 2025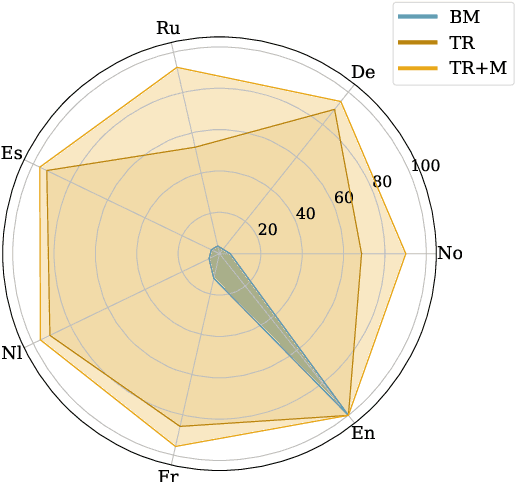
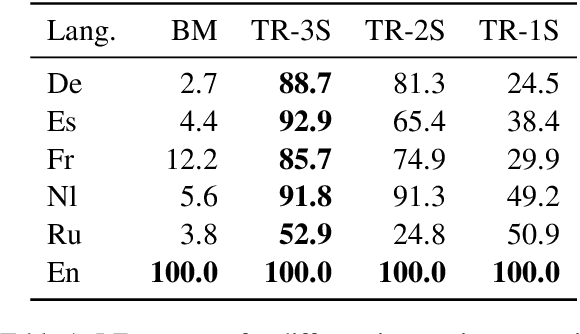
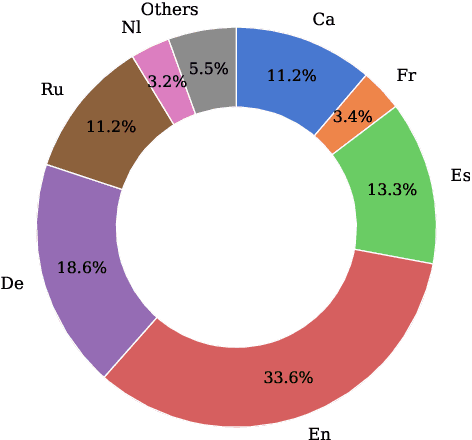
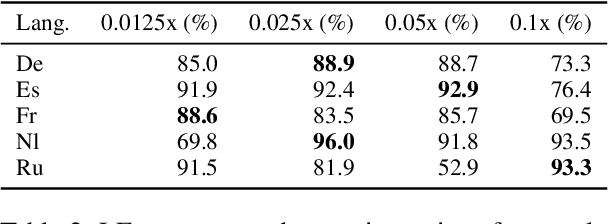
Rapid advancements in Visual Language Models (VLMs) have transformed multimodal understanding but are often constrained by generating English responses regardless of the input language. This phenomenon has been termed as Image-induced Fidelity Loss (IFL) and stems from limited multimodal multilingual training data. To address this, we propose a continuous multilingual integration strategy that injects text-only multilingual data during visual instruction tuning, preserving the language model's original multilingual capabilities. Extensive evaluations demonstrate that our approach significantly improves linguistic fidelity across languages without degradation in visual performance. We also explore model merging, which improves language fidelity but comes at the cost of visual performance. In contrast, our core method achieves robust multilingual alignment without trade-offs, offering a scalable and effective path to mitigating IFL for global VLM adoption.
Mass-Editing Memory with Attention in Transformers: A cross-lingual exploration of knowledge
Feb 04, 2025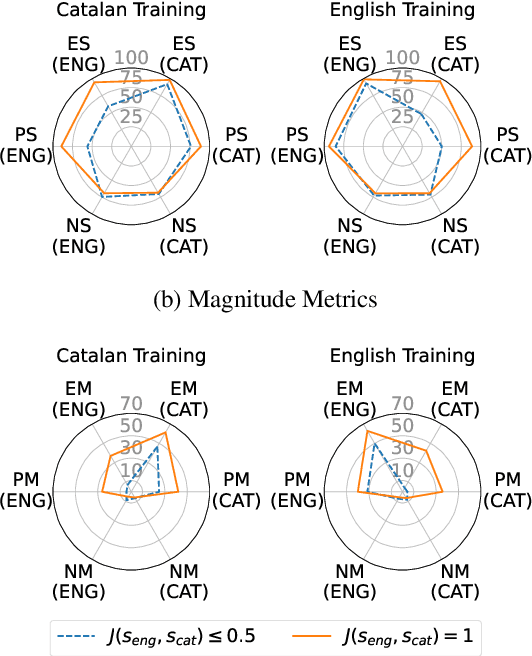
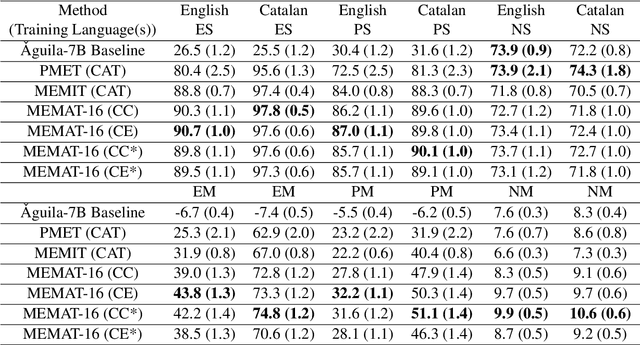
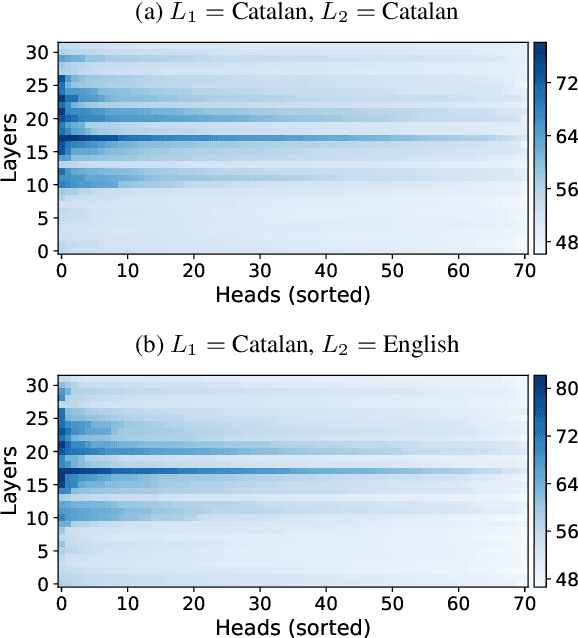
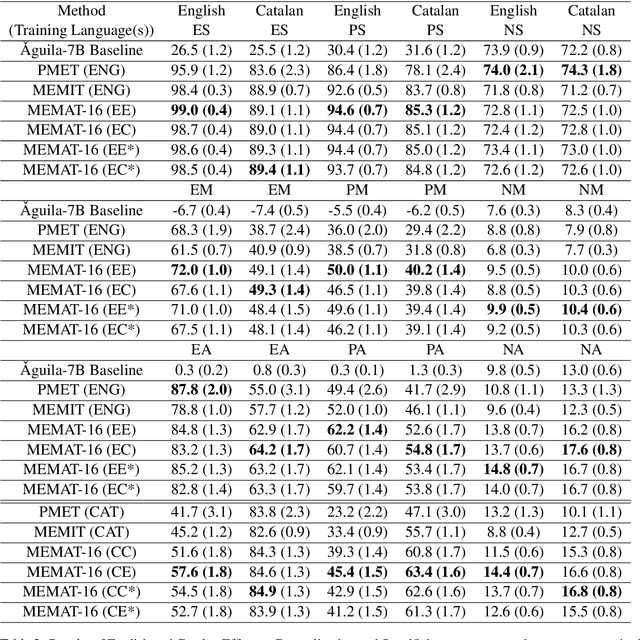
Recent research has explored methods for updating and modifying factual knowledge in large language models, often focusing on specific multi-layer perceptron blocks. This study expands on this work by examining the effectiveness of existing knowledge editing methods across languages and delving into the role of attention mechanisms in this process. Drawing from the insights gained, we propose Mass-Editing Memory with Attention in Transformers (MEMAT), a method that achieves significant improvements in all metrics while requiring minimal parameter modifications. MEMAT delivers a remarkable 10% increase in magnitude metrics, benefits languages not included in the training data and also demonstrates a high degree of portability. Our code and data are at https://github.com/dtamayo-nlp/MEMAT.
Language Modelling for Speaker Diarization in Telephonic Interviews
Jan 28, 2025



The aim of this paper is to investigate the benefit of combining both language and acoustic modelling for speaker diarization. Although conventional systems only use acoustic features, in some scenarios linguistic data contain high discriminative speaker information, even more reliable than the acoustic ones. In this study we analyze how an appropriate fusion of both kind of features is able to obtain good results in these cases. The proposed system is based on an iterative algorithm where a LSTM network is used as a speaker classifier. The network is fed with character-level word embeddings and a GMM based acoustic score created with the output labels from previous iterations. The presented algorithm has been evaluated in a Call-Center database, which is composed of telephone interview audios. The combination of acoustic features and linguistic content shows a 84.29% improvement in terms of a word-level DER as compared to a HMM/VB baseline system. The results of this study confirms that linguistic content can be efficiently used for some speaker recognition tasks.
On the Use of Audio to Improve Dialogue Policies
Oct 17, 2024


With the significant progress of speech technologies, spoken goal-oriented dialogue systems are becoming increasingly popular. One of the main modules of a dialogue system is typically the dialogue policy, which is responsible for determining system actions. This component usually relies only on audio transcriptions, being strongly dependent on their quality and ignoring very important extralinguistic information embedded in the user's speech. In this paper, we propose new architectures to add audio information by combining speech and text embeddings using a Double Multi-Head Attention component. Our experiments show that audio embedding-aware dialogue policies outperform text-based ones, particularly in noisy transcription scenarios, and that how text and audio embeddings are combined is crucial to improve performance. We obtained a 9.8% relative improvement in the User Request Score compared to an only-text-based dialogue system on the DSTC2 dataset.
BSC-UPC at EmoSPeech-IberLEF2024: Attention Pooling for Emotion Recognition
Jul 17, 2024The domain of speech emotion recognition (SER) has persistently been a frontier within the landscape of machine learning. It is an active field that has been revolutionized in the last few decades and whose implementations are remarkable in multiple applications that could affect daily life. Consequently, the Iberian Languages Evaluation Forum (IberLEF) of 2024 held a competitive challenge to leverage the SER results with a Spanish corpus. This paper presents the approach followed with the goal of participating in this competition. The main architecture consists of different pre-trained speech and text models to extract features from both modalities, utilizing an attention pooling mechanism. The proposed system has achieved the first position in the challenge with an 86.69% in Macro F1-Score.
Double Multi-Head Attention Multimodal System for Odyssey 2024 Speech Emotion Recognition Challenge
Jun 15, 2024



As computer-based applications are becoming more integrated into our daily lives, the importance of Speech Emotion Recognition (SER) has increased significantly. Promoting research with innovative approaches in SER, the Odyssey 2024 Speech Emotion Recognition Challenge was organized as part of the Odyssey 2024 Speaker and Language Recognition Workshop. In this paper we describe the Double Multi-Head Attention Multimodal System developed for this challenge. Pre-trained self-supervised models were used to extract informative acoustic and text features. An early fusion strategy was adopted, where a Multi-Head Attention layer transforms these mixed features into complementary contextualized representations. A second attention mechanism is then applied to pool these representations into an utterance-level vector. Our proposed system achieved the third position in the categorical task ranking with a 34.41% Macro-F1 score, where 31 teams participated in total.