 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy-Preserving Distributed Learning Framework for 6G Telecom Ecosystems
Aug 17, 2020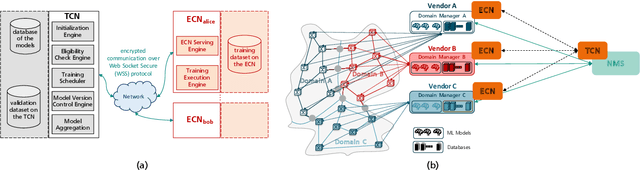
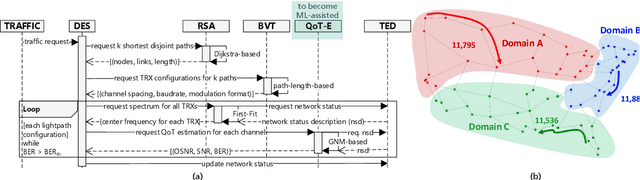
We present a privacy-preserving distributed learning framework for telecom ecosystems in the 6G-era that enables the vision of shared ownership and governance of ML models, while protecting the privacy of the data owners. We demonstrate its benefits by applying it to the use-case of Quality of Transmission (QoT) estimation in multi-domain multi-vendor optical networks, where no data of individual domains is shared with the network management system (NMS).
Self-attention encoding and pooling for speaker recognition
Aug 03, 2020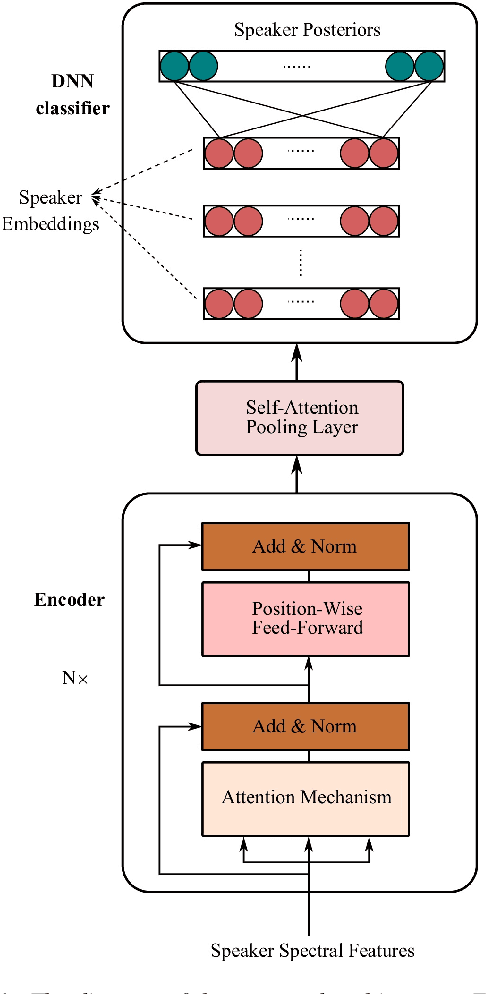
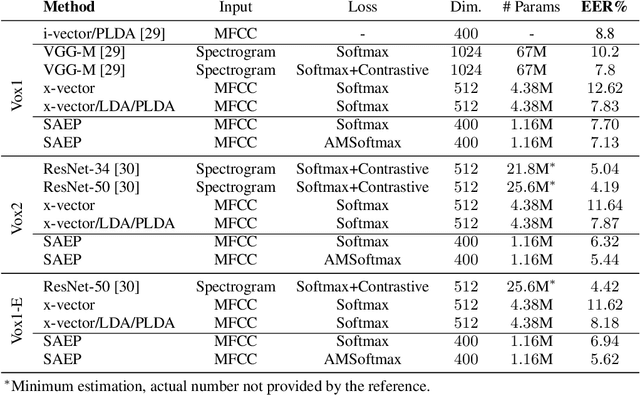
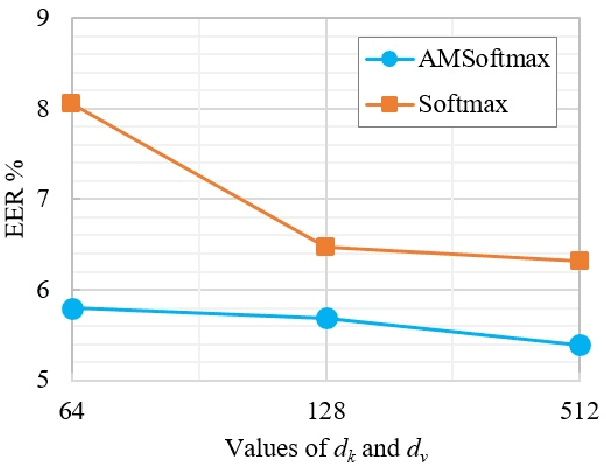
The computing power of mobile devices limits the end-user applications in terms of storage size, processing, memory and energy consumption. These limitations motivate researchers for the design of more efficient deep models. On the other hand, self-attention networks based on Transformer architecture have attracted remarkable interests due to their high parallelization capabilities and strong performance on a variety of Natural Language Processing (NLP) applications. Inspired by the Transformer, we propose a tandem Self-Attention Encoding and Pooling (SAEP) mechanism to obtain a discriminative speaker embedding given non-fixed length speech utterances. SAEP is a stack of identical blocks solely relied on self-attention and position-wise feed-forward networks to create vector representation of speakers. This approach encodes short-term speaker spectral features into speaker embeddings to be used in text-independent speaker verification. We have evaluated this approach on both VoxCeleb1 & 2 datasets. The proposed architecture is able to outperform the baseline x-vector, and shows competitive performance to some other benchmarks based on convolutions, with a significant reduction in model size. It employs 94%, 95%, and 73% less parameters compared to ResNet-34, ResNet-50, and x-vector, respectively. This indicates that the proposed fully attention based architecture is more efficient in extracting time-invariant features from speaker utterances.
Self Multi-Head Attention for Speaker Recognition
Jul 01, 2019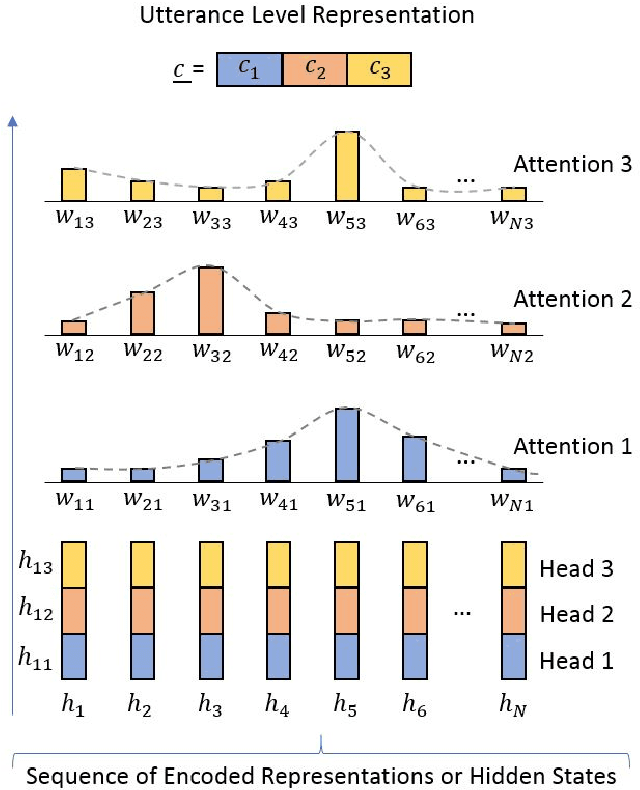
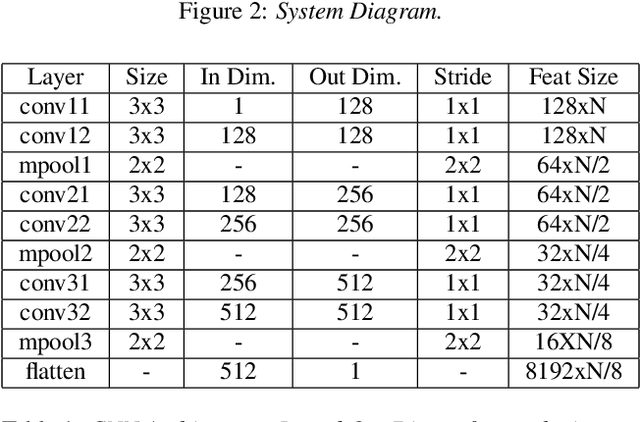
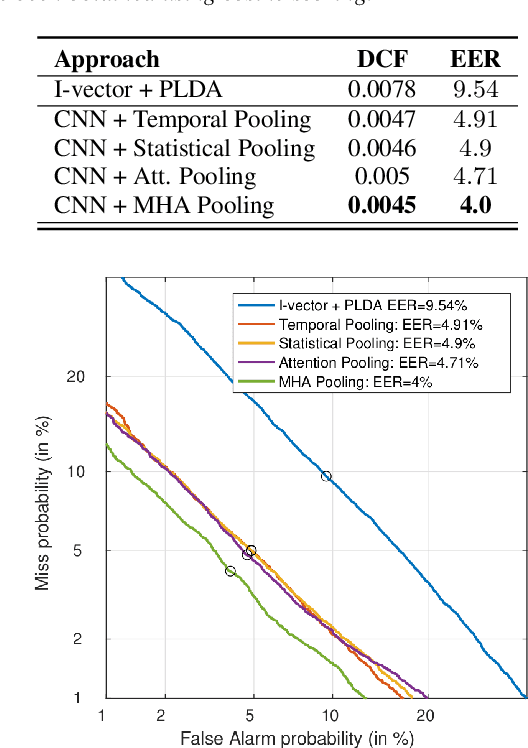
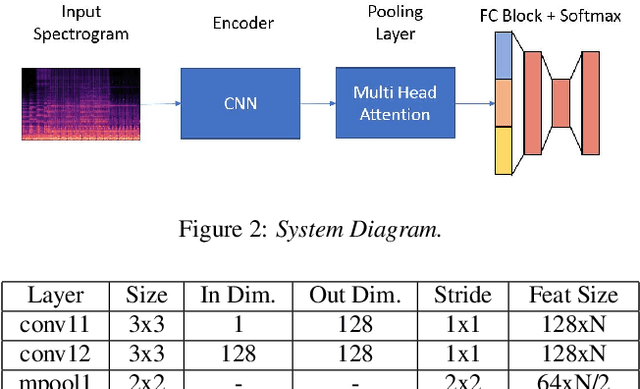
Most state-of-the-art Deep Learning (DL) approaches for speaker recognition work on a short utterance level. Given the speech signal, these algorithms extract a sequence of speaker embeddings from short segments and those are averaged to obtain an utterance level speaker representation. In this work we propose the use of an attention mechanism to obtain a discriminative speaker embedding given non fixed length speech utterances. Our system is based on a Convolutional Neural Network (CNN) that encodes short-term speaker features from the spectrogram and a self multi-head attention model that maps these representations into a long-term speaker embedding. The attention model that we propose produces multiple alignments from different subsegments of the CNN encoded states over the sequence. Hence this mechanism works as a pooling layer which decides the most discriminative features over the sequence to obtain an utterance level representation. We have tested this approach for the verification task for the VoxCeleb1 dataset. The results show that self multi-head attention outperforms both temporal and statistical pooling methods with a 18\% of relative EER. Obtained results show a 58\% relative improvement in EER compared to i-vector+PLDA.
Towards Recognizing Phrase Translation Processes: Experiments on English-French
Apr 27, 2019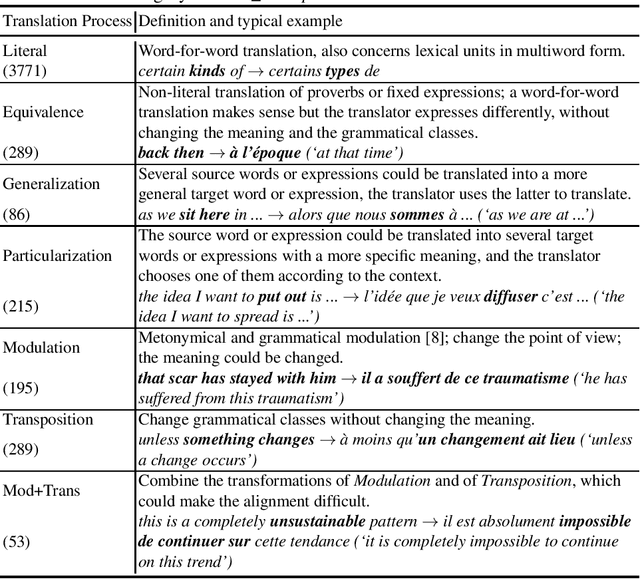
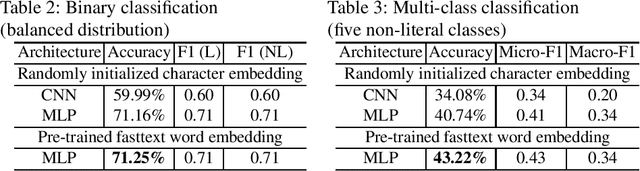
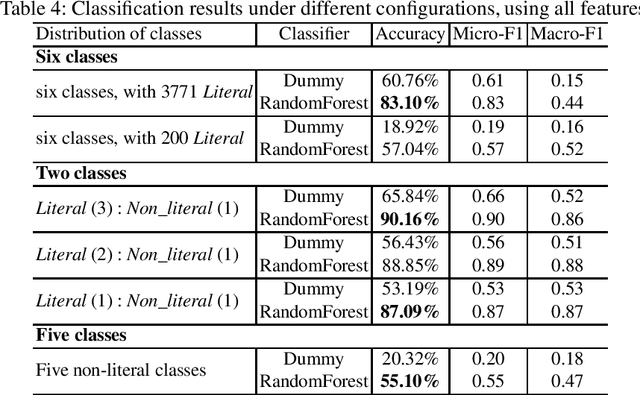

When translating phrases (words or group of words), human translators, consciously or not, resort to different translation processes apart from the literal translation, such as Idiom Equivalence, Generalization, Particularization, Semantic Modulation, etc. Translators and linguists (such as Vinay and Darbelnet, Newmark, etc.) have proposed several typologies to characterize the different translation processes. However, to the best of our knowledge, there has not been effort to automatically classify these fine-grained translation processes. Recently, an English-French parallel corpus of TED Talks has been manually annotated with translation process categories, along with established annotation guidelines. Based on these annotated examples, we propose an automatic classification of translation processes at subsentential level. Experimental results show that we can distinguish non-literal translation from literal translation with an accuracy of 87.09%, and 55.20% for classifying among five non-literal translation processes. This work demonstrates that it is possible to automatically classify translation processes. Even with a small amount of annotated examples, our experiments show the directions that we can follow in future work. One of our long term objectives is leveraging this automatic classification to better control paraphrase extraction from bilingual parallel corpora.